- 「分散分析」と聞くと拒否反応が出る。教科書を開くと数式だらけで何の話かわからない
- "平均の差"を調べたいのに、なぜ"分散"を計算するのか意味がわからない
- 「一元配置」「平方和」「自由度」「F検定」と用語が次々出てきて、つながりが見えない
- QC検定の勉強で分散分析が出てきたが、いきなり計算問題から入って挫折した
- 分散分析が「3つ以上の平均を比較する道具」だと一発で理解できる
- なぜ"分散"を使うのか、その直感が身近な例で腑に落ちる
- これから自分が何の計算をするのか、計算全体の地図が頭に入る
- 「なぜF検定で判定していいのか」という理論的な裏付けまでスッキリわかる
分散分析(ANOVA)とは、3つ以上のグループの「平均に差があるか」を、データの"バラつき(分散)"を使って判定する統計手法です。
なぜ平均を比べるのに分散を見るのか?
答えは「グループ間のバラつき」が「グループ内のバラつき」より明らかに大きければ、それは偶然ではなく"本当に平均が違う証拠"だと言えるからです。
この「バラつき同士の比較」を数値化するのが F値 であり、その比較が成立する理由が 平均平方の期待値 E(V) という考え方です。
目次
そもそも、なぜ"分散分析"が必要なのか?
まず、分散分析が「何のために生まれた道具なのか」から押さえましょう。ここを飛ばすと、後の計算が全部「呪文」になります。
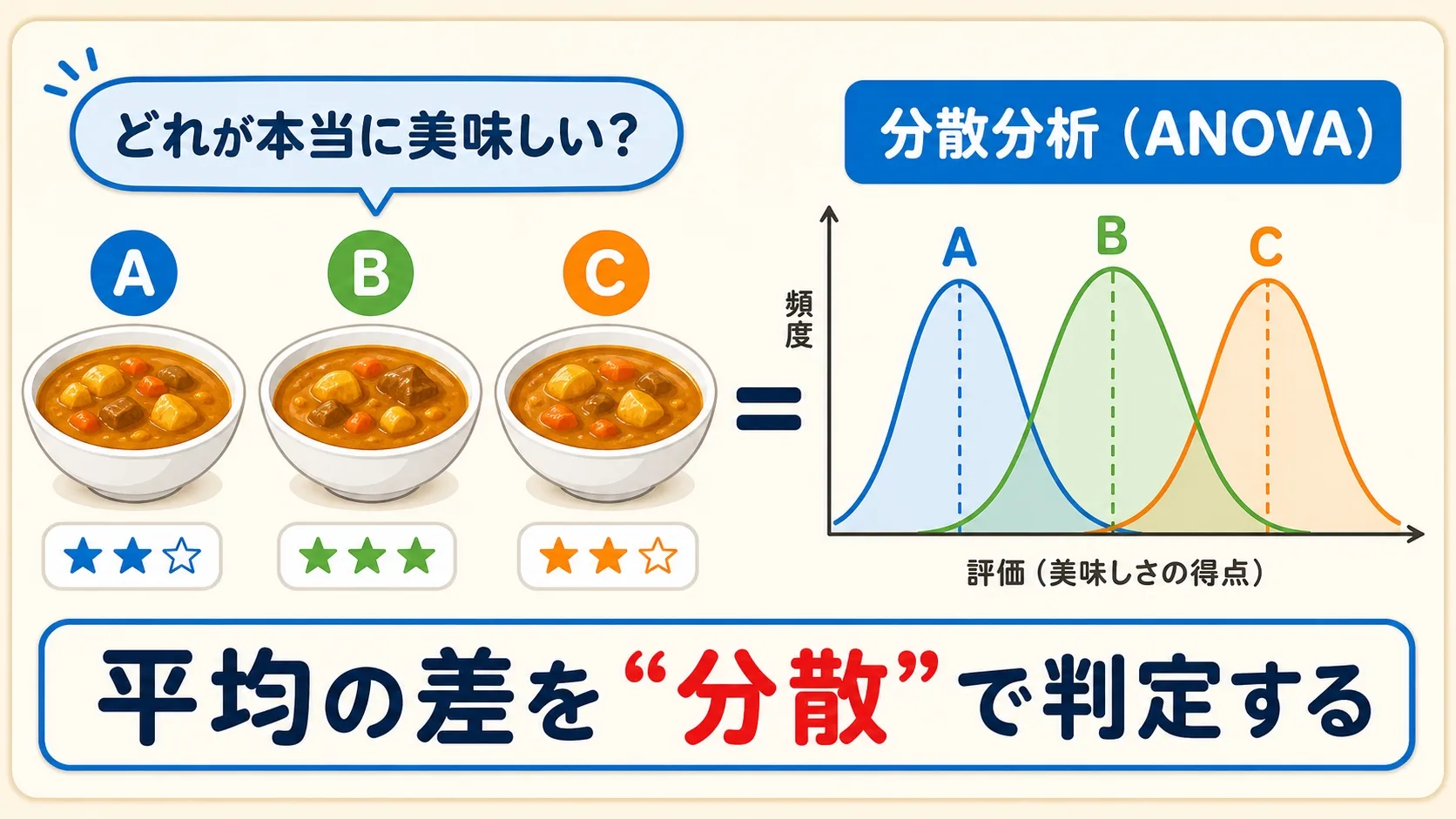
シチュエーション:3つのカレー、どれが一番おいしい?
あなたが食品メーカーの開発担当者だとします。3種類のスパイス配合(A, B, C)でカレーを試作し、それぞれ5人に試食してもらって10点満点で点数をつけてもらいました。
| 配合A | 配合B | 配合C |
|---|---|---|
| 6, 7, 5, 6, 6 | 8, 7, 9, 8, 8 | 7, 6, 8, 7, 7 |
| 平均 6.0 | 平均 8.0 | 平均 7.0 |
さて、ここで知りたいのは「この3つの配合は、本当に味(評価)に差があるのか?」です。
