
- 「DS検定の出題範囲を見たら統計トピックが大量すぎて、どこから手をつければ…」
- 「"統計数理基礎"って書いてあるけど、具体的に何を覚えればいいのかわからない」
- 「ベイズの定理とか正規分布とか、名前は聞いたことあるけど意味がぼんやり」
- 「相関と因果の違いを聞かれたら、正直うまく説明できない」
- DS検定で出る統計トピックの全体マップと優先順位
- 各トピックの「一言で言うとこういうこと」という直感的な理解
- 代表値・分散・正規分布・推定検定・ベイズ・相関因果の核心だけを厳選解説
- 各トピックの詳細解説記事へのリンク(深掘りはそちらで)
DS検定のデータサイエンス力で、最も出題ウェイトが大きいのが「統計」です。
公式スキルレベル資料(PDF)を見ると、★1(見習いレベル)で求められる統計の知識は「代表値、分散、標準偏差、正規分布、条件付き確率、母集団、相関、ベイズの定理」とあります。範囲は広いですが、一つ一つは「概念の意味」と「基本的な計算」がわかればOKなレベルです。
この記事は「統計トピックの全体マップ」兼「各詳細記事へのナビゲーション」として設計しています。各トピックの核心をこの記事で掴み、もっと深く理解したいものは詳細記事に飛んで学習する——この流れで進めてください。
目次
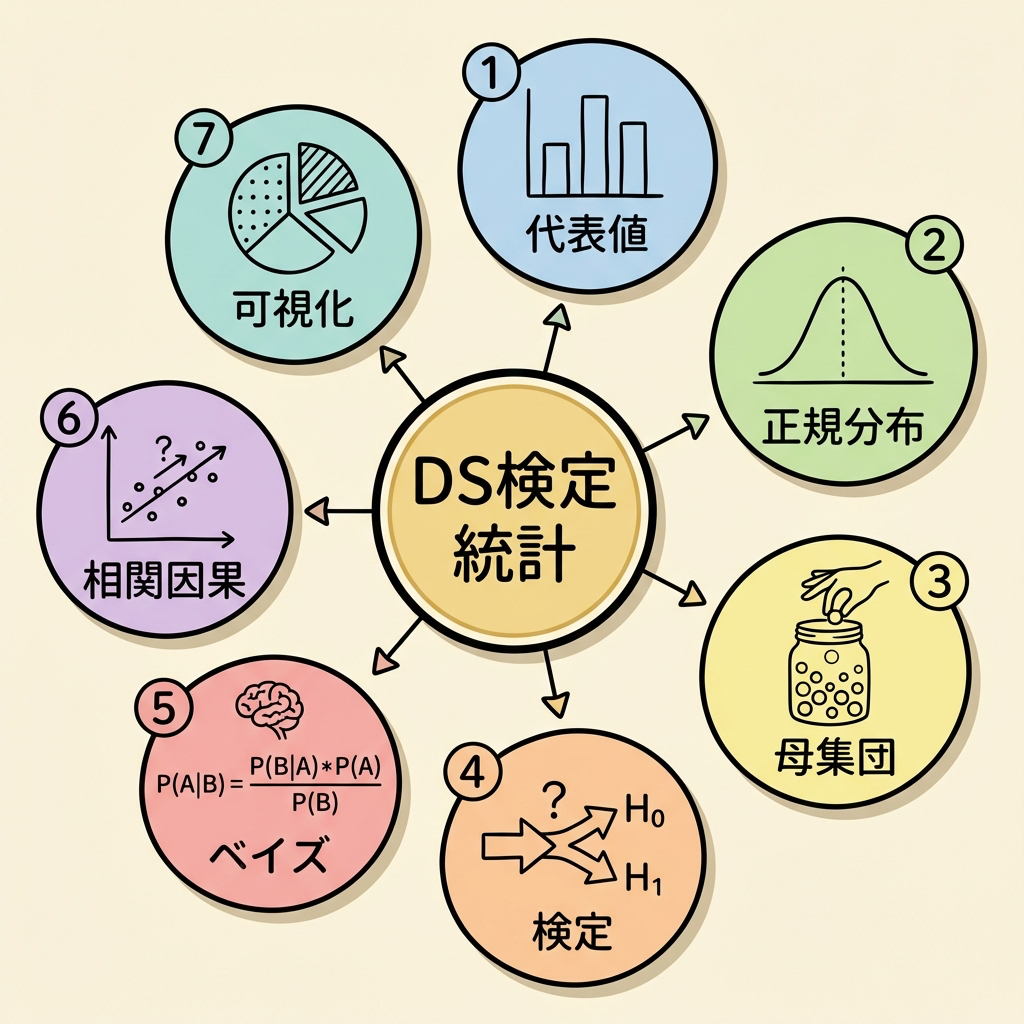
まずは全体像|DS検定「統計」の7大トピック
DS検定で出題される統計トピックを整理すると、大きく7つのブロックに分けられます。「今自分はどこを勉強しているのか」がわかるよう、マップとして頭に入れておきましょう。
