{kind=link}
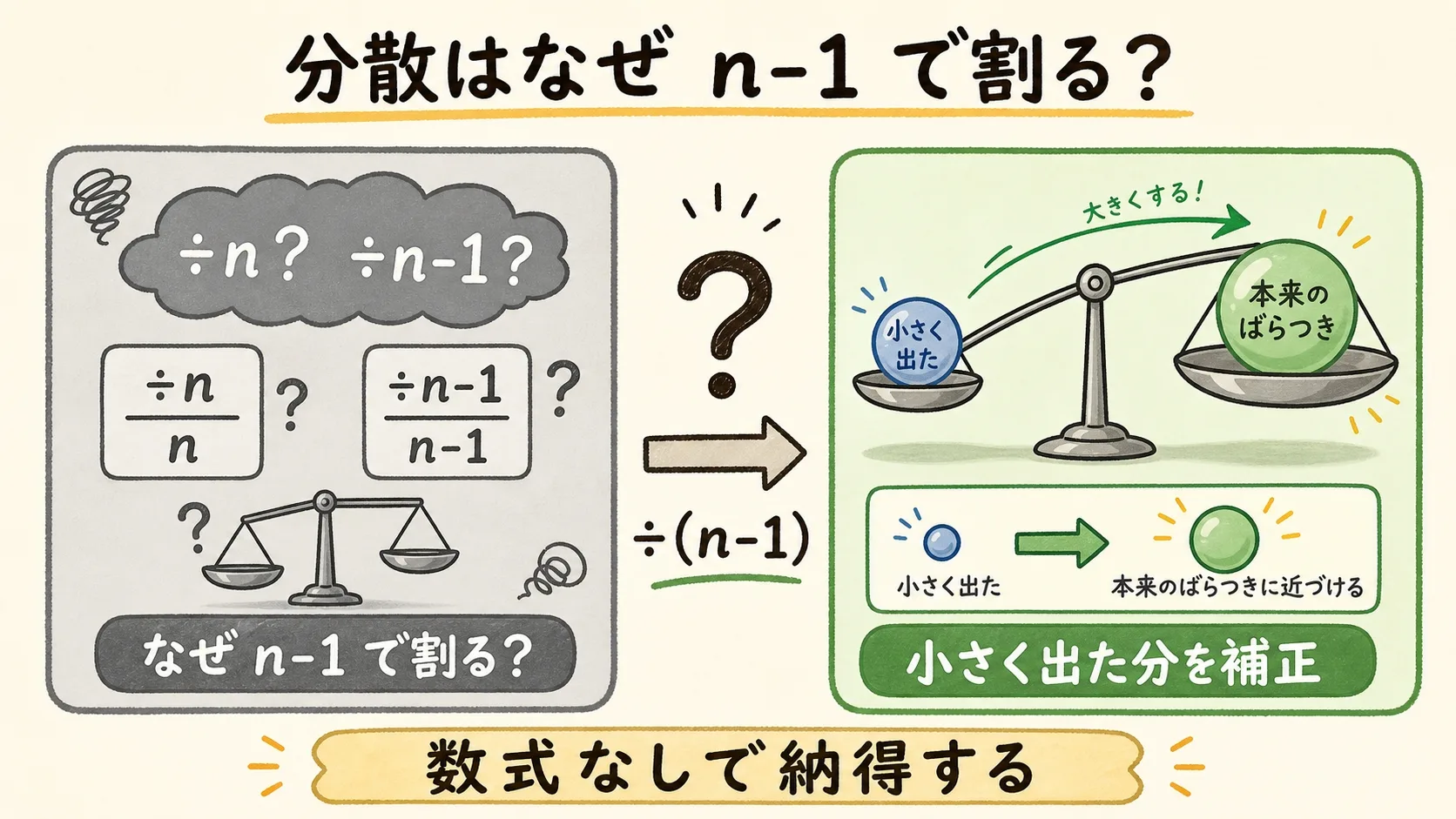
- 平均はnで割るのに、分散だけn-1で割る理由が、何度調べても腑に落ちない
- 「自由度」「不偏」「過小評価」という言葉が並ぶと、もう頭が真っ白になる
- ExcelのSTDEV.PとSTDEV.S、どっちを使えばいいのか毎回不安になる
- なぜn-1で割るのかが、数式ゼロで「なるほど!」と納得できる
- 「バラつきが小さく出すぎる」の意味を、的当ての例でイメージできる
- Excelで関数を選ぶとき、もう迷わなくなる
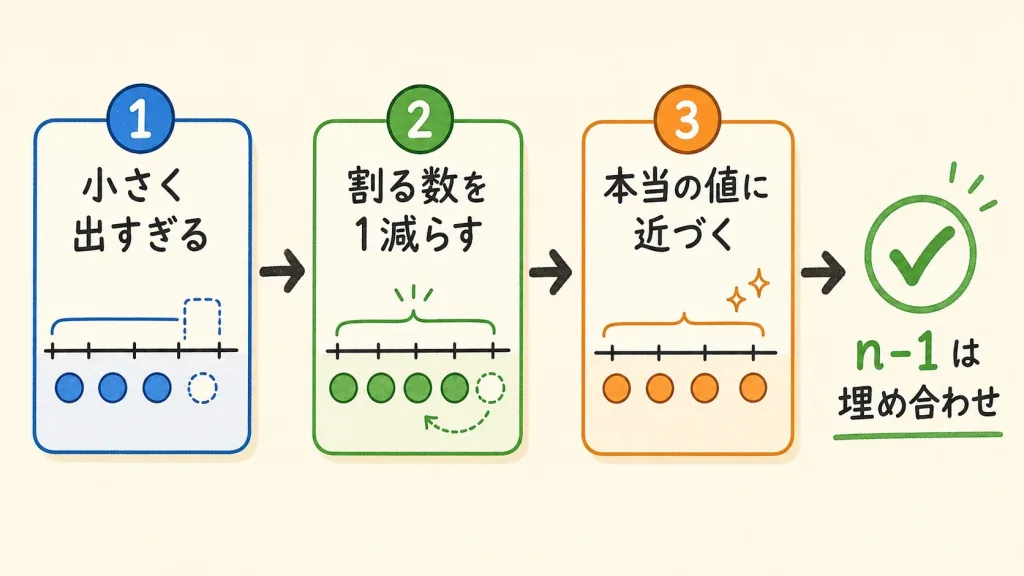
分散(ぶんさん)をn-1で割る理由は、ひとことで言うと「そのままだとバラつきが小さく出すぎるから、少し大きく直すため」です。手元の少ないデータだけで計算すると、本当のバラつきより小さく見えてしまう性質があります。そこで割る数を、データの個数nからn-1へと1つ減らすと、答えがほんの少し大きくなり、本当の値に近づきます。つまりn-1は「小さく出すぎたぶんを補う調整」だと考えてください。むずかしい数式は必要ありません。
目次
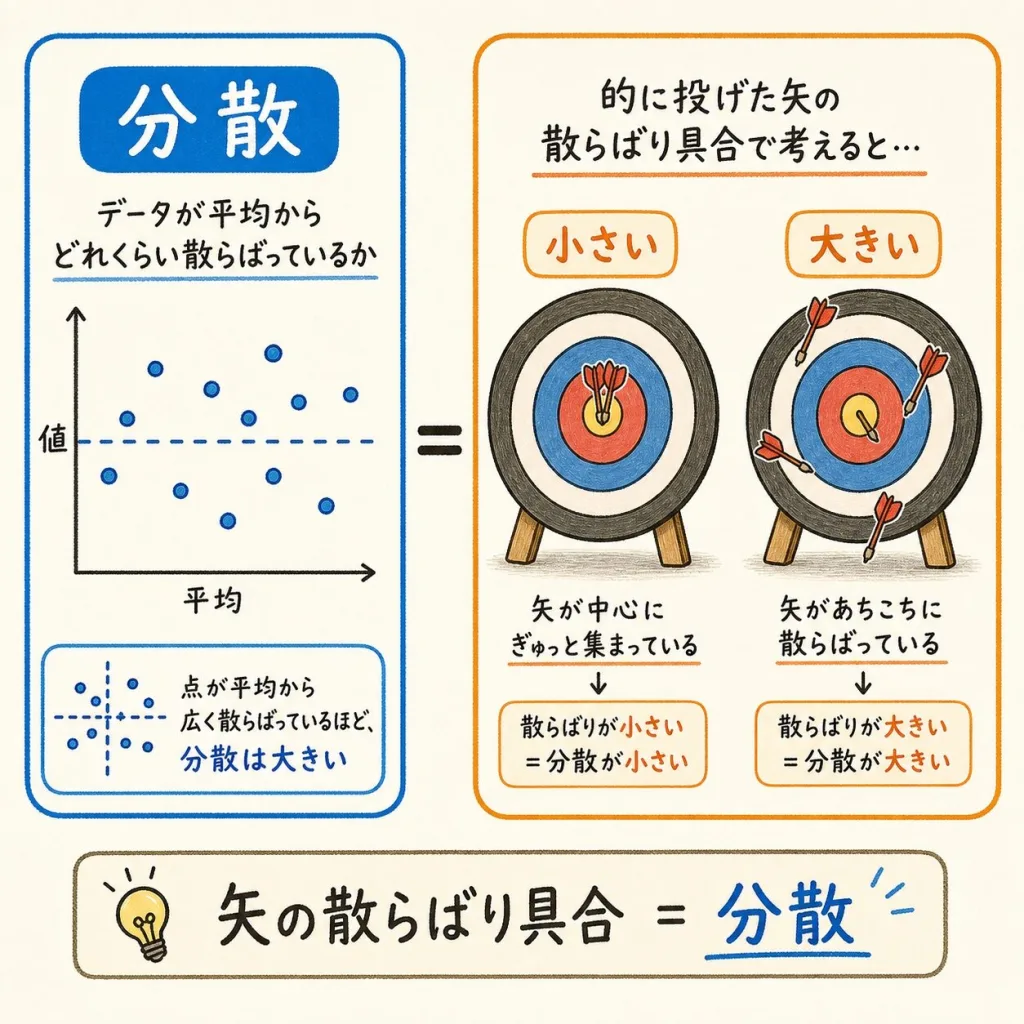
そもそも分散とは「バラつきの大きさ」