パッと見るとBが一番高そうですが、5人しか試していません。「たまたまB好きの人が集まっただけ」かもしれないのです。
「t検定を3回やればいい」が間違いである理由
2つのグループの平均を比べるならt検定を使います。だったら「A対B」「B対C」「A対C」と3回やればよさそうに思えますよね。
しかし、これは絶対にやってはいけません。
検定を1回やるごとに「本当は差がないのに、差があると間違える確率(第1種の過誤)」が5%発生します。
これを3回繰り返すと、間違える確率は約14%まで膨れ上がるのです(1 − 0.95³ ≒ 0.143)。
つまり「本当は差がないのに、差があると勘違いする」リスクが約3倍。これでは検定の意味がありません。
3つ以上の平均を、たった1回の検定で「どこかに差があるかどうか」を判定できる魔法の道具。それが分散分析(ANOVA:Analysis of Variance)です。
分散分析とは何か|"平均の差"を"分散"で見る不思議
ここが分散分析を学ぶ上で最大の山場です。多くの初心者がここでつまずきます。
「平均を比べたいのに、なぜ"分散"を計算するの?」という素朴な疑問。これを身近な例で完全に解消します。
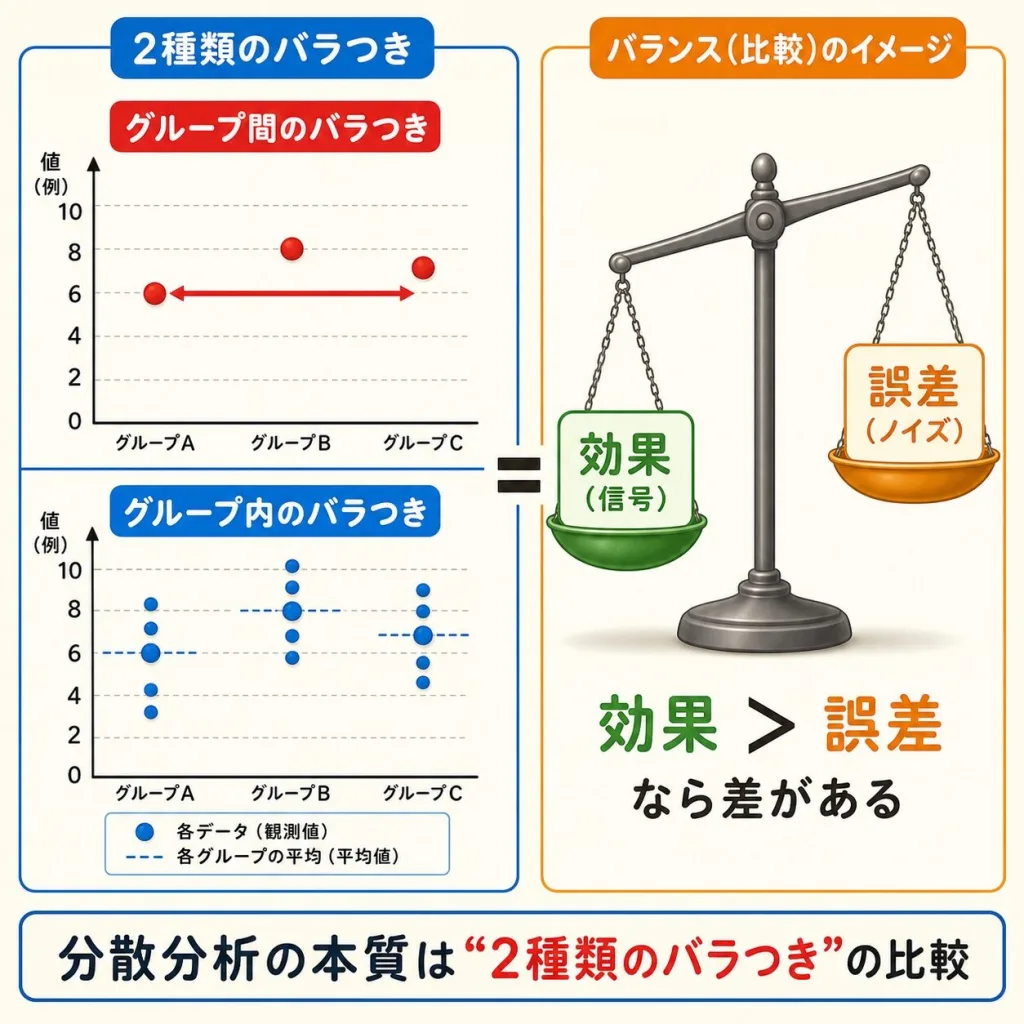
キーワードは「2種類のバラつき」
データには、必ず2種類のバラつきが存在します。これを区別できるようになれば、分散分析の8割は理解できたも同然です。
①グループ間のバラつき
配合Aの平均6点・Bの平均8点・Cの平均7点。
この「グループの平均同士のズレ」がグループ間のバラつき。
→ 因子(配合の違い)の効果
②グループ内のバラつき
配合Aだけ見ても、5人の点数は6, 7, 5, 6, 6とバラついている。
同じ配合なのにズレるのは、個人の好み・気分など。
→ 偶然の誤差
分散分析の超シンプルなロジック
もし「グループ間のバラつき」が「グループ内のバラつき」より明らかに大きいなら
→「配合の違いが、個人差では説明できないほど効いている」
→ 平均に差がある!と判定できる。
逆に、グループ間のズレが、グループ内の個人差と同じ程度しかなければ、「たまたまの誤差の範囲内」と判定します。