| # | トピック | 一言でいうと | 出題頻度 |
|---|---|---|---|
| 1 | 代表値とバラつき | データの「真ん中」と「散らばり」を数値化 | ⭐⭐⭐ |
| 2 | 確率分布(正規分布) | データの「形」を数式で表す | ⭐⭐⭐ |
| 3 | 母集団と標本 | 「全体」を「一部」から推測する考え方 | ⭐⭐⭐ |
| 4 | 推定と検定 | データから「仮説が正しいか」を判断 | ⭐⭐⭐ |
| 5 | 条件付き確率とベイズ | 「新しい情報」で確率を更新する | ⭐⭐ |
| 6 | 相関と因果 | 「関連がある」と「原因→結果」は別物 | ⭐⭐⭐ |
| 7 | データの可視化と誤読防止 | グラフの「嘘」を見抜く力 | ⭐⭐ |
⭐⭐⭐のトピックから攻略してください。特に「代表値とバラつき」「正規分布」「相関と因果」は、DS検定だけでなくモデルカリキュラムの出題範囲にも含まれており、ほぼ確実に出題されると思って間違いありません。

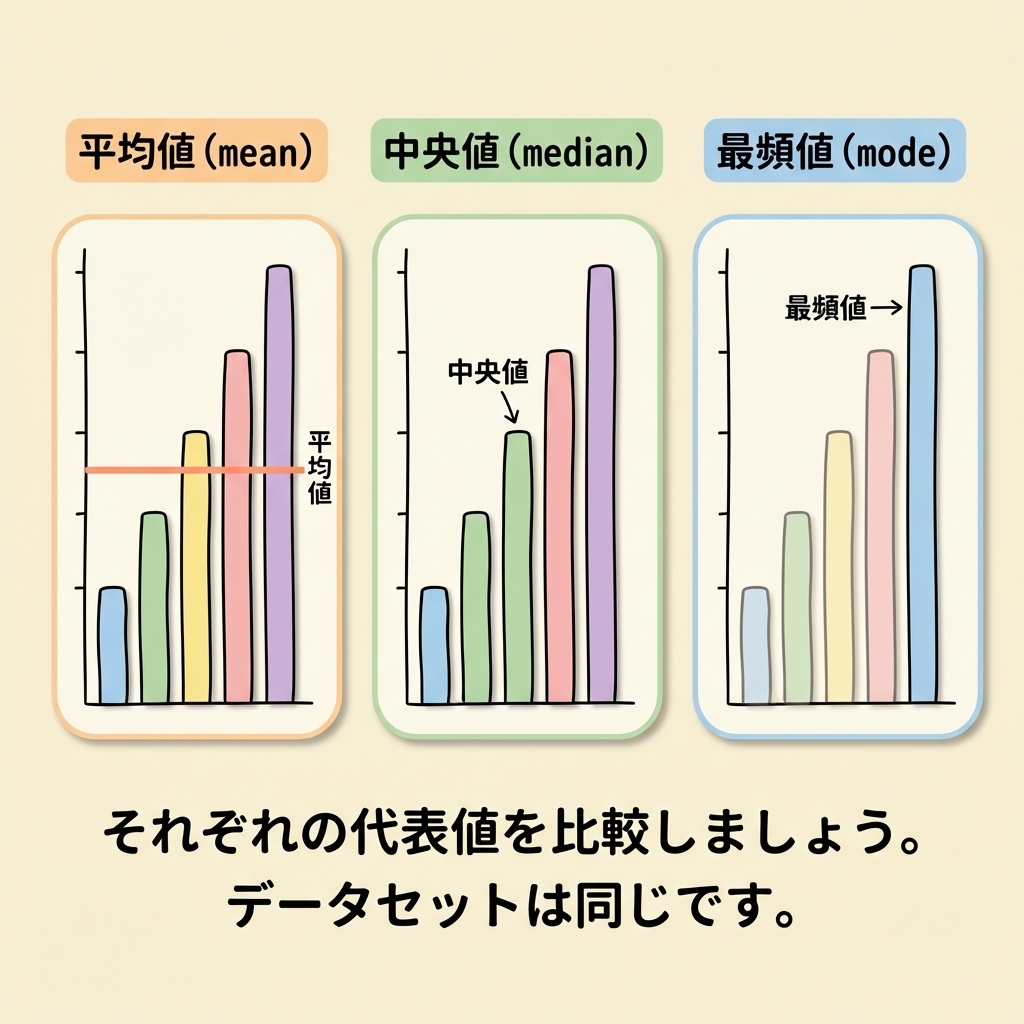
トピック①:代表値とバラつき|データの「ど真ん中」と「散らばり」
統計の第一歩は「データ全体を少ない数値で要約する」ことです。代表値は「真ん中」を、バラつきは「散らばり具合」を表します。
3つの代表値|平均値・中央値・最頻値
テストの点数で例えましょう。5人の点数が 50, 60, 70, 80, 90 のとき。