本題に入る前に、分散とは何かを1分だけおさらいします。分散とは、データが「どれくらい散らばっているか」を表す数字です。
たとえばテストの点数。「全員が80点」のクラスと、「100点と60点ばかり」のクラスでは、平均は同じ80点でも、散らばり方がまったく違いますよね。この「散らばり具合」を数字にしたものが分散です。
ダーツの的を思い浮かべてください。矢が全部ど真ん中に集まっていればバラつきは小さい(分散が小さい)。バラバラに散らばっていればバラつきは大きい(分散が大きい)。分散は「矢の散らばり具合」だと思ってください。
分散を出すときは、まず平均を求めて、各データが平均からどれくらい離れているかを計算します。この「平均からの離れ具合」を集めたものが分散の正体です。つまり分散とは、「データが平均からどれだけバラついているか」を表す数字だ、ということです。
じつは「平均」には2種類あった
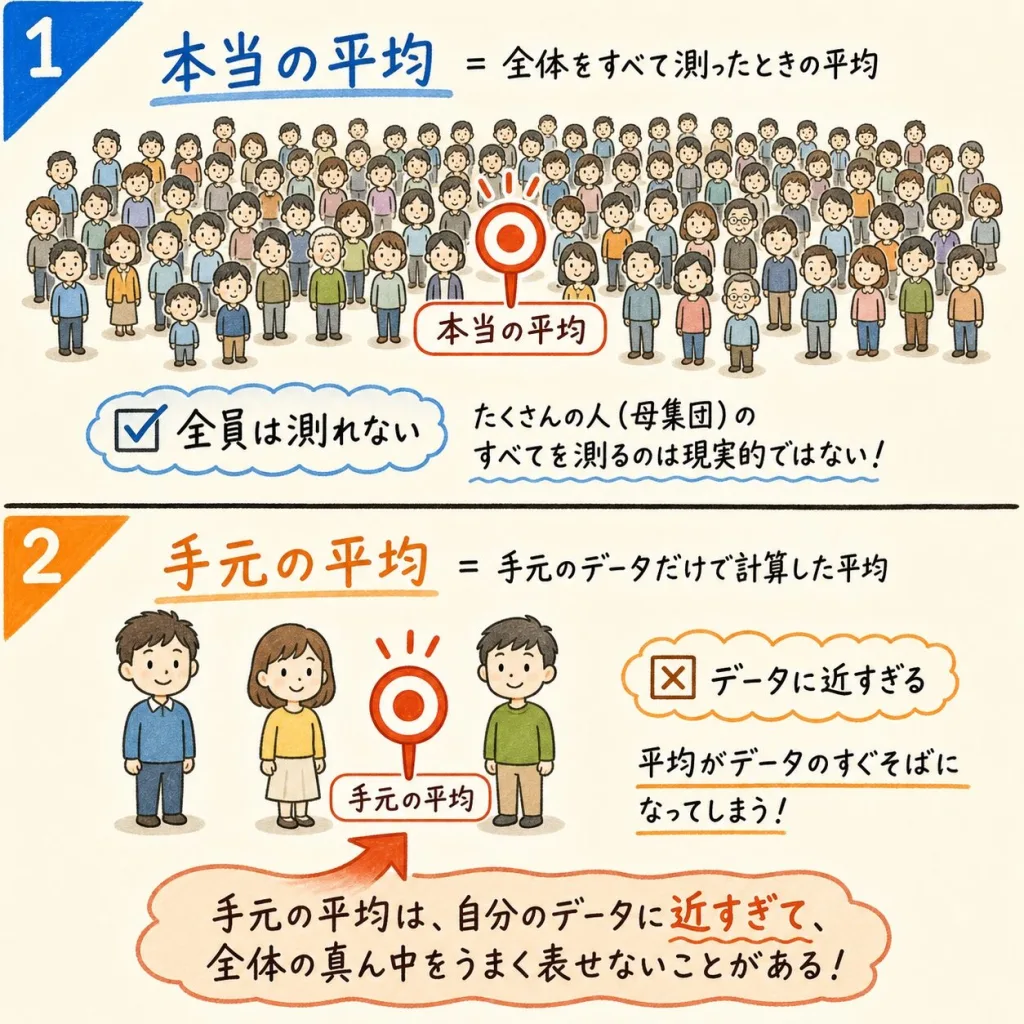
ここがすべての出発点です。じつは私たちが本当に知りたい平均は、手元で計算している平均とは別物なのです。
本当の平均(知りたい)
- 世の中全体の、本当の平均
- 例:日本人全員の身長の平均
- でも全員は測れない…
手元の平均(実際に使う)
- 集めた一部のデータの平均
- 例:100人だけ測った平均