この「2つのバラつきの大きさを比べる」のが、分散分析の核心です。
「バラつき」を数値化したのが「分散」
バラつきを「目で見て大きい/小さい」と判断するのではなく、数値で客観的に比較するために使うのが 分散 です。
分散とは、平たく言えば「平均からのズレを2乗して平均したもの」。バラつきが大きいほど大きな値になります。
分散分析という名前は「分散を使って分析する」という意味です。
「平均の差を検定したいのに分散を見る」のではなく、「2種類のバラつきの比較によって、平均の差を判定する」のが本質。
名前で混乱しないでください。「分散を分析する」のではなく「分散で(平均の差を)分析する」のです。
分散と標準偏差|「バラつき」を数値化する魔法の公式 →

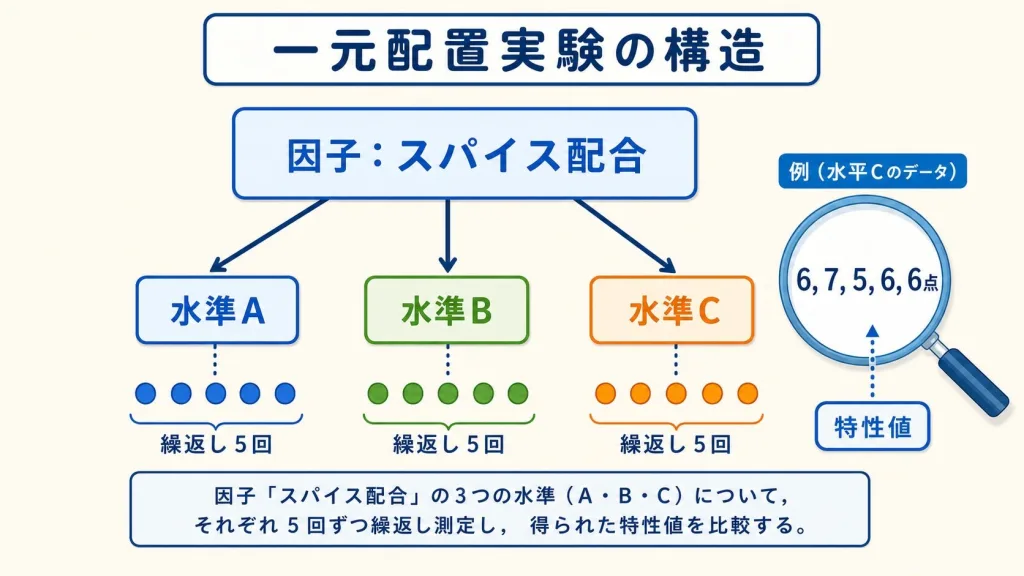
一元配置実験とは|1つの因子で白黒つける
分散分析にはいくつかの「型」があります。その中でも一番シンプルで、最初に学ぶべきなのが一元配置(いちげんはいち)実験です。
「一元配置」の意味を分解する
「一元」 = 1つの因子だけを変化させる
「配置」 = その因子の水準(値)を配置して実験する
つまり一元配置実験とは、「結果に影響しそうな要因(因子)を1つだけ取り上げて、その水準を変えながら実験する」方法です。
「因子」と「水準」を3秒で覚える
| 用語 | 意味 | カレーの例 |
|---|---|---|
| 因子 | 結果に影響を与える要因 | スパイス配合 |
| 水準 | 因子の具体的な値・種類 | A・B・C(3水準) |
| 特性値 | 測定する結果 | 試食評価点 |
実験計画のイメージ図
因子:スパイス配合(3水準) × 各水準5回の繰り返し
一元配置実験を使う場面の見極め方
結果に影響する要因を考えたとき、「明らかにこれだろう」という主犯格が1つに絞れる場合は一元配置でOK。
「温度と時間、両方が効きそう」など、影響しそうな因子が2つ以上ある場合は、一元配置では不十分。二元配置や直交表を使います。
「水準が3つだから一元配置」ではありません。