| 代表値 | 意味 | 計算結果 | 日常の例え |
|---|---|---|---|
| 平均値 | 全部足して人数で割る | (50+60+70+80+90)÷5 = 70 | 割り勘の金額 |
| 中央値 | データを並べて真ん中の値 | 70(3番目) | 年収の中央値 |
| 最頻値 | 最も頻繁に出現する値 | (この例では全部1回なのでなし) | 一番売れている服のサイズ |
「外れ値があるとき、平均値と中央値のどちらが適切か?」という問題が頻出です。答えは中央値。たとえば5人の年収が 300, 350, 400, 450, 5000万円のとき、平均は1300万円になりますが、実態とかけ離れていますよね。こういうとき中央値(400万円)の方が「普通」を正しく表します。
バラつきの指標|分散と標準偏差
代表値だけでは「データがどれくらい散らばっているか」がわかりません。同じ平均70点でも、「全員70点」と「0点と140点が半々」では意味がまったく違います。この散らばり具合を数値化するのが分散と標準偏差です。
分散
各データと平均の差を2乗して平均したもの。
散らばりの「面積」のイメージ。単位が元データの2乗になるので直感的にわかりにくい。
標準偏差
分散の平方根(ルート)。
散らばりの「距離」のイメージ。元データと同じ単位なので直感的にわかりやすい。
分散 = Σ(各データ − 平均)² ÷ データ数
標準偏差 = √分散
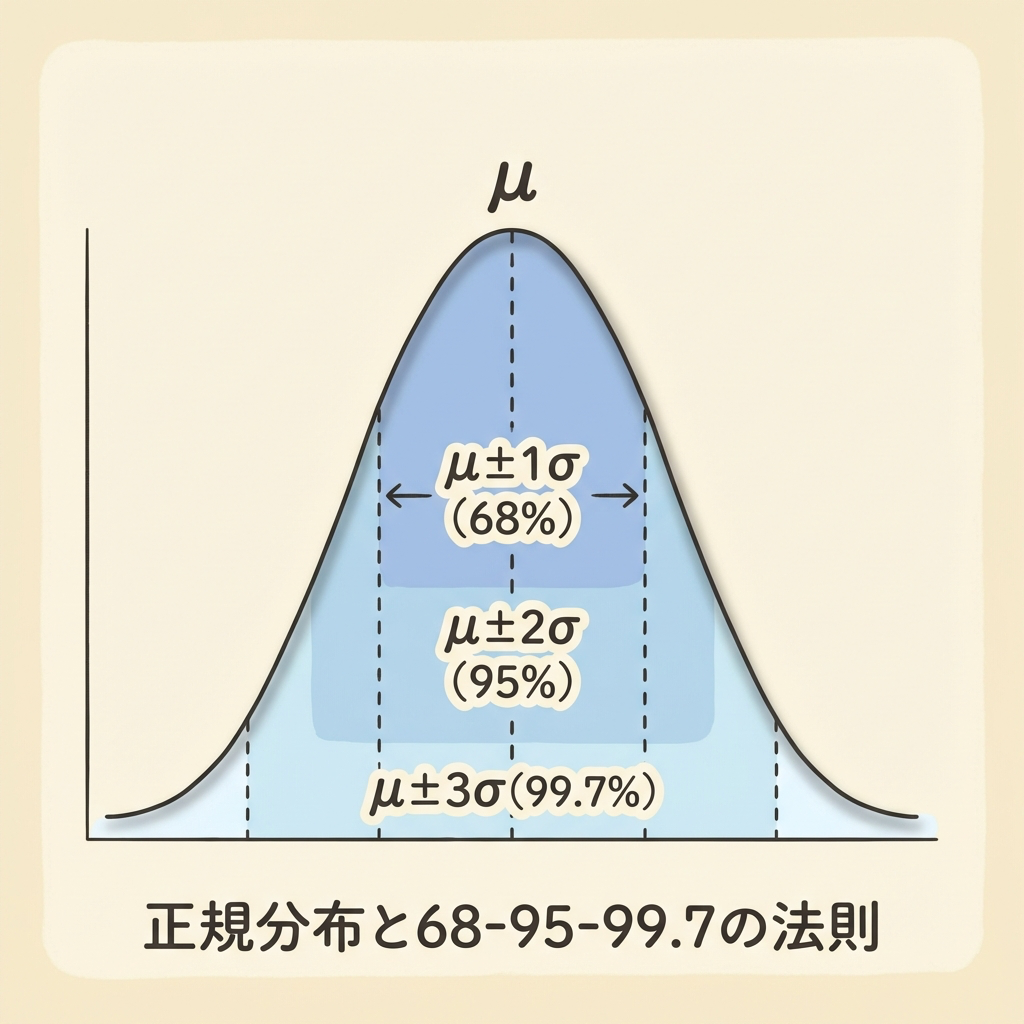
トピック②:確率分布(正規分布)|データの「形」を読む