- 本当の平均の「代わり」
本当に知りたいのは「世の中全体の平均」ですが、全員を調べるのは無理ですよね。だから一部だけデータを集めて、その平均を「代わり」に使います。
「手元の平均」は、集めたデータから計算したものです。つまり、そのデータたちにいちばん近い場所に来ます。当たり前ですよね。自分たちで作った平均なのですから。この「近すぎる」ことが、後でバラつきを小さく見せる原因になります。
つまり、私たちは「本当の平均」を知らないので、しかたなく「手元の平均」で代用している。これがn-1の謎を解くカギだ、ということです。
なぜバラつきが「小さく出すぎる」のか
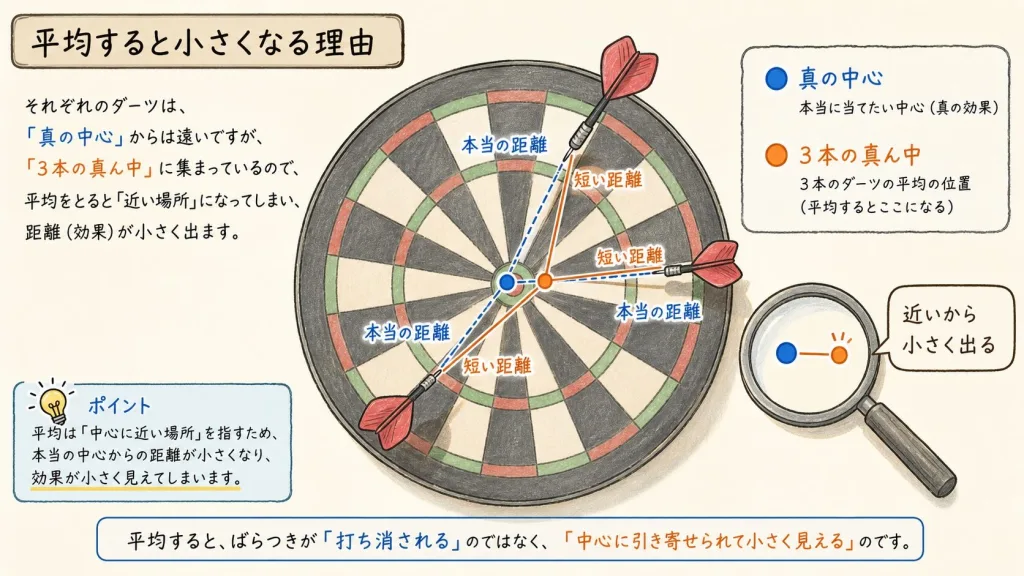
いよいよ核心です。「手元の平均」を使うと、なぜバラつきが小さく出てしまうのか。的当てで考えてみましょう。
壁に矢を3本投げたとします。本当は「狙った的の中心」からどれくらいズレたかを測りたい。でも、的の中心がどこか分かりません。そこで、しかたなく「3本の矢のちょうど真ん中」を中心だと思って、そこからの距離を測ります。
「3本の矢の真ん中」は、3本の矢にいちばん近い場所にあります。だから、そこから測った距離は、「本当の的の中心」から測った距離より、必ず短くなります。自分たちのど真ん中なんだから、近いのは当たり前ですよね。