因子(要因の種類)が1つなら、水準がいくつあっても一元配置です。配合A・B・Cの3種類でも、A〜Eの5種類でも、因子が「配合」1つなら一元配置です。
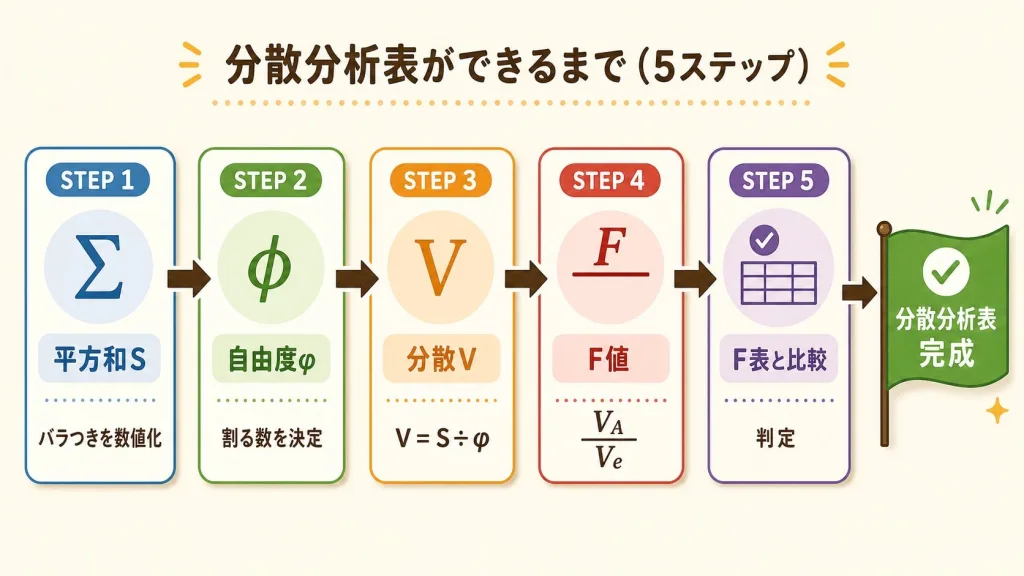
計算の全体像|これから何をするのか俯瞰する
分散分析でつまずく最大の理由は、「今、何のために何を計算しているのか分からなくなる」こと。
ここで全体の地図を頭に入れておきましょう。この地図さえあれば、もう迷子になりません。
ゴールは「分散分析表」を完成させること
分散分析の計算は、最終的に下のような分散分析表(ANOVA表)を完成させることがゴールです。
| 要因 | 平方和 S | 自由度 φ | 分散 V | F値 |
|---|---|---|---|---|
| 群間(A) | SA | φA | VA | F₀ |
| 群内(誤差e) | Se | φe | Ve | — |
| 全体(T) | ST | φT | — | — |
「うわっ、記号だらけ……」と思いましたよね。でも安心してください。やることは「左から右へ、順番に計算していくだけ」。1つずつ見ていきます。
計算の5ステップ|これだけ覚えればOK
平方和(S)を計算する
「バラつきの合計」を数値化します。全体(ST)、群間(SA)、群内(Se)の3種類。
→ 「平均からのズレを2乗して合計」しただけ。
自由度(φ)を計算する
平方和を「平均」するために必要な"割る数"。データ数や水準数からシンプルな引き算で出ます。
分散(V)を計算する
V = S ÷ φ。平方和を自由度で割るだけ。これが「ならした1個あたりのバラつき」になります。
F値を計算する
F₀ = VA ÷ Ve。「群間のバラつき」÷「群内のバラつき」。
これが大きければ「平均に差がある」候補です。
F表と比較して判定する
F₀ が F表(巻末付録)の境界値より大きければ「有意差あり」と判定します。
分散分析の核心|「バラつきの分解」
実は、ここまでの計算には1つの美しい考え方が隠れています。
それが「全体のバラつき=群間のバラつき+群内のバラつき」という分解です。