大量のデータを集めてヒストグラム(棒グラフ)を描くと、特定の「形」が浮かび上がることがあります。この形を数式で表したものが確率分布です。その中でも最も重要なのが正規分布——あの左右対称の釣鐘型のグラフです。
正規分布の「68-95-99.7ルール」
正規分布は平均(μ)を中心に左右対称に広がり、標準偏差(σ)でその「幅」が決まります。覚えるべきは次の3つの数字だけです。
| 範囲 | データが含まれる割合 | 例え |
|---|---|---|
| μ ± 1σ | 約68% | クラスの約7割がここに入る |
| μ ± 2σ | 約95% | ほとんどの人がここに入る |
| μ ± 3σ | 約99.7% | ほぼ全員がここに入る |
品質管理の「3σルール」をご存知の方は多いと思います。管理図で3σを超えた点は「異常」と判断しますよね。これはまさに「99.7%の範囲を外れた=通常ではありえない」という正規分布の性質を利用しています。
管理図・Cp/Cpk工程能力指数を完全理解 →
トピック③:母集団と標本|「全体」を「一部」から推測する
選挙の出口調査を思い出してください。投票した全員(数千万人)に聞くのは不可能なので、投票所を出てきた数千人に聞いて全体の結果を予測しますよね。
母集団
知りたい対象の「全体」。
例:日本の有権者全員
→ 全部調べるのは現実的に不可能
標本(サンプル)
母集団から「一部」を抜き取ったもの。
例:出口調査で聞いた3000人
→ ここから全体を推測する