この「短くなった距離」を使ってバラつきを計算すると、本当のバラつきより小さくなってしまいます。これが「バラつきを小さく見積もってしまう(過小評価)」の正体です。
手元のデータから平均を作ると、データはその平均の周りに「こぢんまり」と集まって見えます。だから散らばりが実際より小さく見える。この小さく見えたぶんを取り戻すために、あとで少し大きく直してあげる必要があるのです。
つまり、手元の平均は「データに近すぎる」から、バラつきが小さく出る。だから補正がいる、ということです。
n-1で割ると、答えが少し大きくなる
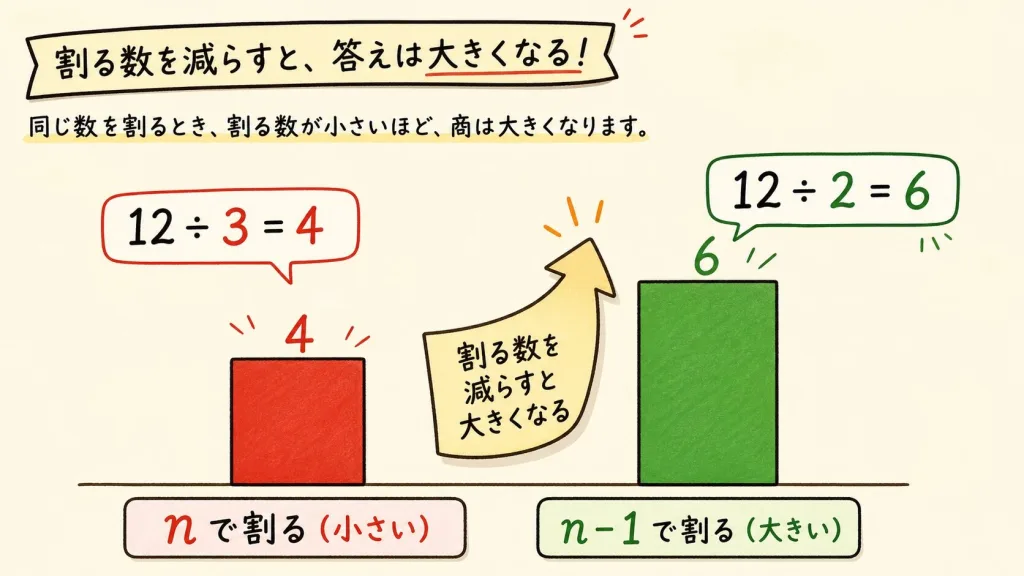
小さく出すぎるなら、答えを少し大きくしてあげればいい。そのための簡単な方法が「割る数を1つ減らす」ことです。
割り算は、割る数が小さいほど答えが大きくなります。これは小学校で習った通りです。たとえば——
| 計算 | 答え |
|---|---|
| 12 ÷ 3(個数nで割る) | 4 |
| 12 ÷ 2(n-1で割る) | 6(少し大きい!) |
同じ12でも、3で割れば4、2で割れば6。割る数を1つ減らすだけで、答えが大きくなりましたね。
