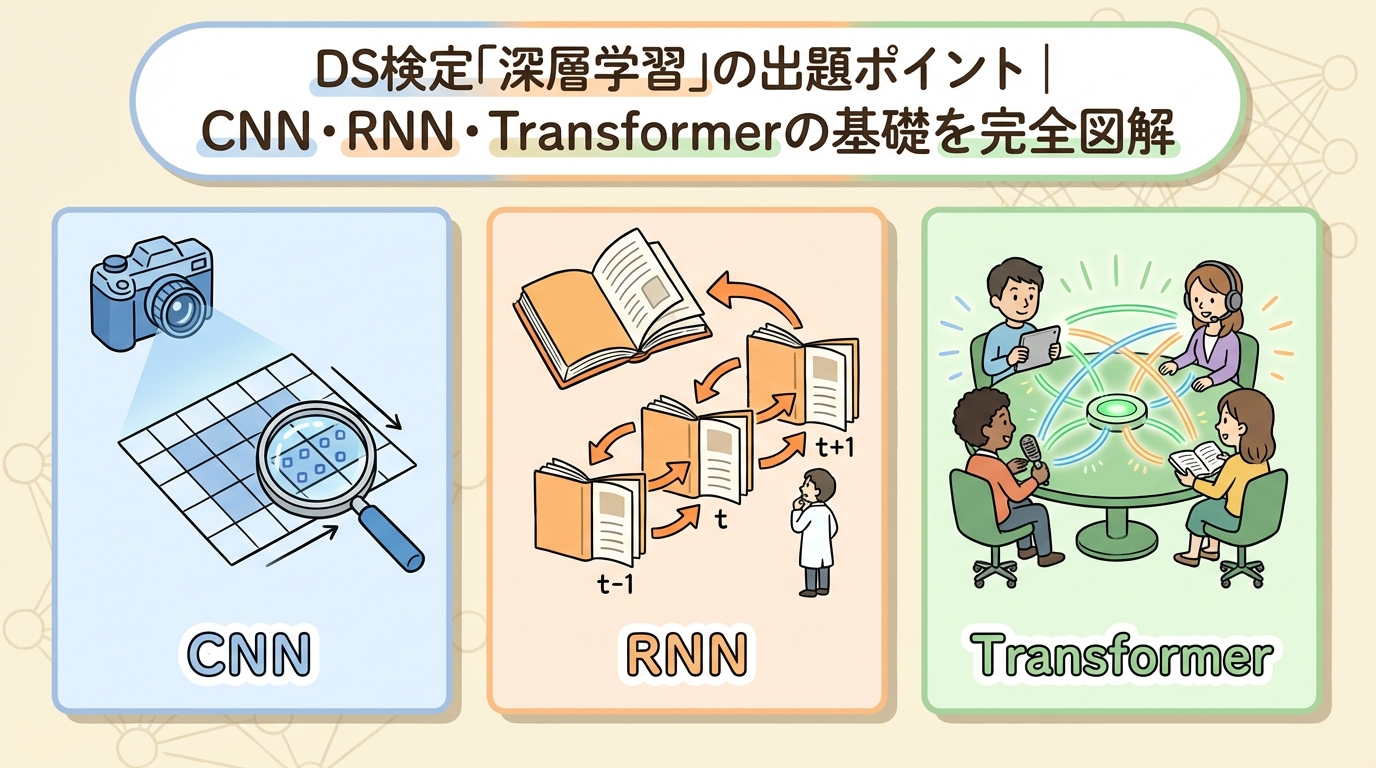
- 「ニューラルネットワーク」と「ディープラーニング」の違いがわからない
- CNN・RNN・Transformerの名前は聞くけど、何がどう違うのか説明できない
- 「誤差逆伝播」「活性化関数」「勾配消失」…用語が多すぎて頭が混乱する
- ChatGPTやStable DiffusionでAIは身近になったのに、仕組みがさっぱりわからない
- DS検定の深層学習パートで何が出るのか、どこまで覚えればいいのか見当がつかない
- ニューラルネットワークの基本構造(入力層・隠れ層・出力層)
- 活性化関数・誤差逆伝播法・勾配降下法の「なぜ必要か」
- CNN(画像認識)の仕組み:畳み込み・プーリングのイメージ
- RNN / LSTM(時系列・自然言語)の仕組み:記憶のメカニズム
- Transformer / Self-Attentionの革新:なぜChatGPTが可能になったのか
- 転移学習・ファインチューニングの概念
- DS検定で問われるポイントの総整理
深層学習(ディープラーニング)は、DS検定の「データサイエンス力」カテゴリの中でも特に出題されやすいテーマです。スキルチェックリストでは★(見習いレベル)で「CNN、RNN/LSTMなどの深層学習の主要方式の特徴を理解し、目的に応じて選択できる」ことが求められています。
しかし、数式から入ると挫折します。この記事では「たとえ話」と「図解」でイメージを先に掴み、DS検定で問われるレベルの知識を最短で身につけることを目標にしています。前回の機械学習基礎の記事を読んだ方は、そのまま読み進めてください。
DS検定で問われる機械学習の基礎|教師あり/なし・過学習・評価指標を完全図解 →
目次
- 深層学習(ディープラーニング)とは何か?
- ニューラルネットワークの基本構造|入力層・隠れ層・出力層
- 活性化関数|なぜ「非線形」が必要なのか
- 学習の仕組み|誤差逆伝播法と勾配降下法
- 勾配消失問題|深い層の学習が進まなくなる理由
- 深層学習アーキテクチャの全体マップ|CNN・RNN・Transformer
- CNN(畳み込みニューラルネットワーク)|画像を「部分」から理解する
- RNN(再帰型ニューラルネットワーク)|「前の情報を記憶する」ネットワーク
- Transformer|「すべてを同時に見る」革命的アーキテクチャ
- CNN・RNN・Transformer 完全比較表
- 転移学習とファインチューニング|「既に学んだ知識を再利用する」
- その他のDS検定頻出キーワード
- DS検定で問われる深層学習の出題パターン総まとめ
深層学習(ディープラーニング)とは何か?
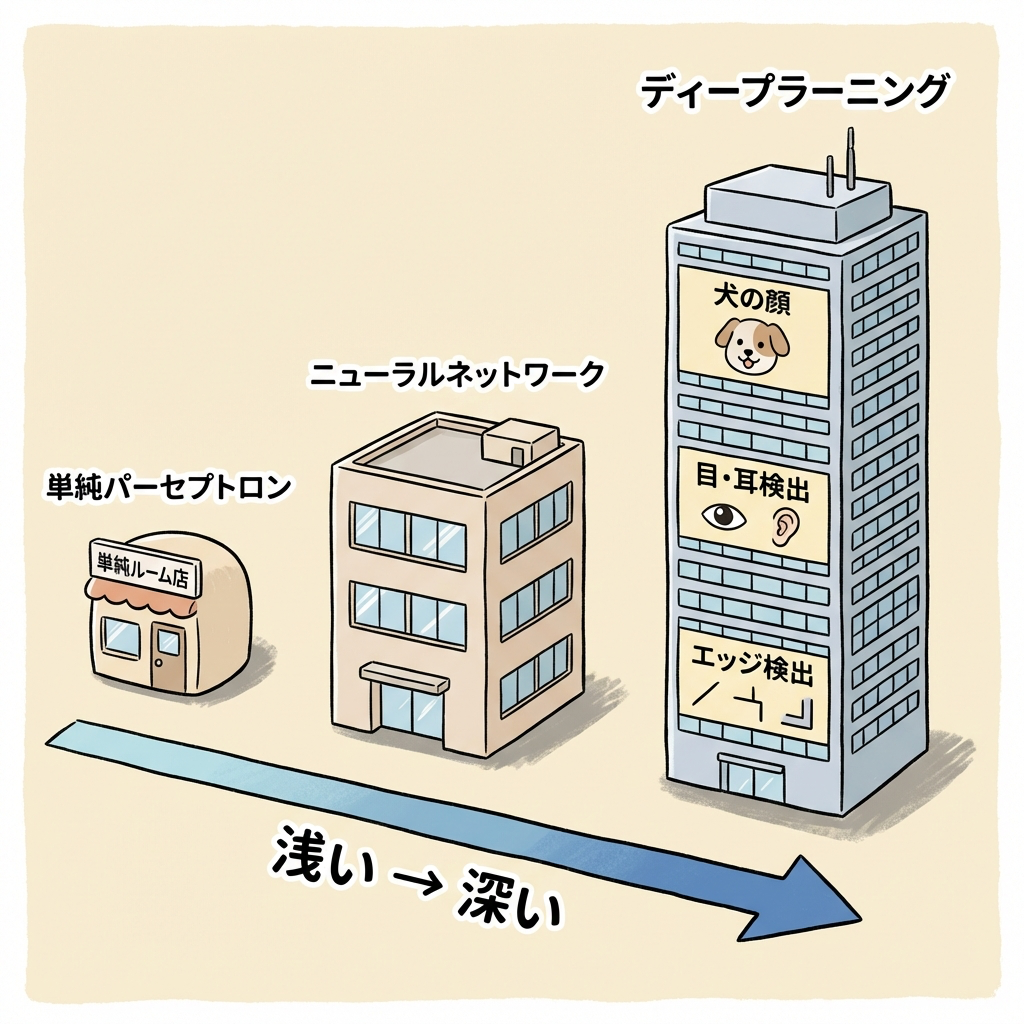
深層学習を理解するには、まずニューラルネットワーク(Neural Network)を知る必要があります。ニューラルネットワークとは、人間の脳の神経細胞(ニューロン)のつながり方を模倣した計算モデルです。そして深層学習とは、ニューラルネットワークの「層」を深く(多く)積み重ねたものです。
ニューラルネットワーク(NN):脳の神経回路を模倣した計算モデルの総称
深層学習(Deep Learning):NNの隠れ層を2層以上に深くしたもの(=ディープニューラルネットワーク)
つまり、深層学習はニューラルネットワークの一種です。「深い」ニューラルネットワーク=ディープラーニングです。
ニューラルネットワークを会社に例えると、1人で全部やる個人事業主が単純なパーセプトロン(1層)。3人の部署がある小さな会社が浅いニューラルネットワーク。そして何十もの部署が階層的に連携する大企業が深層学習です。
層が深いほど、複雑な業務(=複雑なパターン認識)を処理できますが、連携コスト(=計算コスト)も大きくなります。
なぜ「深く」すると性能が上がるのか?