「標本の取り方」が問われます。単純無作為抽出(くじ引きのようにランダムに選ぶ)、層別抽出(男女別・年代別にグループ分けしてから各グループから抽出)、多段抽出(地域→学校→クラスのように段階的に絞る)の3つの違いを理解しておきましょう。

{kind=link}
トピック④:推定と検定|「仮説は正しいか?」をデータで判断する
統計学の中でも、推定と検定は「データを使って意思決定をする」ための核心部分です。DS検定でも確実に出題される領域です。
推定|「母集団はこのくらいだろう」と範囲で予測する
体温計に例えてみましょう。体温計が「36.5℃」と表示しても、本当の体温がピッタリ36.5℃である保証はありません。実際は「36.3〜36.7℃くらいだろう」と幅を持たせて予測する——これが区間推定の考え方です。
・点推定:「36.5℃です」(1つの値で推定)
・区間推定:「36.3〜36.7℃の間です」(幅を持たせて推定)
・信頼区間:その「幅」のこと
・信頼度95%:「同じ方法で100回やったら、95回はこの範囲に真の値が含まれる」という意味
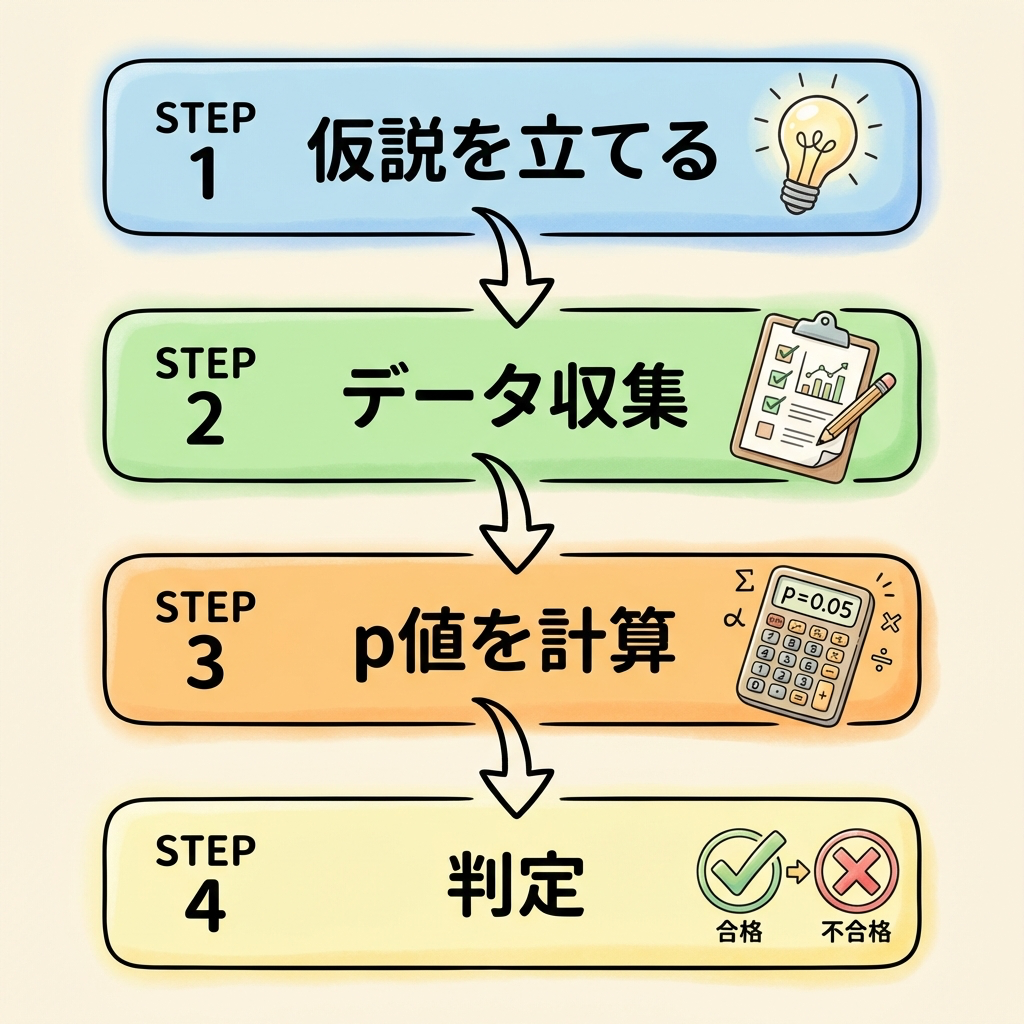
仮説検定|「差があるのか、偶然なのか」を判定する
新しい薬を開発したとき、「この薬は本当に効くのか?それともたまたま良くなっただけ?」を判断したいですよね。この「偶然か、本物の差か」を統計的に判断する仕組みが仮説検定です。
帰無仮説(H₀)を立てる:「差はない」「効果はない」と仮定する
データを集めて検定統計量を計算する
p値を確認:「偶然でこの結果が出る確率」