バラつきが小さく出すぎる → 答えを少し大きくしたい → だから割る数をnからn-1に減らす。これだけのことなのです。「n-1で割る」は、小さく出たぶんを取り戻すための、ちょっとした工夫です。
ちなみに、こうして補正した分散のことを「不偏分散(ふへんぶんさん)」と呼びます。「偏り(小さく出すぎる偏り)をなくした分散」という意味です。つまり、n-1で割ることで、小さく出た分散を本当の値に近づけている、ということです。
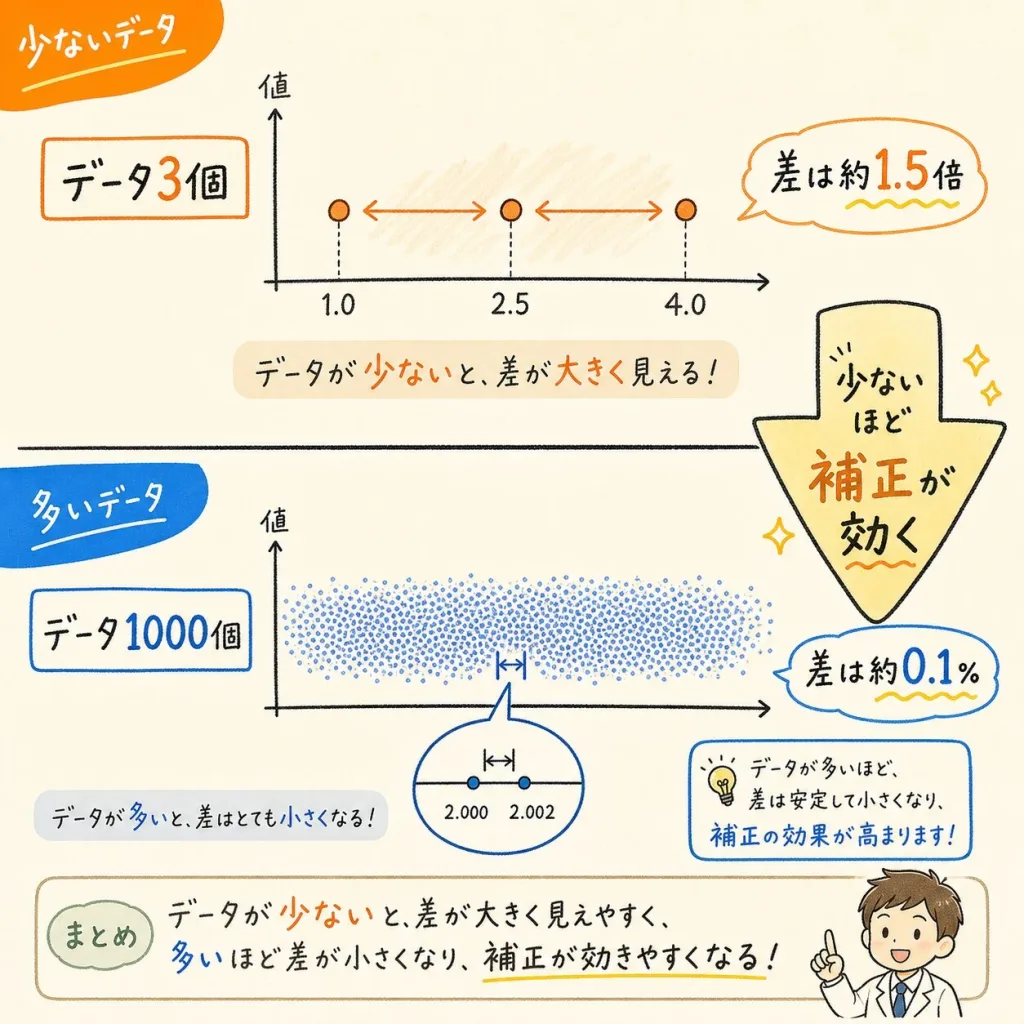
補正の効き目は「データの数」で変わる
この補正、じつはデータが少ないときほど大きく効きます。これも直感どおりで、わかりやすいですよ。
データが少ないとき(3個):補正は大きい
たった3個だと、手元の平均は3個のデータにべったり寄り添った場所にあります。バラつきがかなり小さく出てしまうので、しっかり補正が必要です。
3で割るか、2(=3-1)で割るかでは、答えが 1.5倍 も変わります。これは無視できない大きな差です。
データが多いとき(1000個):補正はごくわずか
1000個も集めれば、手元の平均は「本当の平均」にかなり近づきます。だからバラつきのズレもごくわずか。
1000で割るか、999で割るかの差は、たったの 0.1%ほど。ほとんど誤差です。
| データ数 | nとn-1の差 | 補正の重要度 |
|---|---|---|
