
- 「前処理が8割」と聞くけど、具体的に何をすればいいのかわからない
- 欠損値は「削除」と「補完」のどちらが正解?判断基準がわからない
- 「標準化」と「正規化」の違いが曖昧で、DS検定の選択肢で迷う
- 「ワンホットエンコーディング」「ラベルエンコーディング」の使い分けが不明
- 特徴量エンジニアリングという言葉は知っているが、何をすることなのか具体的にイメージできない
- データ前処理の全体像と「なぜ必要か」
- 欠損値処理の4つの方法と使い分けフローチャート
- 外れ値・異常値の検出方法(IQR法・3σ法)
- 標準化(Z-score)と正規化(Min-Max)の違いと使い分け
- カテゴリ変数のエンコーディング(ワンホット・ラベル・ターゲット)
- 特徴量エンジニアリングの代表的テクニック
- DS検定で問われるポイントの総整理
データサイエンスの世界には「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」という有名な格言があります。どんなに優れた機械学習モデルを使っても、入力するデータが汚れていれば結果は信頼できません。
DS検定のスキルチェックリストでも、★(見習いレベル)で「基本統計量や分布の確認、および前処理(外れ値・異常値・欠損値の除去・変換や標準化など)」が明記されています。前処理は試験でも実務でも避けて通れない最重要スキルです。
この記事では、前処理の各手法を「なぜ必要か」→「何をするか」→「どう使い分けるか」の流れで解説します。数式はほとんど使わず、たとえ話と図解でイメージを掴めるようにしています。
DS検定で問われる機械学習の基礎|教師あり/なし・過学習・評価指標を完全図解 →
目次
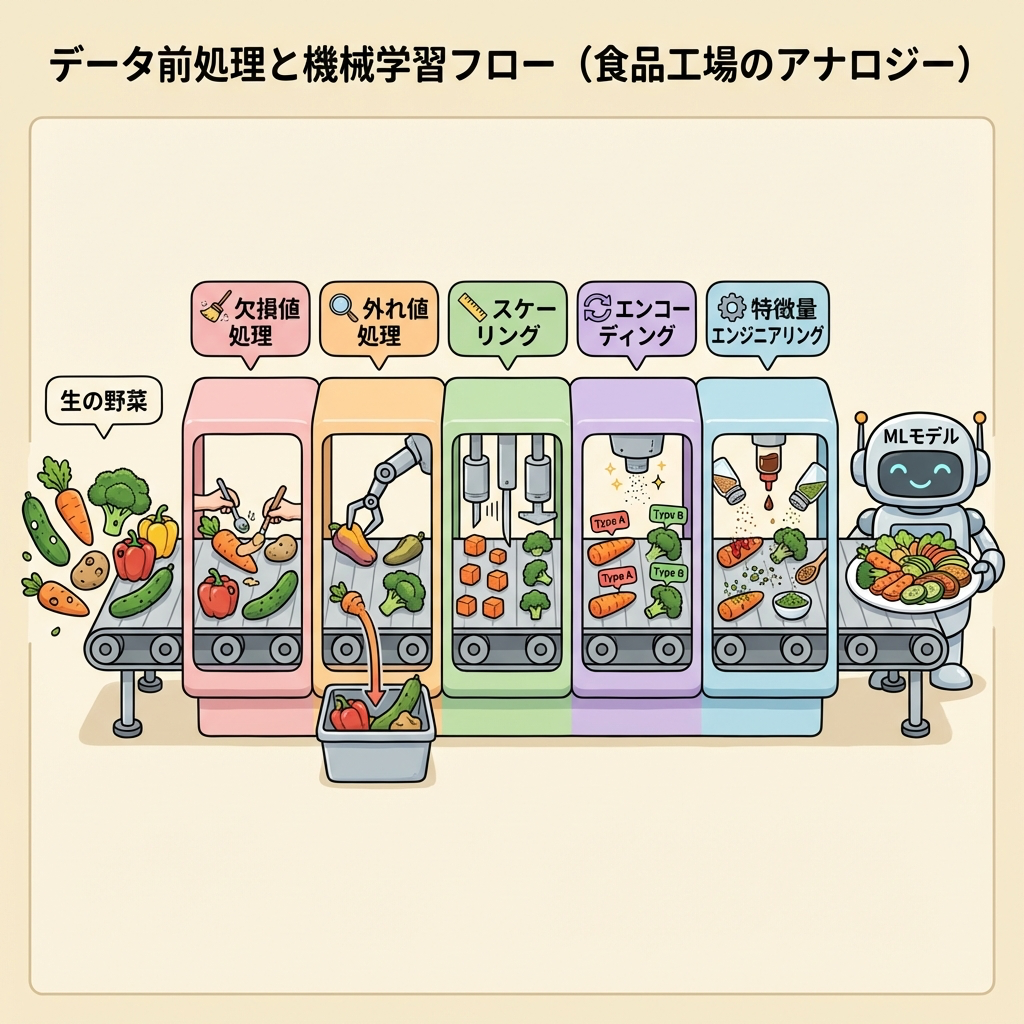
データ前処理の全体像|「料理の下ごしらえ」
データ前処理とは、生データを機械学習モデルが正しく学習できる状態に整える作業の総称です。一般に、データ分析プロジェクトの作業時間の60〜80%を占めると言われています。
スーパーで買ってきた野菜をそのまま鍋に放り込む人はいません。泥を落とし(データクレンジング)、腐った部分を取り除き(外れ値・欠損値処理)、食べやすい大きさに切り(スケーリング・変換)、調味料で味付けする(特徴量エンジニアリング)。この下ごしらえなしに美味しい料理(高精度なモデル)は作れません。