層が浅いネットワークは「単純な特徴」しか捉えられません。一方、層を深くすると、低レベルの特徴を組み合わせて、より高レベルで抽象的な特徴を自動的に学習できるようになります。
「線」「点」「エッジ」などの超単純なパターンを検出
線やエッジを組み合わせて「目」「耳」「鼻」のようなパーツを認識
パーツを組み合わせて「これは犬の顔だ」と高次の概念を理解
この「低レベル→高レベルへ特徴を自動的に組み上げる力」こそが、深層学習が画像認識・音声認識・自然言語処理で革命を起こした理由です。

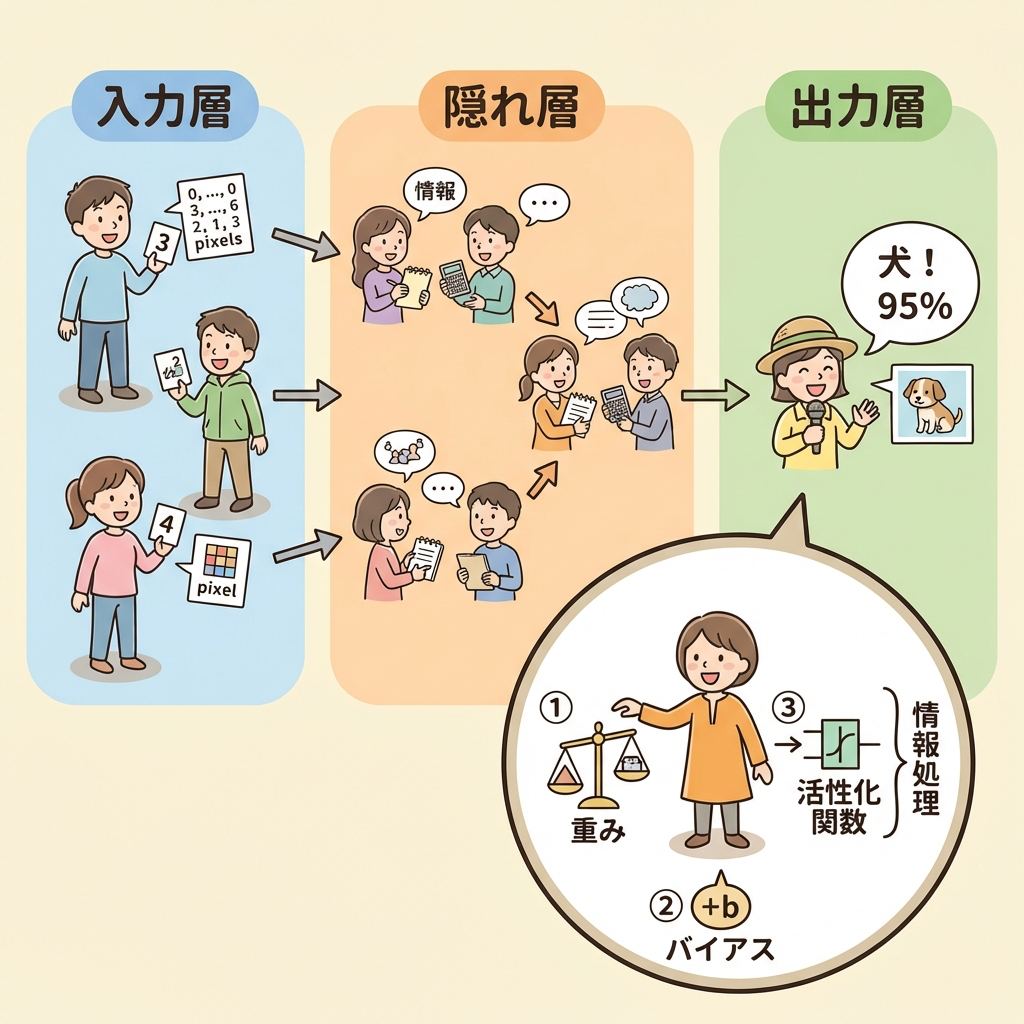
ニューラルネットワークの基本構造|入力層・隠れ層・出力層
すべてのニューラルネットワークは、3種類の層で構成されています。DS検定では「各層の役割」と「層が増えると何が起きるか」が問われます。
ニューラルネットワークは伝言ゲームに似ています。最初の人(入力層)が生の情報を受け取り、中間の人たち(隠れ層)がそれぞれ「自分なりの解釈」を加えて次の人に渡します。最後の人(出力層)が最終的な答えを発表します。
中間の人が多いほど(層が深いほど)情報は様々な角度から加工され、より精度の高い最終回答が得られますが、伝言ミス(勾配消失)のリスクも高まります。
ニューロン1つの動き|「重み付き投票」のイメージ
各ニューロンは以下の3ステップで動作します。
| ステップ | やること | たとえ話 |
|---|---|---|
| ① | 複数の入力に重みをかけて合計する | 「Aさんの意見は信頼度80%、Bさんは20%」と重要度をつけて足し合わせる |
| ② | バイアス(偏り)を加える | 「そもそも自分は慎重派だから-5点してから判断」という性格の補正 |
| ③ | 活性化関数を通す | 「合計スコアがある閾値を超えたら"YES"、超えなければ"NO"」と最終判断する |
この「重み」と「バイアス」がニューラルネットワークが学習するパラメータです。学習とは、予測が正解に近づくように、重みとバイアスを少しずつ調整していく作業のことです。
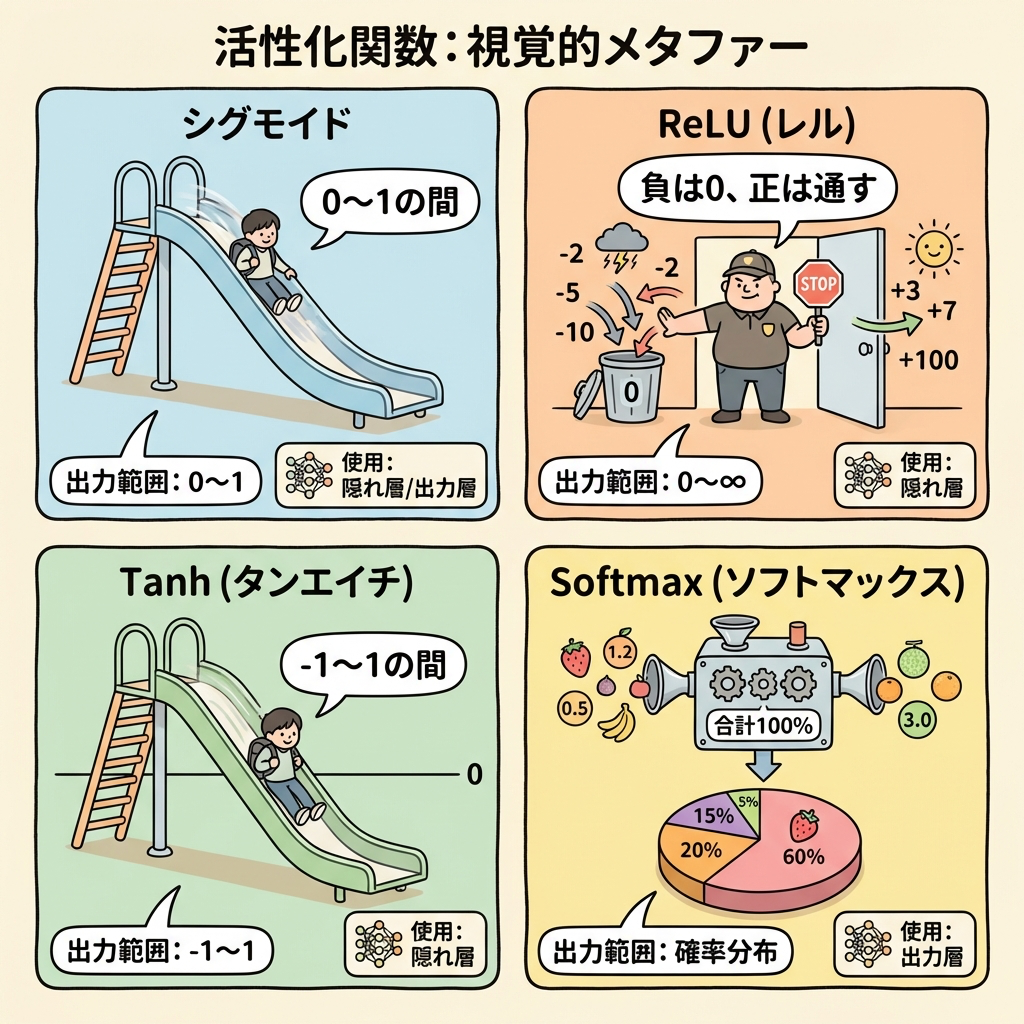
活性化関数|なぜ「非線形」が必要なのか
活性化関数(Activation Function)は、ニューロンの出力に「非線形な変換」を加える関数です。DS検定では「代表的な活性化関数の名前と特徴」「なぜ必要なのか」が問われます。
もし活性化関数がなければ、ニューロンの計算は「重み × 入力 + バイアス」のただの足し算と掛け算(線形変換)の繰り返しです。線形変換をいくら重ねても結局1回の線形変換と同じなので、層を深くする意味がありません。
たとえ話で言うと、色フィルターを何枚重ねても、結局「1枚の混合フィルター」と同じになるようなものです。活性化関数という「ひねり」を加えることで、層を重ねるほど複雑なパターンを表現できるようになります。
DS検定で覚えるべき代表的な活性化関数