ST = SA + Se
(全体のバラつき = 群間のバラつき + 群内のバラつき)
全体のバラつきを「因子による効果」と「偶然の誤差」の2つに切り分ける。これが分散分析の核心です。
そしてF値は「効果のバラつき/誤差のバラつき」。つまり「信号の大きさ/ノイズの大きさ」のS/N比のような指標なのです。
分散分析は、「バラつきを2つに分解 → それぞれの分散を計算 → 比をとる(F値)→ F表と比べる」という一連の流れ。
どの計算もこの地図のどこかに必ず位置しています。迷ったらここに戻ってきてください。
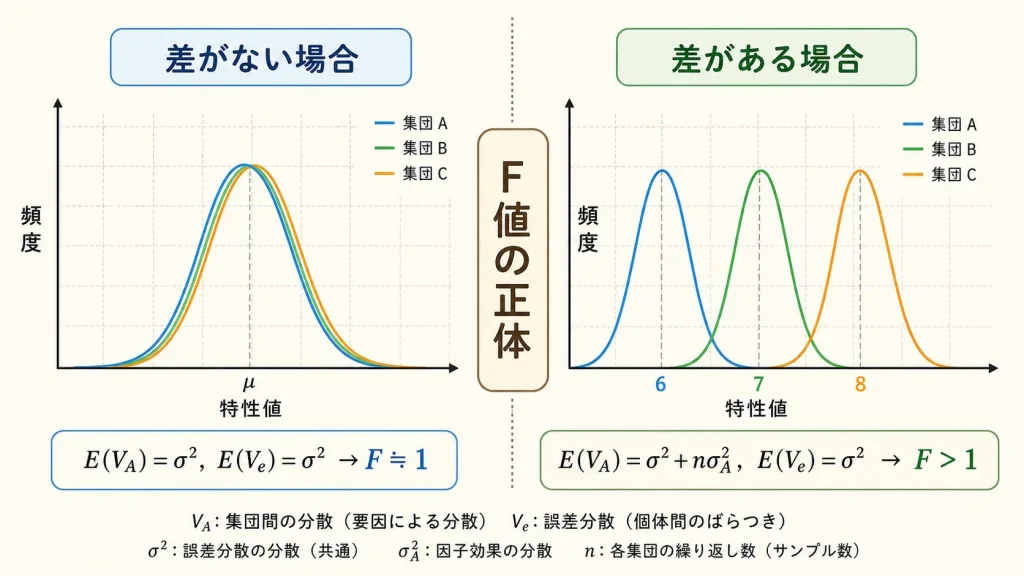
なぜF検定で判定できるのか|E(V)が語る理論的な裏付け
最後に、QC検定1級受験者向けに少しだけ理論的な話をします。難しそうに聞こえますが、ここを理解すると「なぜF値を計算すれば平均の差がわかるのか」がスッキリ腑に落ちます。
キーワードは「平均平方の期待値 E(V)」です。
期待値 E( ) とは何か
E( ) は 期待値(Expectation) の略。
「もし同じ実験を何度も何度も繰り返したら、平均してどんな値になるか」を表します。
今回の1回限りのデータではなく、"理論的に何度もやったらこうなる"という長期的な平均のことです。
E(VA) と E(Ve) の式が、すべてを語る
一元配置実験では、群間分散 VA と群内分散 Ve の期待値が、それぞれ次のような形になることが理論的に証明されています。
E(Ve) = σ² (誤差分散の真の値)
E(VA) = σ² + n × σA² (誤差分散+因子の効果)
記号が多くて怖く見えますが、言っていることは1つだけです。順に読み解きましょう。
この式が意味すること(超重要)
もし差がないなら(σA² = 0)
E(VA) = σ²
E(Ve) = σ²
→ VA と Ve は同じくらいの値になる
→ F = VA/Ve ≒ 1
もし差があるなら(σA² > 0)
E(VA) = σ² + n × σA²
E(Ve) = σ²
→ VA の方が大きくなる