前処理の全体フロー
それぞれのステップを順番に解説していきます。

欠損値(Missing Value)処理|「穴のあいたアンケート」をどうするか
欠損値とは、データの中に「値がない」セルのことです。アンケートの未回答、センサーの故障、入力ミスなど、現実のデータには必ず欠損値が含まれます。
健康診断の結果表で「血圧」の欄が空白の人がいたとします。この空白を無視すると、平均血圧の計算がおかしくなるかもしれません。かといって、その人のデータを丸ごと捨てると、他の項目(身長、体重など)の貴重な情報も失われます。
欠損値処理とは、「この空白をどう扱うか」を合理的に判断する技術です。
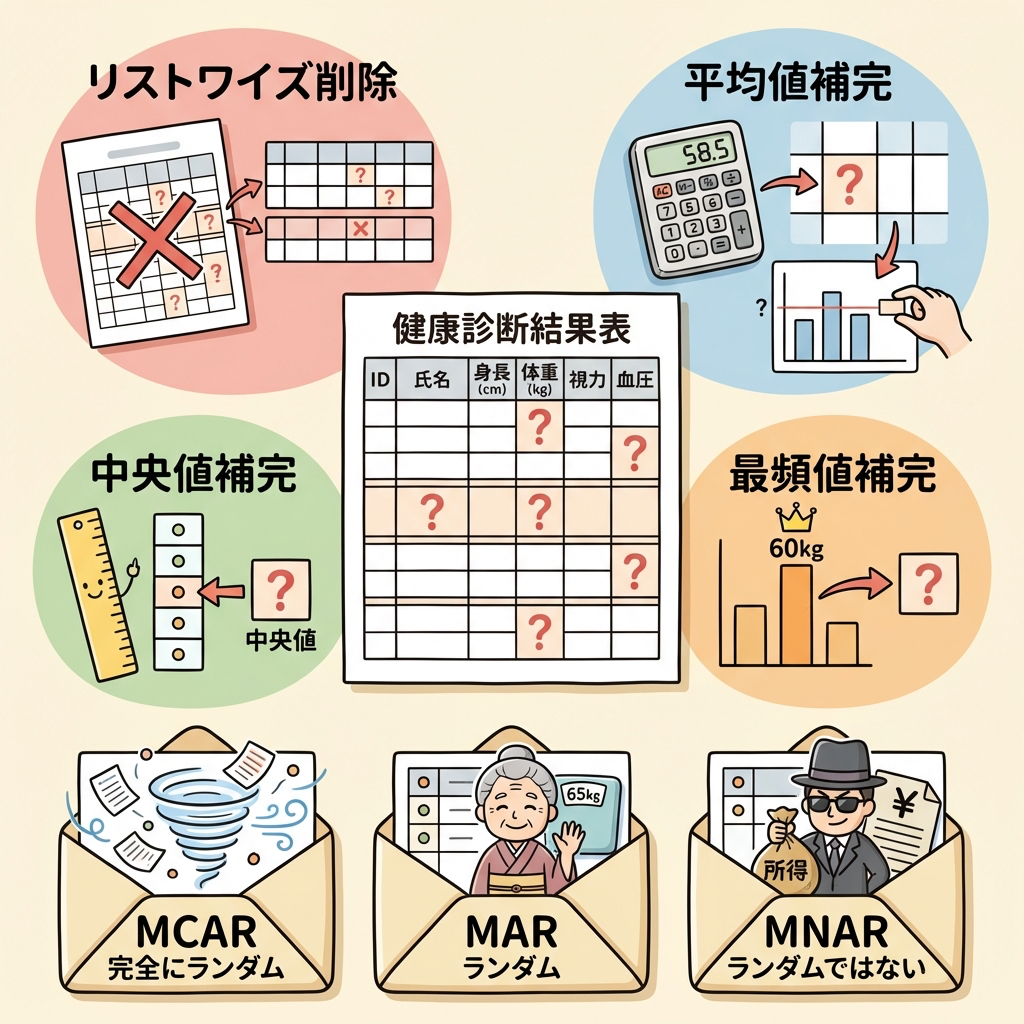
欠損値処理の4つの方法
| 方法 | やること | メリット | デメリット |
|---|---|---|---|
| リストワイズ削除 | 欠損値を含む行(レコード)ごと削除する | 最もシンプル | データ量が大幅に減る可能性。欠損がランダムでないと偏りが生じる |
| 平均値補完 | 欠損値をその列の平均値で埋める | データ量が減らない。平均がズレない | 分散(バラつき)が小さくなる。外れ値の影響を受ける |
| 中央値補完 | 欠損値をその列の中央値で埋める | 外れ値の影響を受けにくい | 平均値補完と同様、分散が小さくなる |
| 最頻値補完 | 欠損値を最も多い値で埋める | カテゴリ変数にも使える | 特定の値の割合が増えすぎる |
数値データの欠損:平均値 or 中央値で補完(外れ値が多いなら中央値が安全)
カテゴリデータの欠損:最頻値で補完
欠損率が非常に高い列(例:80%以上が欠損):列ごと削除を検討
データ量が十分に多い:リストワイズ削除でもOK
欠損のパターン|MCAR・MAR・MNAR
DS検定ではさらに「欠損が起きる理由」のパターンが問われることがあります。
| 略称 | 正式名 | 意味とたとえ話 |
|---|---|---|
| MCAR | Missing Completely At Random | 完全にランダムに欠損。アンケート用紙がたまたま風で飛んだ。データの他の値と一切関係ない |
| MAR | Missing At Random | 他の変数に依存して欠損。高齢者ほど「体重」を答えたがらない。「年齢」の情報があれば欠損の傾向を説明できる |