| 3個 | 約1.5倍 | とても大事 |
| 1000個 | 約0.1% | ほぼ気にしなくてよい |
つまり、「データが少ないときほど、n-1の補正が大事になる」ということです。統計はデータが少ないときほど慎重さが求められる、とよく言われるのはこのためです。
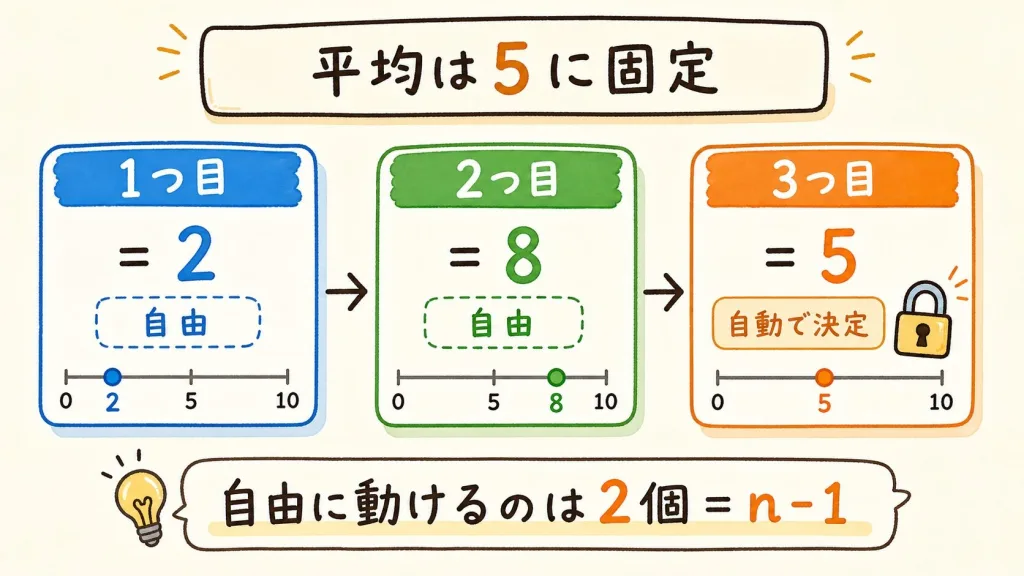
もう一つの説明「自由度」もやさしく
教科書では「自由度が減るからn-1」と書かれていることが多いです。難しそうに聞こえますが、これもクイズ感覚で理解できます。
「3つの数字の平均が5」と決まっているとします。3つの数字を当ててみましょう。
好きに決めてOK → たとえば「2」
これも好きに決めてOK → たとえば「8」
もう自由に決められない! 平均を5にするには「5」しかない
平均が5と決まっていると、3つ目の数字は自動的に決まってしまいます。1つ目と2つ目で2+8=10、合計を15(=5×3)にするには、3つ目は5しかありえません。
3個のうち、自由に決められるのは2個だけ。最後の1個は「つじつま合わせ」で自由を失います。この「自由に動ける数」を自由度といい、3個なら自由度は2(=3-1)。分散の計算でも、平均を使った時点で1個ぶんの自由を使ってしまうので、有効な数はnではなくn-1になるのです。