→ F = VA/Ve > 1
F値(VA ÷ Ve)は、
・差がないなら 1に近い値
・差があるなら 1より大きい値
になる。だから「F値が十分に大きいか」を見れば、平均に差があるかどうかを判定できる──これが分散分析の理論的な裏付けです。
なぜ「分散の比」が役に立つのか
もう1つ重要なポイントがあります。
Ve(誤差分散)は、差がある場合もない場合も σ² のまま変わらないことに注目してください。
つまり Ve は「ものさし」として常に一定。そこに VA が「ものさし何個分か」を比べているわけです。
身長の差を測るとき、「メートル」という共通のものさしがあるから比較できますよね。
分散分析では Ve(誤差分散)が"統計のものさし"になり、VA がそのものさし何個分なのかを見て差を判定しているのです。
F検定の判定ルール
| F値の大きさ | 解釈 | 判定 |
|---|---|---|
| F₀ ≒ 1 | 群間も群内も同じくらいバラついている | 差なし |
| F₀ > F表の値 | 群間のバラつきが偶然では説明できないほど大きい | 有意差あり |

初心者が陥りやすい3つの落とし穴
分散分析を学ぶときに、多くの人がつまずくポイントを3つだけ先に潰しておきます。
落とし穴①|「分散を分析する」と勘違いする
「分散分析だから、分散の大きさ自体を調べる手法だ」
「分散を"道具に使って"、平均の差を判定する手法」が正解。バラつきを分解して比較するのが目的。
落とし穴②|「F値が大きい=確実に差がある」と思い込む
「F値が3.0出た!絶対に差があるはずだ!」
F値そのものではなく、F表の境界値(自由度で決まる)と比較する。同じF=3.0でも、自由度によって「有意」にも「有意でない」にもなる。
落とし穴③|「どの水準が他と違うのか」までわかると思う
「分散分析で有意差が出たから、配合Bが一番良い!」
分散分析でわかるのは「どこかに差があるか」だけ。「A対B」「B対C」など、どの組み合わせに差があるかは、多重比較法(テューキー法など)という別の手順で調べる。
よくある質問(FAQ)
Q1. 分散分析とt検定はどう違うのですか?