| 関数名 | 出力範囲 | 特徴 | 主な用途 |
|---|---|---|---|
| シグモイド | 0〜1 | S字カーブで出力を0〜1に変換。確率として解釈しやすい | 二値分類の出力層 |
| tanh | -1〜1 | シグモイドを-1〜1にスケール。出力の中心が0 | RNNの隠れ層 |
| ReLU ⭐ | 0〜∞ | 入力が0以下→0、0以上→そのまま。計算が速い、勾配消失しにくい | CNN等の隠れ層で最も使われる |
| Softmax | 0〜1(合計1) | 複数の出力をすべて足すと1になる。確率分布に変換 | 多クラス分類の出力層 |
「隠れ層でよく使われる活性化関数は?」→ ReLU
「二値分類の出力層で使われるのは?」→ シグモイド
「多クラス分類の出力層で使われるのは?」→ Softmax
この3パターンは確実に覚えておきましょう。

{kind=link}
学習の仕組み|誤差逆伝播法と勾配降下法
ニューラルネットワークの「学習」とは、予測のズレ(誤差)を小さくするように重みを調整する作業です。このために使われる2つの仕組みを押さえましょう。
① 損失関数|「どれくらいズレているか」を測る
まず、モデルの予測と正解がどれくらいズレているかを数値化する関数が損失関数(Loss Function)です。損失が小さいほど予測が正確です。
| 損失関数 | 用途 | イメージ |
|---|---|---|
| 平均二乗誤差(MSE) | 回帰タスク | 「予測と実際の数値のズレの二乗」の平均 |
| 交差エントロピー | 分類タスク | 「正解ラベルの確率をどれだけ高くできたか」の指標 |
② 勾配降下法|「坂を下って谷底(最小値)を目指す」
損失を最小にする重みを見つけるために使われるのが勾配降下法(Gradient Descent)です。
あなたは目隠しをされて山の中腹に立っています。谷底(=損失が最小の場所)に着きたいのですが、景色が見えません。頼れるのは足元の傾き(=勾配)だけです。
「右足のほうが低い→右に一歩進む」を繰り返すと、やがて谷底にたどり着きます。この「足元の傾きを調べて、傾きが下がる方向に一歩進む」を繰り返すのが勾配降下法です。
一歩の大きさを「学習率(Learning Rate)」と呼びます。大きすぎると谷底を飛び越えてしまい、小さすぎると到着に時間がかかります。
③ 誤差逆伝播法(バックプロパゲーション)|「犯人を辿る」
勾配降下法で重みを更新するには「各重みが損失にどれだけ影響しているか」を知る必要があります。この情報を出力層から入力層に向かって逆方向に伝えるのが誤差逆伝播法です。
完成した料理(出力)がまずかったとします。「なぜまずいのか?」を逆方向にたどります。
「味付け工程が悪い?」→「いや、下ごしらえの塩分が多かった?」→「そもそも素材選びが間違っていた?」