判定:p値 < 0.05 なら「偶然とは考えにくい」→ 帰無仮説を棄却(=差がある)
検定の「計算」は求められませんが、「帰無仮説と対立仮説の違い」「p値の意味」「第一種の過誤(αエラー)と第二種の過誤(βエラー)」の理解は問われます。特に「p値が0.05未満 = 差がある、と断定してよい」は誤りであることに注意(あくまで"偶然とは考えにくい"程度の意味)。
検定の選び方|仮説検定の全体像をわかりやすく解説 →
自由度とは?統計学でつまずきやすいポイントを図解 →
トピック⑤:条件付き確率とベイズの定理|「新情報」で確率を更新する
条件付き確率|「〇〇を知った上で、△△の確率は?」
天気予報で考えてみましょう。「明日、雨が降る確率は30%」。でも、「今夜、西の空に厚い雲が出てきた」と知ったら、確率はもっと上がりますよね?追加情報を得た上での確率、これが条件付き確率です。
P(A|B)
「Bが起きたという条件のもとで、Aが起きる確率」と読みます。
"|"は「〜という条件のもとで」という意味です。
ベイズの定理|「原因の確率」を「結果」から逆算する
ベイズの定理は、条件付き確率を「ひっくり返す」公式です。
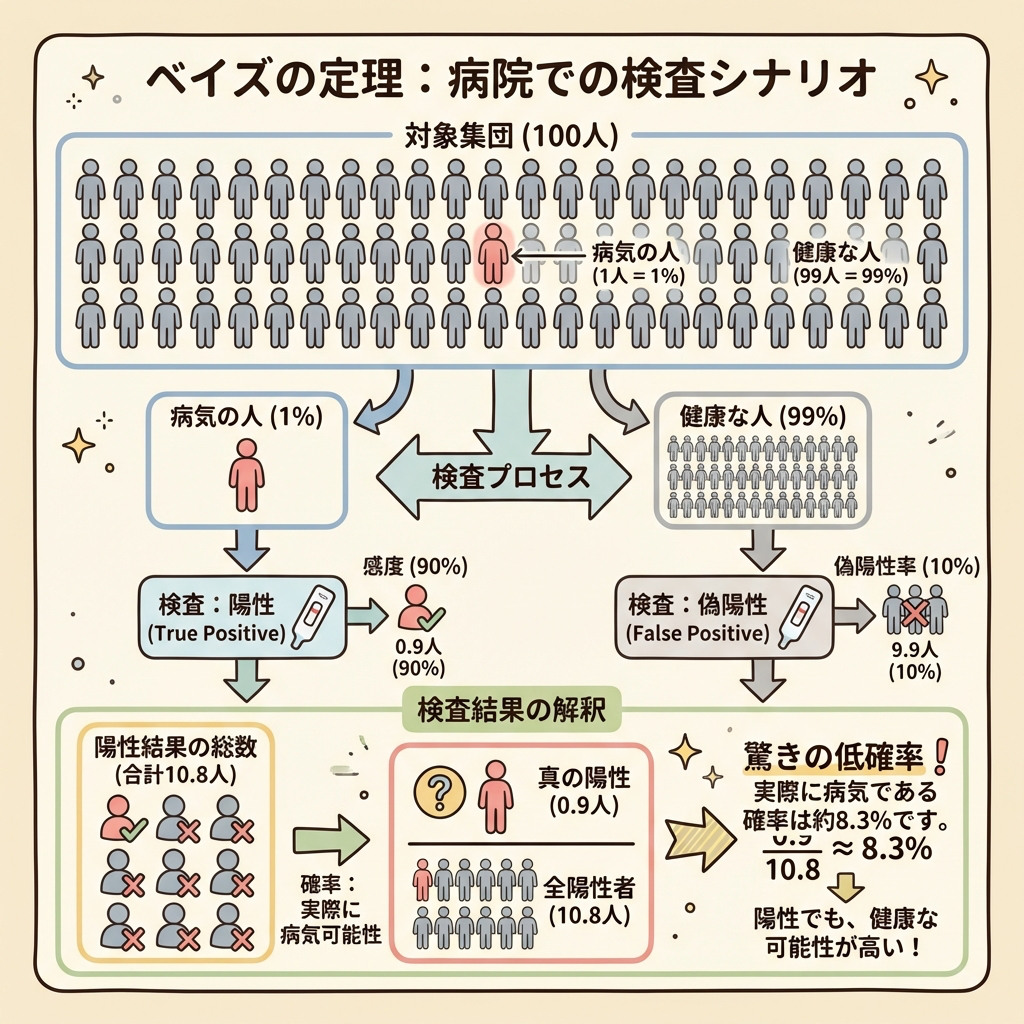
病院の検査で例えましょう。
🏥 ベイズの定理を「健康診断」で理解する
・ある病気にかかっている人は全体の1%(事前確率)
・検査の精度:病気の人が陽性になる確率 = 90%
・健康な人が誤って陽性になる確率 = 5%
質問:検査で陽性が出た。本当に病気である確率は?