t検定は2つのグループの平均を比較する手法、分散分析は3つ以上のグループの平均を比較する手法です。2グループだけなら分散分析でもt検定でも結果は一致しますが、3グループ以上ではt検定の繰り返しはNG(誤判定率が膨らむ)なので、分散分析を使います。
Q2. ANOVAって何の略ですか?
Analysis of Variance(分散の分析)の頭文字を取ったものです。読み方は「アノーヴァ」または「アノバ」。分散分析の英語表記なので、海外の論文や統計ソフトでは ANOVA と表記されます。
Q3. 一元配置と二元配置の違いは何ですか?
扱う因子の数が違います。一元配置は因子が1つ(例:配合のみ)、二元配置は因子が2つ(例:配合×加熱温度)。実務では「複数の要因が絡む」ことが多いので二元配置以上がよく使われますが、まずは一元配置で土台を作るのが最短ルートです。
Q4. F値が1より小さくなったら何かおかしいですか?
おかしくありません。F値が1未満ということは「群間のバラつきが、群内のバラつきよりも小さい」状態。これは 因子の効果がほぼゼロであることを示し、もちろん「有意差なし」と判定されます。実験データでは普通に起こり得ます。
Q5. QC検定では何級から分散分析が出ますか?
QC検定2級から、一元配置・二元配置の分散分析が本格的に出題されます。3級では「分散分析の概念」を問われる程度。1級では繰返しのある二元配置や直交表の解析まで必須です。本記事の内容は2級対策の土台として最低限押さえておきたいレベルです。

{kind=link}
まとめ|分散分析を一言で言えるようになろう
- 分散分析は 3つ以上の平均を1回の検定で比較するための手法
- "分散"を見るのは 「グループ間バラつき vs グループ内バラつき」を比較するため
- 一元配置実験は 1つの因子だけを変える、最もシンプルな実験設計
- 計算の地図:平方和 S → 自由度 φ → 分散 V → F値 → F表で判定
- F検定の理論的根拠は E(VA) = σ² + nσA²、E(Ve) = σ²。差があれば VA だけが大きくなる
- F値が大きい=信号(効果)がノイズ(誤差)より大きい、ということ
「分散分析って何?」と聞かれたら、こう答えられればOK。
「3つ以上のグループの平均に差があるかを、"グループ間のバラつき"と"グループ内のバラつき"を比べることで判定する手法です」
ここまでで「分散分析の概念」は完全に理解できました。
次は 「実際に手を動かして計算してみる」 ステップに進みましょう。具体的な数値で平方和や自由度を計算すれば、もっと深く理解できます。
📚 次に読むべき記事
実験計画法全体のロードマップ。今あなたが分散分析のどの位置にいるかを俯瞰できる体系図です。
概念を理解したら、次は実際に分散分析表を作る計算実践編。途中式を一切省かず、手を動かして覚えられます。
一元配置の次のステップ。「2つの因子が結果にどう影響するか」を同時に調べる方法。実務で最も使える分散分析です。