このように、最終結果の「ズレ」を出力層から入力層に向かって各層の「責任の重さ」を計算していくのが誤差逆伝播法です。責任の重さがわかれば、そこの重みを重点的に修正できます。

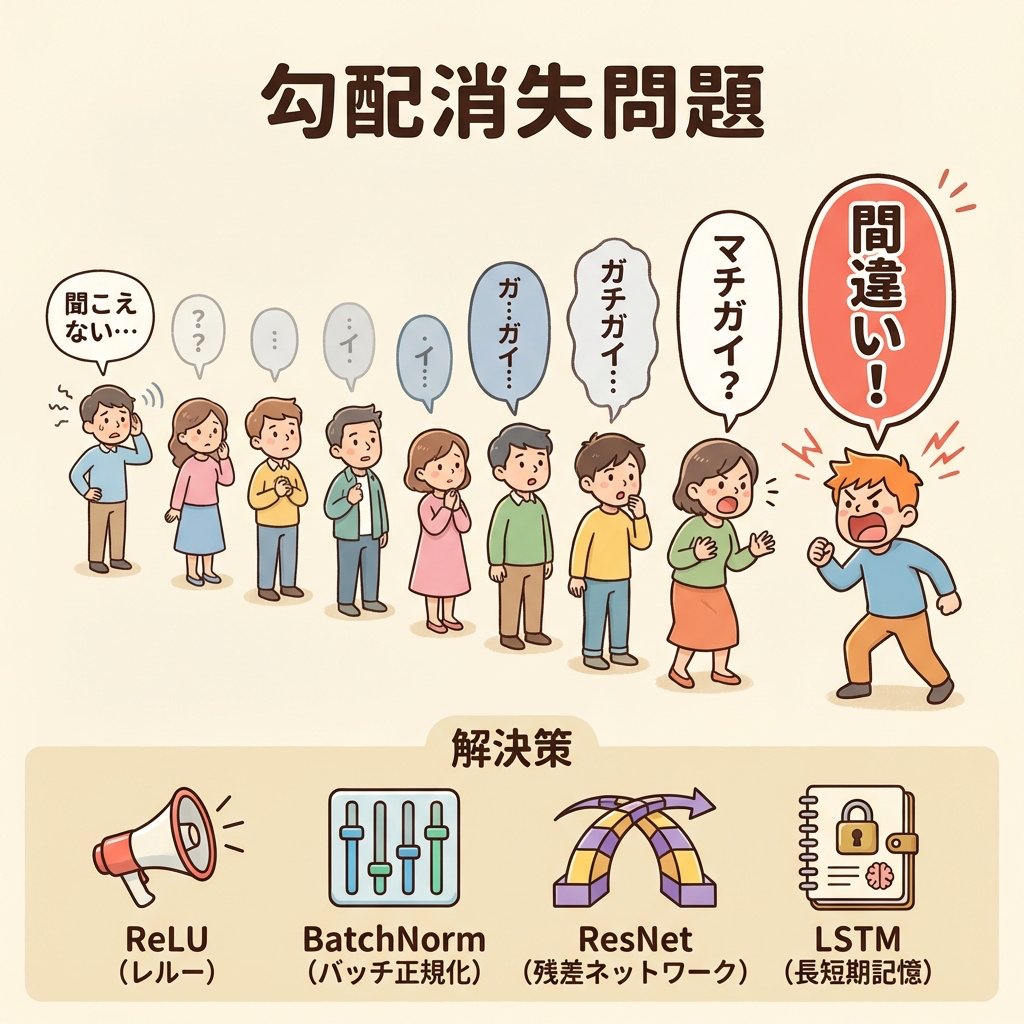
勾配消失問題|深い層の学習が進まなくなる理由
層が深くなると、誤差逆伝播で勾配が伝わる際に勾配がどんどん小さくなって、入力層に近い層がほとんど学習できなくなる現象が起きます。これが勾配消失問題(Vanishing Gradient Problem)です。
10人で伝言ゲームをしているとします。最後の人(出力層)が「答えが違った!」とフィードバックします。しかし声のボリュームが伝わるたびに半分ずつ小さくなるとしたら、最初の人(入力層)にはほぼ聞こえません。
結果、最初の数人は「自分は何を直せばいいのかわからない」となり、学習が止まってしまいます。これが勾配消失です。
勾配消失を解決する主な方法
| 解決策 | どう解決するか |
|---|---|
| ReLU活性化関数 | 正の値の領域で勾配が常に1なので、層が深くても勾配が消えにくい |
| バッチ正規化 | 各層の出力を正規化して、学習を安定させる |
| 残差接続(ResNet) | 入力を数層飛ばして直接つなぐ「ショートカット」を追加し、勾配が途切れないようにする |
| LSTM(後述) | RNNにおける勾配消失を「ゲート機構」で解決 |
「勾配消失問題とは何か?」「ReLUが広く使われる理由は?」「LSTMがRNNの勾配消失を解決する仕組みは?」が定番の問いです。「深い層ほど入力側の勾配が小さくなり学習が進まない」という本質を覚えておけば対応できます。
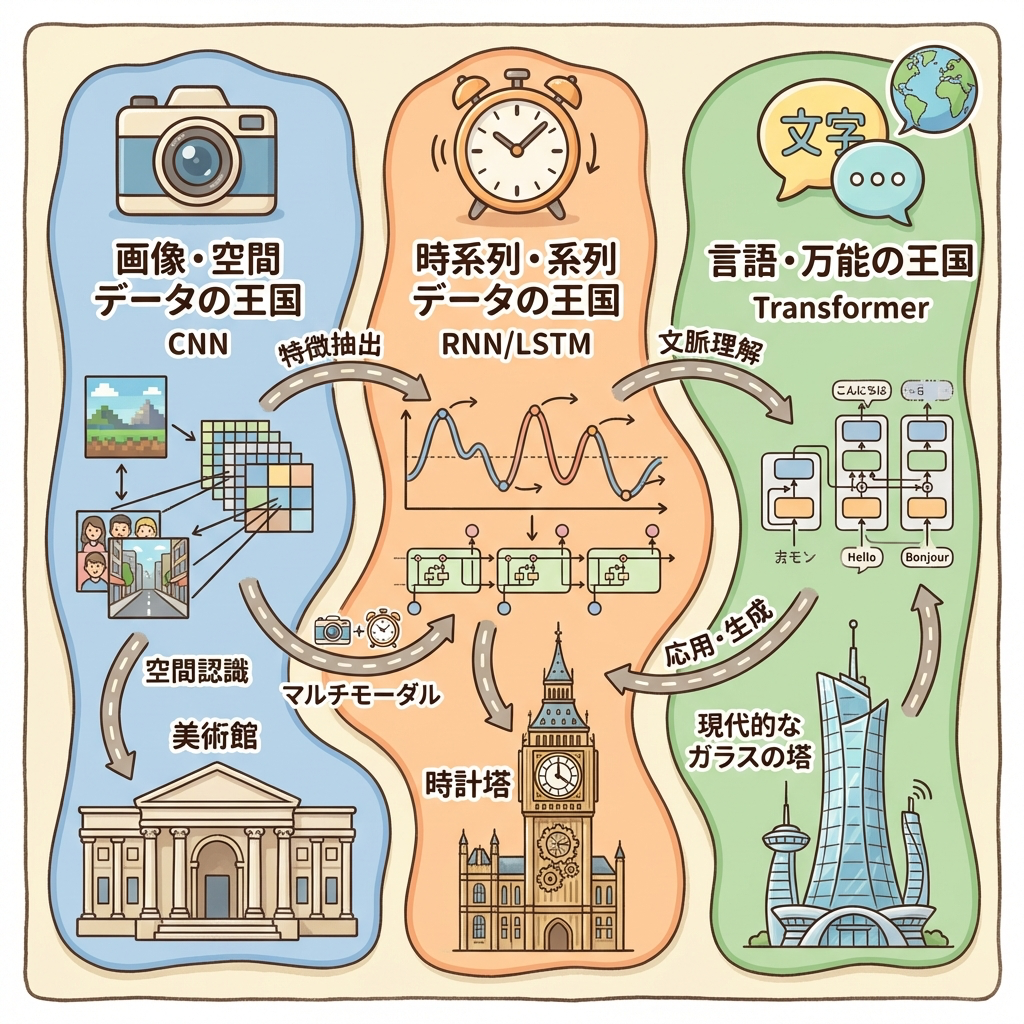
深層学習アーキテクチャの全体マップ|CNN・RNN・Transformer
ここまでで深層学習の「共通の基礎」を押さえました。ここからは、データの種類によって使い分ける3つの代表的なアーキテクチャを詳しく見ていきます。DS検定で最も重要な部分です。
| アーキテクチャ | 得意なデータ | ひとこと特徴 | 代表的な応用 |
|---|---|---|---|
| CNN | 画像・空間データ | 「小さな窓」でスライドしながら局所的な特徴を抽出する | 画像分類、物体検出、顔認識、医療画像診断 |
| RNN / LSTM | 時系列・系列データ | 「前の情報を記憶」しながら順番に処理する | 株価予測、音声認識、機械翻訳(旧世代) |
| Transformer | テキスト・言語(画像にも拡張) | 「すべての単語を同時に」見て関連性を計算する(Self-Attention) | ChatGPT、BERT、画像生成AI、ViT |
CNN
「空間の中の特徴」を捉える
(画像のどこに何がある?)
RNN / LSTM
「時間の中の特徴」を捉える
(前に何が起きた?)
Transformer
「すべての関係性」を捉える
(どの単語とどの単語が関連?)