つまり「自由度=自由に動ける数」で、平均を使うと1個ぶん自由が減るからn-1。さっきの「小さく出すぎるから補正」と、結局は同じことを別の言い方で説明しているだけ、ということです。
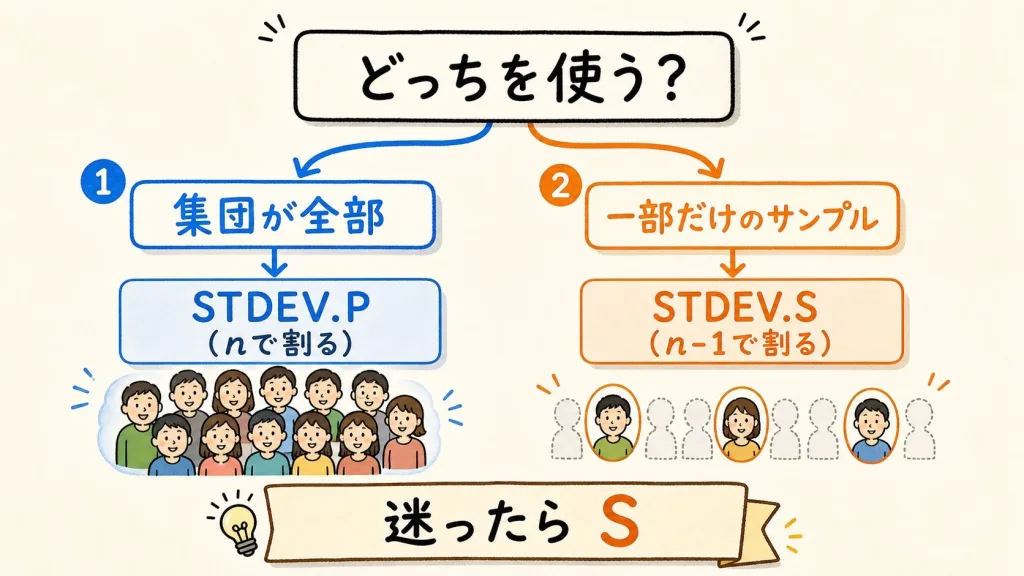
Excelの関数はどっちを使う?
最後に、いちばん実用的な話です。Excelには似た関数が2つあって、どちらを使うか迷いますよね。判断はとてもシンプルです。
STDEV.P(nで割る)
- 調べた集団が「全部」のとき
- 例:クラス全員の点数
- P=Population(集団全体)
STDEV.S(n-1で割る)
- 一部だけ調べた「サンプル」のとき
- 例:抜き取った製品100個
- S=Sample(標本)
手元のデータが「調べたい対象の全部」でない限り、ふつうは STDEV.S(n-1) を選んでおけば大丈夫です。世の中のデータ分析は、ほとんどが「一部を抜き取って全体を推測する」場面だからです。
つまり、「全部そろっているならP、一部だけならS」。迷ったらSを選ぶ、と覚えておけば困りません。なお、関数の正確な仕様はお使いのExcelのバージョンによって表示が異なる場合があるので、ヘルプも確認してみてください。
よくある質問
まとめ:n-1は「小さく出たぶんの埋め合わせ」
- 分散=データのバラつきの大きさ