直感では「90%?」と思いがちですが、ベイズの定理で計算すると約15.4%にしかなりません。なぜなら、そもそも病気の人が1%しかいないため、「健康なのに陽性と出た人」の方が圧倒的に多いからです。
P(A|B) = P(B|A) × P(A) ÷ P(B)
・P(A):事前確率(情報を得る前の確率)
・P(B|A):尤度(Aが本当のとき、Bが観測される確率)
・P(B):Bが観測される全体の確率
・P(A|B):事後確率(Bを観測した後の確率)
ベイズの公式を使って数値を計算する問題は少ないです。「事前確率と事後確率の違い」「ベイズ更新の考え方」「尤度の意味」を概念として理解しているかが問われます。迷惑メールフィルターやスパム検出がベイズの代表的な応用例として出題されることもあります。
トピック⑥:相関と因果|「一緒に動く」と「原因→結果」は全く別のこと
DS検定で最も出題頻度が高いトピックの一つです。DS検定対策サイト(GRI)でも「相関と因果の問題は頻出」と明記されています。
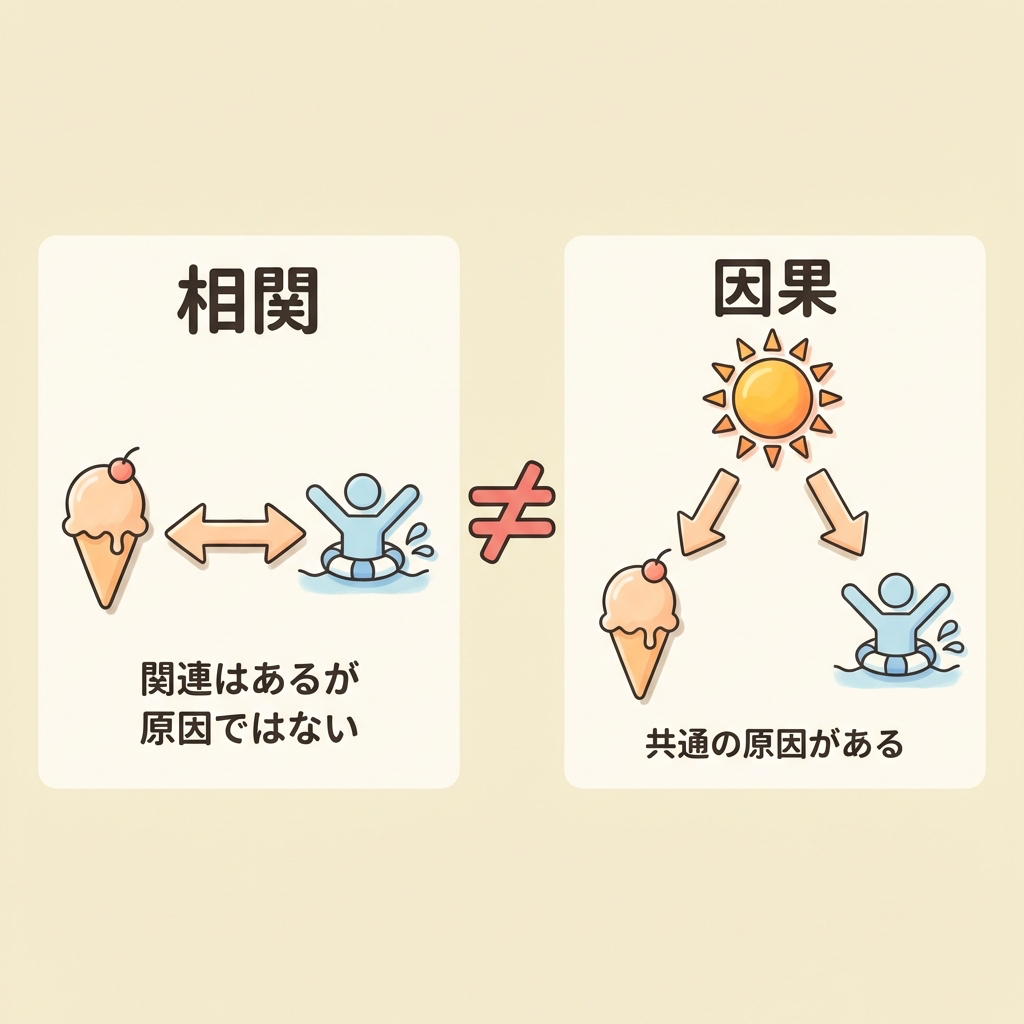
相関 ≠ 因果|アイスと水難事故の関係
有名な例です。「アイスクリームの売上が増えると、水難事故が増える」——これは事実です。統計的に相関があります。
では、「アイスの売上を減らせば水難事故が減る」のでしょうか?もちろん違いますよね。
アイスの売上 ←気温(交絡因子)→ 水難事故
↑ これが擬似相関(見せかけの相関)の正体
| 用語 | 意味 | 例え |
|---|---|---|
| 相関 | 2つのデータが一緒に動く傾向がある | 身長と靴のサイズ(一緒に大きくなる) |
| 因果 | 一方がもう一方の原因である | 勉強時間が増える → テストの点が上がる |
| 擬似相関 | 因果はないのに相関があるように見えている | アイス売上 ↔ 水難事故(気温が原因) |
| 交絡因子 | 両方に影響を与えている隠れた第3の変数 | 上の例では「気温」が交絡因子 |
相関係数|「どのくらい一緒に動くか」を数値化する
相関の強さを-1〜+1の数値で表したものが相関係数(r)です。
| 相関係数 r | 解釈 |
|---|---|
| r = +1 | 完全な正の相関(片方が増えると、もう片方も必ず増える) |
| r = 0 | 相関なし(2つのデータに関連がない) |
| r = −1 | 完全な負の相関(片方が増えると、もう片方は必ず減る) |