それぞれを詳しく見ていきましょう。

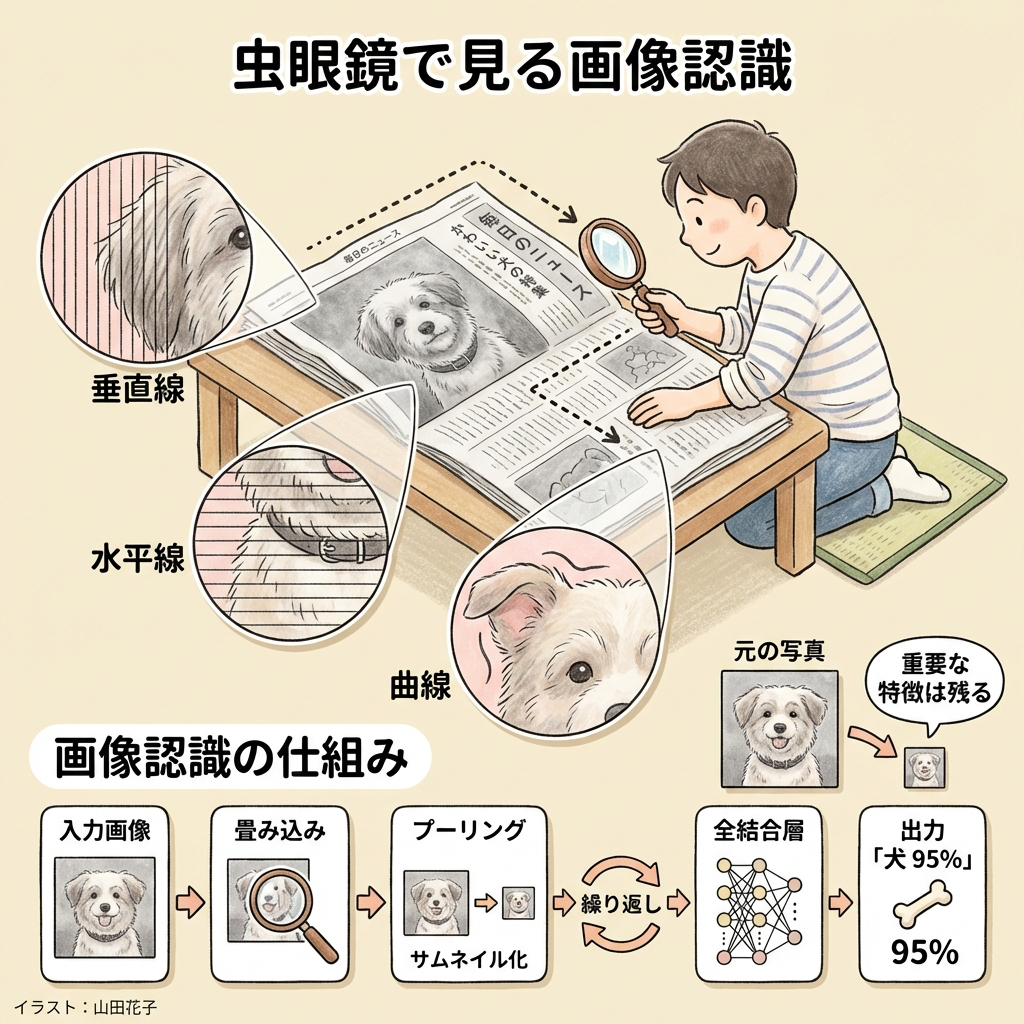
CNN(畳み込みニューラルネットワーク)|画像を「部分」から理解する
CNN(Convolutional Neural Network)は、画像認識で圧倒的な性能を発揮するアーキテクチャです。人間が画像を見るとき、「全体を一度に見る」のではなく「部分的な特徴(エッジ、色、形)を組み合わせて認識する」ように、CNNも画像を局所的に処理します。
CNNの核心:畳み込み(Convolution)とは?
大きな新聞の写真を理解したいとします。全体を一度に見るのは大変なので、小さな虫眼鏡(=フィルター/カーネル)を使って、左上から右下へ少しずつスライドさせながら見ます。
虫眼鏡の形によって見えるものが違います。「縦線を見つける虫眼鏡」「横線を見つける虫眼鏡」「丸い形を見つける虫眼鏡」など、何種類もの虫眼鏡を使い分けることで、画像のさまざまな特徴を抽出します。
この「虫眼鏡を画像の上でスライドさせる操作」が畳み込みです。虫眼鏡の中身(数字の組み合わせ)がフィルター(カーネル)です。
プーリング(Pooling)|情報を圧縮する
畳み込みの後に行われるのがプーリングです。特徴マップを小さくする(ダウンサンプリング)操作で、計算量を減らし、位置のズレに強くなります。
高解像度の写真(4000×3000ピクセル)を、スマホのアルバム一覧用に小さなサムネイル(200×150ピクセル)にするようなものです。細かいディテールは失われますが、「猫の写真か、風景の写真か」はサムネイルでも十分わかる。重要な特徴は残しつつ、データサイズを圧縮します。
| プーリングの種類 | やること |
|---|---|
| Maxプーリング | 小領域の中から最大値を選ぶ。最も目立つ特徴を残す。最もよく使われる |
| Averageプーリング | 小領域の平均値を取る。全体的な特徴を残す |
CNNの全体フロー
「畳み込み層の役割は?」→ 局所的な特徴を抽出する
「プーリング層の役割は?」→ 特徴マップを圧縮し、位置のズレに強くする
「CNNが得意なデータは?」→ 画像・空間的な構造を持つデータ
「CNNの代表的なモデルは?」→ LeNet、AlexNet、VGG、ResNet、GoogLeNet
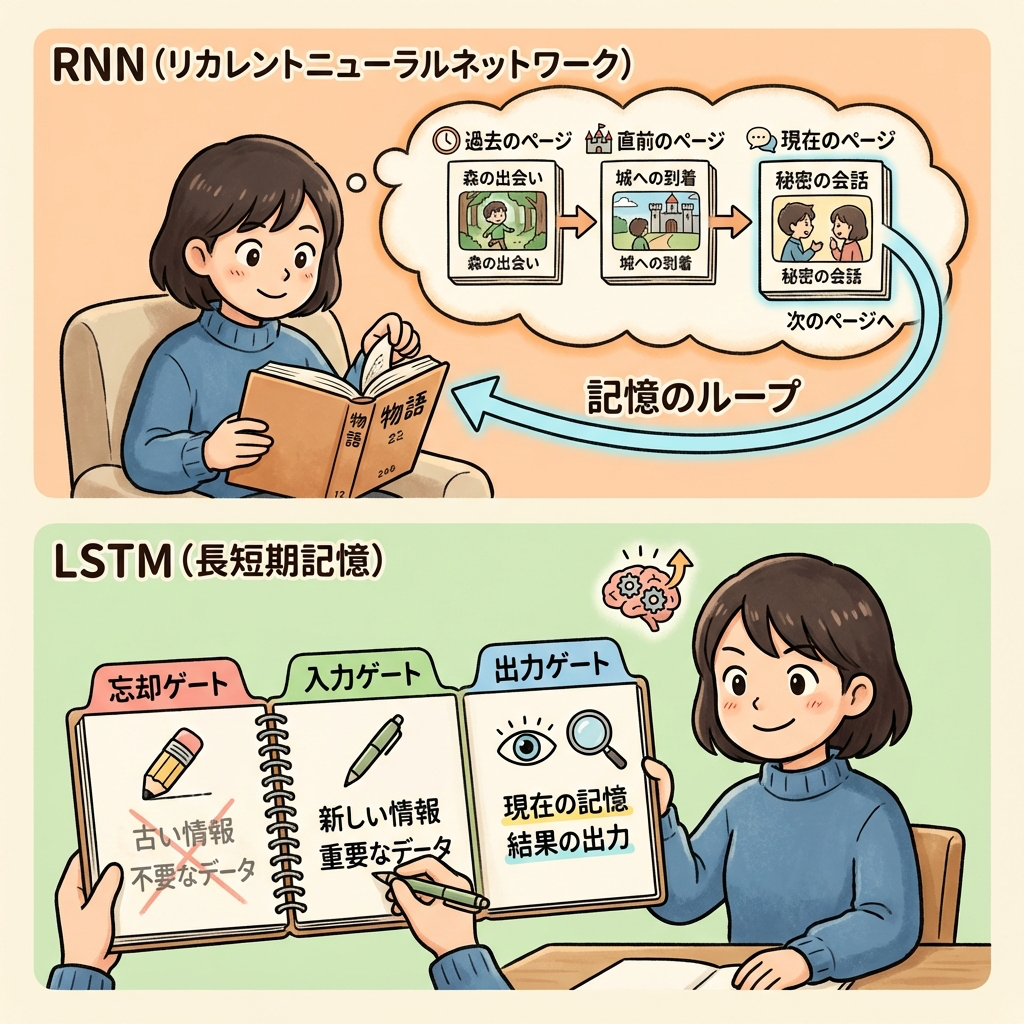
RNN(再帰型ニューラルネットワーク)|「前の情報を記憶する」ネットワーク
RNN(Recurrent Neural Network)は、系列データ(順番に並んだデータ)を扱うためのアーキテクチャです。テキスト、音声、株価、センサーデータなど、「時間の順序」や「前後の文脈」が重要なデータに使われます。
RNNの核心:「前の出力を次の入力に渡す」ループ構造
あなたが小説を読んでいるとします。今読んでいるページの内容は、前のページまでの記憶があって初めて理解できます。「彼」が誰を指すのか、なぜこの場面で登場人物が泣いているのか、すべて前のページの文脈に依存しています。
RNNも同じです。単語を1つずつ読みながら、前の単語の処理結果(隠れ状態)を次のステップに渡すことで、文脈を「記憶」しています。
RNNの弱点:長期記憶が苦手(勾配消失の再来)
RNNはループ構造を「時間方向に展開」して誤差逆伝播を行います(BPTT: Backpropagation Through Time)。しかし、系列が長くなると最初のほうの情報が失われてしまうという問題が起きます。先ほどの「伝言ゲームの声が小さくなる」問題と同じです。
小説の300ページ目を読んでいるとき、5ページ目の伏線を覚えていられますか? 人間でも難しいですが、RNNはもっと苦手です。50ステップ前の情報はほぼ消えてしまいます。
LSTM(Long Short-Term Memory)|「メモ帳付きRNN」
RNNの「長期記憶が苦手」問題を解決するために登場したのがLSTMです。LSTMは通常のRNNに「セル状態(Cell State)」というメモ帳と、3つのゲート(門)を追加しています。
| ゲート名 | 役割 | たとえ話 |
|---|---|---|
| 忘却ゲート | 古い記憶の中から不要な情報を捨てる | 「前の章の登場人物名はもう忘れていい」 |