- 手元の平均はデータに近すぎて、バラつきが小さく出てしまう
- だから割る数をnからn-1に減らして、答えを少し大きく直す
- 補正後の分散を「不偏分散」と呼ぶ
- データが少ないときほど補正が効く(3個で1.5倍、1000個で0.1%)
- 「自由度」も同じことの別の言い方。平均を使うと自由が1個減る
- Excelは全部ならSTDEV.P、一部ならSTDEV.S。迷ったらS
n-1で割るのは、難しいルールでも意地悪な決まりでもありません。「少ないデータから本当の姿を知ろうとする私たちのための、ちょっとした調整」なのです。この感覚がつかめると、統計の数式が一気に身近になります。
分散の次は、分散とセットで使う「標準偏差」も合わせて学ぶと、データのバラつきを自在に語れるようになりますよ。
自動車部品メーカーで電気設計・品質保証に携わってきた経験をもとに執筆しています。むずかしい専門用語をできるだけ使わず、はじめて統計を学ぶ人がつまずかないように、図とたとえで説明することを大切にしています。
📚 次に読むべき記事
分散を含む統計学全体を、どの順番で学べばいいか迷わなくなる学習地図です。
そもそも分散とは何か、標準偏差との関係をゼロからやさしく解説しています。
この記事で触れた「自由度」を、もっと深く理解したい人向けの一歩進んだ記事です。