「相関があるからといって、因果があるとは限らない」——このフレーズはDS検定の選択肢で何度も出てきます。「相関=因果」と短絡的に結びつけるのは統計学における最大の誤りです。必ず「交絡因子がないか?」を確認する姿勢が求められます。

トピック⑦:データの可視化と誤読防止|グラフの「嘘」を見抜く
DS検定のモデルカリキュラムに「不適切なグラフ表現(チャートジャンク、不必要な視覚的要素)」とあります。つまり、「騙すためのグラフ」を見抜けるか?が問われます。
| ダメなグラフ | 何が問題か | 例え |
|---|---|---|
| Y軸が0から始まらない | わずかな差が大きく見える | 売上100→101を、100倍に見せる |
| 3Dグラフ | 奥行きで面積が歪み、比較が困難 | 円グラフの3Dは割合がわからない |
| 2軸グラフの悪用 | スケールが違うのに重ねて因果を匂わせる | コーヒーの消費量と犯罪率の推移 |
「グラフを見たら、まずY軸の起点を確認する」「3Dグラフは原則的に避けるべき」「相関を見せるだけのグラフで因果を主張してはいけない」——これらは実務でもデータサイエンスの基本マナーです。
まとめ|統計は「DS検定最大の得点源」になる
| トピック | 核心キーワード | 深掘り記事 |
|---|---|---|
| ①代表値とバラつき | 平均・中央値・分散・標準偏差 | 分散・標準偏差を図解 → |
| ②確率分布 | 正規分布・68-95-99.7ルール | 管理図・Cp/Cpkで応用理解 → |
| ③母集団と標本 | サンプリング・無作為抽出 | 抜取検査で抽出を理解 → |
| ④推定と検定 | 帰無仮説・p値・信頼区間 | 検定の選び方を図解 → |
| ⑤ベイズの定理 | 事前確率・事後確率・尤度 | 自由度から確率の基礎へ → |
| ⑥相関と因果 | 擬似相関・交絡因子・相関係数 | 実験計画法で因果を学ぶ → |
| ⑦可視化と誤読 | チャートジャンク・Y軸の罠 | (今後公開予定) |
統計は範囲が広く見えますが、DS検定で問われるのは「概念の理解」と「用語の正しい解釈」です。複雑な計算が求められるわけではありません。
この記事で全体像を掴み、各詳細記事で理解を深める——この「マップ&深掘り」の流れで進めれば、統計分野は確実に得点源にできます。
📚 次に読むべき記事
DS検定の全体像を再確認したい方へ。
統計と合わせて押さえるべき数学の基礎はこちら。
統計の最重要概念をゼロから学べます。