| 入力ゲート | 新しい情報の中から重要な情報をメモ帳に書き込む | 「この新キャラの名前は重要!メモしておこう」 |
| 出力ゲート | メモ帳の情報の中から今必要な分だけ出力する | 「この場面で必要なのは犯人の名前だけ。他のメモは今は出さない」 |
LSTMは「何を覚えて、何を忘れて、何を出力するか」を学習するネットワークです。ゲートの開閉は学習によって自動的に最適化されます。これにより、長い系列でも重要な情報を保持できるようになりました。
GRU(Gated Recurrent Unit)|LSTMの軽量版
GRUは、LSTMのゲートを3つから2つ(更新ゲート・リセットゲート)に簡略化したモデルです。性能はLSTMとほぼ同等ですが、パラメータが少なく計算が速いのがメリットです。DS検定では「GRUはLSTMの簡略版」と覚えておけば十分です。
「RNNが得意なデータは?」→ 時系列・系列データ
「RNNの弱点は?」→ 長期依存関係を学習できない(勾配消失)
「LSTMがRNNの弱点を解決する仕組みは?」→ ゲート機構(忘却・入力・出力ゲート)でセル状態を制御
「GRUとLSTMの違いは?」→ GRUはゲート数が少ない簡略版

Transformer|「すべてを同時に見る」革命的アーキテクチャ
2017年にGoogleが発表した論文「Attention Is All You Need」で提案されたTransformerは、深層学習の歴史を完全に塗り替えたアーキテクチャです。ChatGPT(GPTシリーズ)、BERT、Stable Diffusion、ViT(Vision Transformer)など、現代AIの基盤はほぼすべてTransformerです。
RNNの限界とTransformerの革新
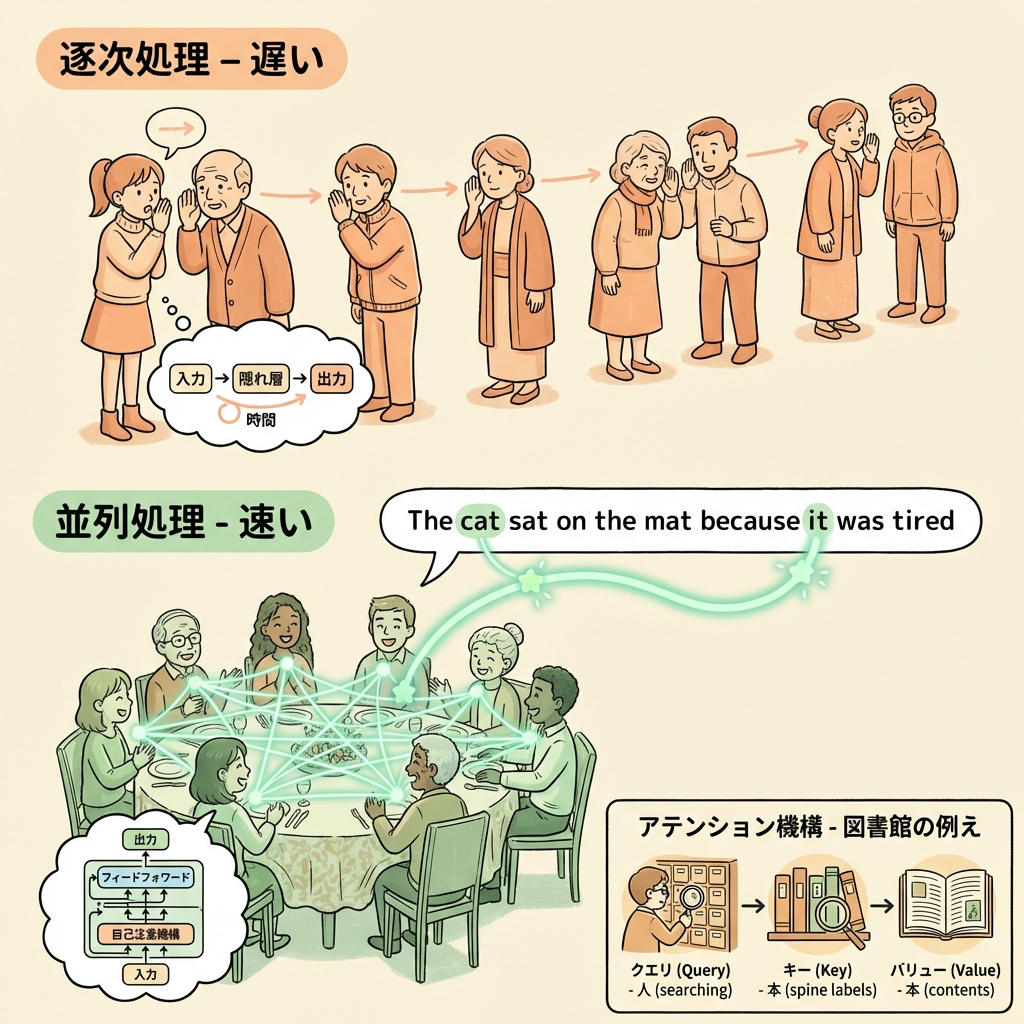
RNNは「1つずつ順番に処理する」ので2つの問題がありました。
| RNNの問題 | なぜ問題なのか | Transformerの解決策 |
|---|---|---|
| 逐次処理で遅い | 単語1→単語2→単語3…と直列処理。前の計算が終わらないと次に進めない | 全単語を同時に並列処理。GPUの計算能力を最大活用 |
| 長距離の依存関係が苦手 | 文の冒頭と末尾の関係を捉えにくい | Self-Attentionですべての単語ペアの関連性を直接計算 |
Self-Attention(自己注意機構)|Transformerの心臓部
Self-Attentionは、Transformerの核となる仕組みです。一言でいうと、「文の中のすべての単語が、他のすべての単語とどれくらい関連しているか」をスコアとして計算する仕組みです。
RNNは「一列に並んで伝言ゲーム」。前の人の話しか聞けません。
Transformerは「パーティーのフリートーク」。参加者全員が同時に会場にいて、誰でも好きな人と直接話せます。「この話題について一番詳しいのは誰?」と全員を見渡して、関連度の高い人に注目する(Attention=注意を向ける)のです。
例えば「The cat sat on the mat because it was tired.」という文で、「it」が何を指すかを理解するには「cat」に注目する必要があります。Self-Attentionは「it」と「cat」の関連性スコアを高くすることで、「it = cat」であることを自動的に学習します。
Query・Key・Valueの3つの概念
Self-Attentionの内部では、各単語をQuery(質問)・Key(キー)・Value(値)の3つのベクトルに変換して計算します。
Query:あなたが探している本のジャンル(=「今この単語に必要な情報は何?」)
Key:各本の背表紙に書いてあるジャンルラベル(=「自分はどんな情報を持っている?」)
Value:本の中身そのもの(=「実際に渡す情報」)
QueryとKeyを突き合わせて「一致度(関連度スコア)」を計算し、スコアが高い本(Value)を重点的に取り出す。これがSelf-Attentionの仕組みです。
エンコーダ・デコーダ構造
元のTransformerはエンコーダ(入力を理解する部分)とデコーダ(出力を生成する部分)で構成されています。
| 構造 | 役割 | 代表的モデル | 得意なタスク |
|---|---|---|---|
| エンコーダのみ | 入力テキストの「意味」を理解する | BERT | 分類、質問応答、感情分析 |
| デコーダのみ | テキストを「生成」する | GPTシリーズ | 文章生成、対話(ChatGPT) |
| エンコーダ+デコーダ | 入力を理解し出力を生成 | T5、元祖Transformer | 機械翻訳、要約 |
「TransformerがRNNと異なる点は?」→ 逐次処理ではなく並列処理、Self-Attentionで長距離依存を直接計算
「Self-Attentionの役割は?」→ すべての単語ペアの関連度を計算し、重要な情報に「注意を向ける」
「BERTとGPTの違いは?」→ BERTはエンコーダ型(理解)、GPTはデコーダ型(生成)
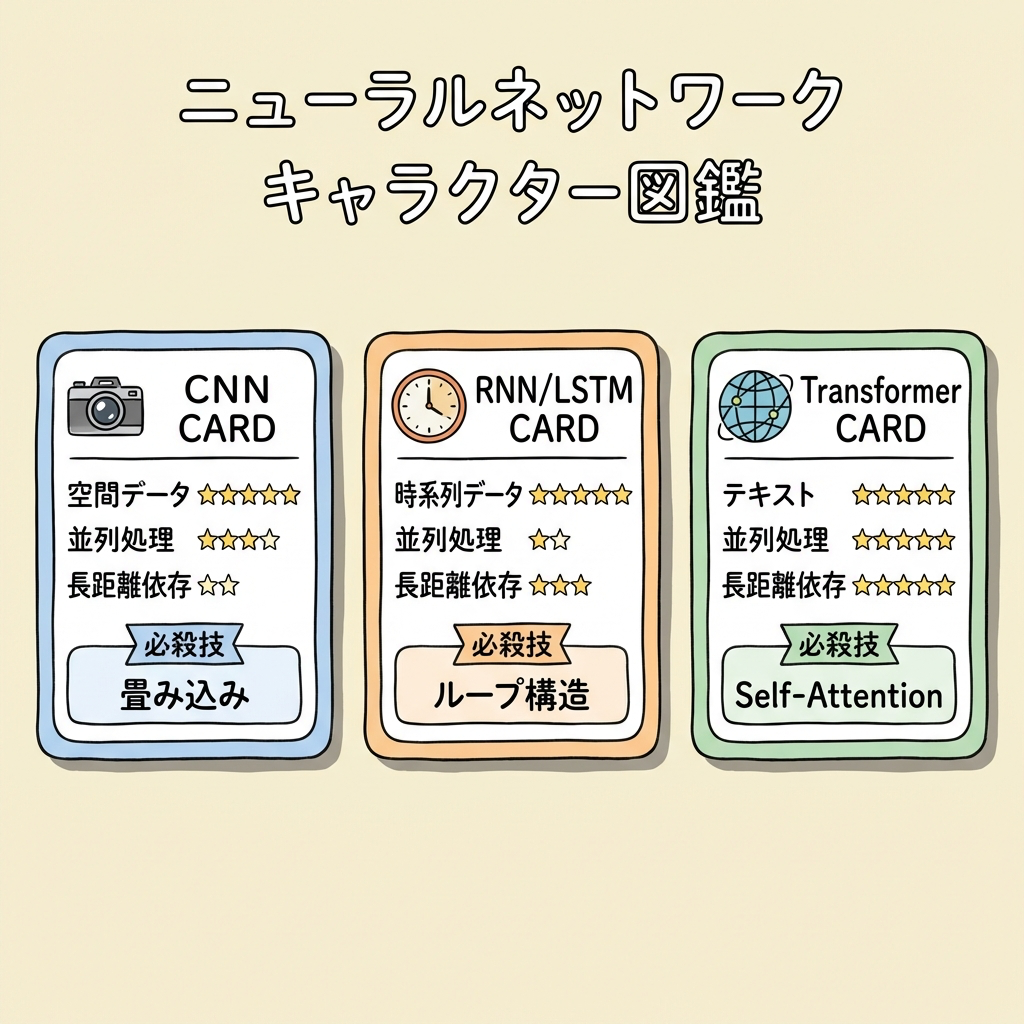
CNN・RNN・Transformer 完全比較表
3つのアーキテクチャの違いを1つの表にまとめます。DS検定では「このタスクにはどのアーキテクチャが適切か?」が問われるので、しっかり整理しておきましょう。
| 比較項目 | CNN | RNN / LSTM | Transformer |
|---|---|---|---|
| 得意なデータ | 画像・空間データ | 時系列・系列データ | テキスト(+画像にも拡張) |
| 核心の仕組み | 畳み込み(局所特徴の抽出) | ループ構造(前の情報を記憶) | Self-Attention(全体の関連性を計算) |
| 処理方式 | 並列処理可能 | 逐次処理(直列) | 並列処理可能 |
| 長距離依存 | 苦手(局所的) | LSTM/GRUで改善するが限界あり | 得意(全ペア直接計算) |
| 計算効率 | 高い | 低い(直列がボトルネック) | 高い(GPU並列に向く) |
| 代表モデル | ResNet, VGG, GoogLeNet | LSTM, GRU | BERT, GPT, T5, ViT |
| たとえ話 | 虫眼鏡でスライド | 小説を1ページずつ読む | パーティーで全員と同時に話す |
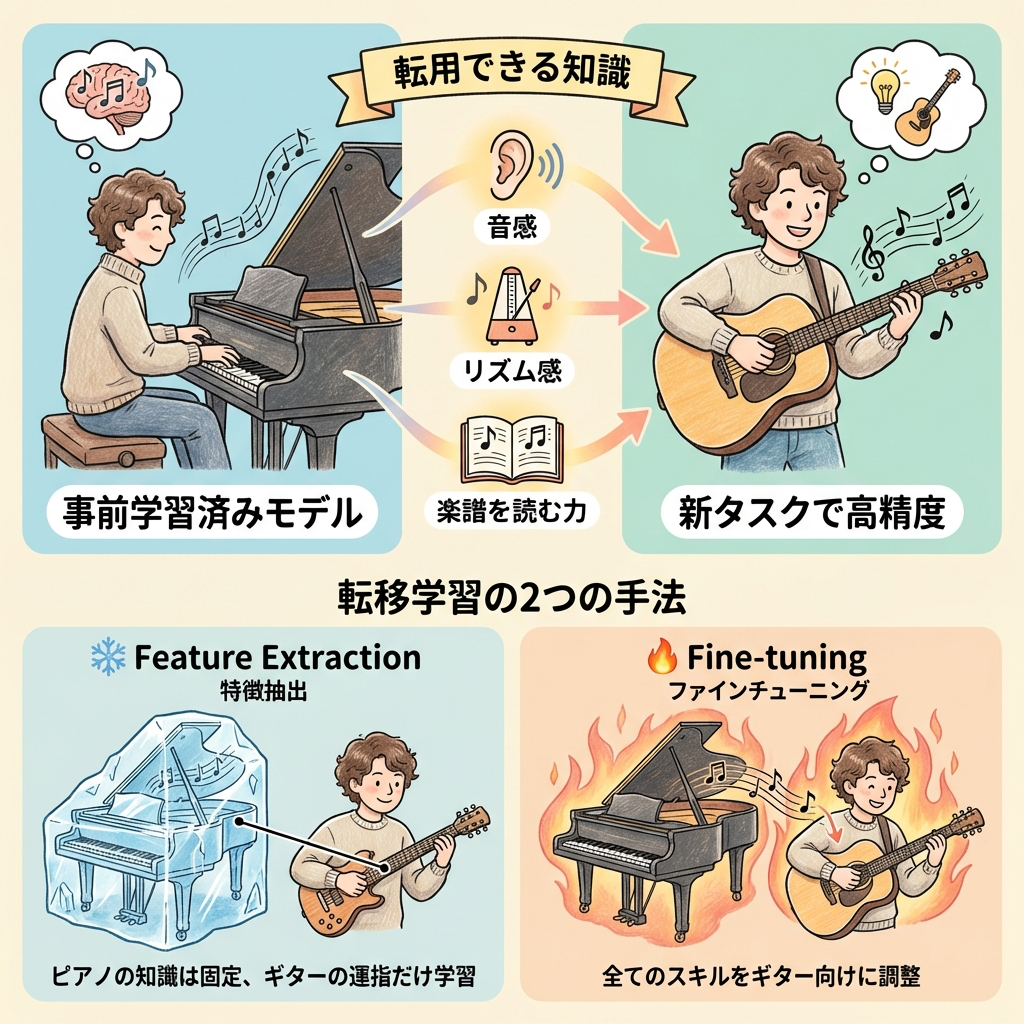
転移学習とファインチューニング|「既に学んだ知識を再利用する」
深層学習モデルの学習には膨大なデータと計算リソースが必要です。しかし、すでに学習済みのモデルの知識を「転用」すれば、少ないデータ・短い時間で高い精度を実現できます。この考え方が転移学習(Transfer Learning)です。
ピアノを長年弾いてきた人がギターを始めると、ゼロから始める人より圧倒的に速く上達します。なぜなら「音感」「リズム感」「楽譜を読む力」はピアノで培った知識がそのまま転用できるからです。
転移学習も同じです。画像認識で大量の画像を学んだモデルは「エッジ」「テクスチャ」「形状」などの汎用的な特徴量の抽出方法をすでに知っています。この知識を新しいタスク(例:医療画像の診断)に転用するのです。
転移学習の2つの方法
特徴抽出(Feature Extraction)
学習済みモデルの重みを固定(凍結)して、最後の分類層だけを新しいタスク用に付け替える
=「ピアノの腕前はそのまま、ギター用の指使いだけ練習」
ファインチューニング(Fine-tuning)
学習済みモデルの重みを初期値として、新しいデータで全体を追加学習する
=「ピアノの腕前をベースに、ギター向けにフォーム全体を微調整」
「転移学習のメリットは?」→ 少ないデータ・短い学習時間で高い精度を実現できる
「ファインチューニングとは?」→ 事前学習済みモデルの重みを初期値として、新しいデータで追加学習すること
「BERTやGPTが転移学習と関連する理由は?」→ 大量のテキストで事前学習し、個別タスクにファインチューニングする仕組みだから
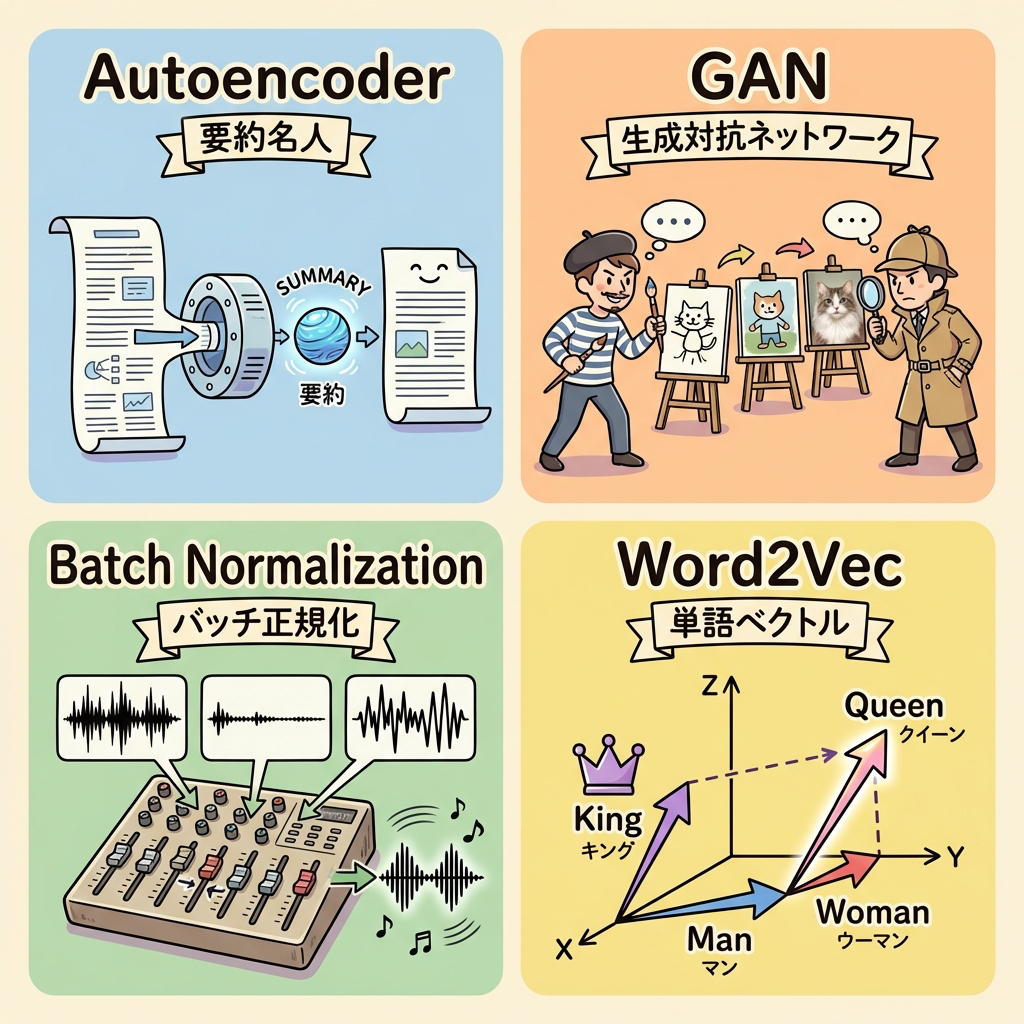
その他のDS検定頻出キーワード
ここまでの主要アーキテクチャに加えて、DS検定で出題される可能性がある重要キーワードをまとめます。
オートエンコーダ(Autoencoder)
入力データを一度圧縮(エンコード)してから復元(デコード)するネットワーク。圧縮時に次元を削減するため、特徴抽出や異常検知に使われます。圧縮後の「中間表現」がデータの本質的な特徴を捉えています。
「要約名人」に似ています。長い文章を30文字に要約し(エンコード)、その30文字から元の文章を復元する(デコード)訓練をします。うまく復元できるなら、30文字の要約はデータの本質を捉えているということです。
GAN(敵対的生成ネットワーク)
生成器(Generator)と識別器(Discriminator)の2つのネットワークが「騙し合い」をしながら学習する仕組みです。
生成器=贋作師。本物そっくりの偽物を作ろうとする
識別器=鑑定士。本物か偽物かを見破ろうとする
贋作師は鑑定士を騙すために腕を上げ、鑑定士は贋作師を見破るために目を鍛えます。この競い合いが続くと、最終的に贋作師は本物と見分けがつかないレベルの作品を作れるようになります。
バッチ正規化(Batch Normalization)
各層の入力を正規化(平均0、分散1に近づける)することで、学習を安定・高速化するテクニックです。勾配消失の緩和にも効果があります。DS検定では「学習を安定化させる手法」として覚えておけば十分です。
Word2Vec / 単語の分散表現
単語をベクトル(数字の列)で表現する技術です。「King - Man + Woman = Queen」のように、単語の意味関係がベクトル演算で表現できることで有名です。Transformerの登場前は自然言語処理の基盤技術でした。
Data Augmentation(データ拡張)
訓練データが少ないときに、既存のデータを加工して水増しするテクニックです。画像の回転、反転、拡大縮小、色調変更などが代表的です。前回の記事で解説した「過学習対策」の一つでもあります。
DS検定で問われる深層学習の出題パターン総まとめ
最後に、この記事の内容をDS検定の出題パターンに沿って整理します。
| 出題パターン | 押さえるべきポイント |
|---|---|
| 「深層学習とは何か?」 | ニューラルネットワークの隠れ層を深く(多く)積み重ねたもの |
| 「活性化関数の役割と種類」 | 非線形変換を加えること。隠れ層=ReLU、分類出力=Sigmoid/Softmax |
| 「誤差逆伝播法とは?」 | 出力の誤差を逆方向に伝えて、各重みの更新量を計算する手法 |
| 「勾配消失問題と対策」 | 深い層の勾配が消える。対策:ReLU、バッチ正規化、残差接続、LSTM |
| 「CNNの構造と用途」 | 畳み込み層+プーリング層。画像の局所特徴を抽出。画像認識向き |
| 「RNNの構造と弱点」 | ループ構造で系列データ処理。弱点は長期依存の学習困難(勾配消失) |
| 「LSTMの3つのゲート」 | 忘却ゲート・入力ゲート・出力ゲートで「何を覚え何を忘れるか」を制御 |
| 「TransformerとSelf-Attention」 | 全単語の関連性を並列計算。Query/Key/Valueの仕組み。RNNの逐次処理を解決 |
| 「BERTとGPTの違い」 | BERT=エンコーダ型(理解・分類)、GPT=デコーダ型(生成) |
| 「転移学習とは?」 | 学習済みモデルの知識を新タスクに再利用。少データで高精度を実現 |
| 「GANの仕組み」 | 生成器と識別器が敵対的に学習。画像生成などに使われる |
深層学習の出題では、数式よりも「概念の正しい理解」と「適切な手法の選択」が問われます。「画像データ→CNN」「時系列データ→RNN/LSTM」「テキスト→Transformer」というデータ×手法のマッチングを軸に覚えると効率的です。
また、「なぜその手法が生まれたのか?」というストーリーで理解すると忘れにくくなります。「RNNの逐次処理と長距離依存の弱点→Transformerが並列処理+Self-Attentionで解決」という前の手法の「困りごと」が次の手法を生んだ流れです。
📚 次に読むべき記事
深層学習の前提となる機械学習の基礎知識をまとめた記事
DS検定の全体像を把握し、効率的な学習計画を立てよう
機械学習・深層学習と並ぶ頻出分野「統計学」をまとめて攻略する