| MNAR | Missing Not At Random | 欠損値自体に意味がある。年収が高い人ほど「年収」欄を空欄にする。欠損の理由が、まさにその変数自身の値に依存 |
「MCARの場合、リストワイズ削除を行っても分析結果に偏りは生じない」→ 正しい(完全にランダムだから)
「MNARの場合、欠損自体が情報を含むため、単純な削除や補完では偏りが生じる」→ 正しい
この2つは頻出です。
外れ値・異常値の検出と処理|「身長300cmのデータ」をどうするか
外れ値(Outlier)とは、他のデータから大きく離れた異常な値のことです。入力ミス、計測エラー、あるいは本当に珍しいケースなど原因は様々です。
30人のクラスで平均身長を計算しています。29人が155〜175cmなのに、1人のデータが「300cm」。これは明らかに入力ミスです。このまま計算すると平均身長が大きくズレてしまいます。
しかし注意が必要です。「年収」のデータで1人だけ年収1億円の人がいた場合、それは入力ミスではなく本物の外れ値かもしれません。外れ値を「消すべきか」「残すべきか」は文脈によって判断が異なります。
外れ値の検出方法
| 方法 | やり方 | 特徴 |
|---|---|---|
| IQR法(四分位範囲法) | Q1 - 1.5×IQR より小さい、または Q3 + 1.5×IQR より大きいデータを外れ値とする | 正規分布を仮定しない。箱ひげ図と連動。DS検定で最頻出 |
| 3σ法(zスコア法) | 平均から標準偏差の3倍以上離れたデータを外れ値とする | 正規分布を仮定。データが正規分布に近い場合に有効 |
| 箱ひげ図(Box Plot) | IQR法を視覚的に表現したグラフ。「ヒゲ」の外にある点が外れ値 | 外れ値を一目で発見できる。探索的データ分析(EDA)の基本ツール |
① データを小さい順に並べる
② 第1四分位数(Q1:下から25%の位置)と第3四分位数(Q3:下から75%の位置)を求める
③ IQR = Q3 - Q1(四分位範囲)を計算
④ 下限 = Q1 - 1.5 × IQR、上限 = Q3 + 1.5 × IQR を計算
⑤ 下限より小さい、または上限より大きいデータが外れ値
外れ値を見つけたらどうする?
| 対処法 | やること | 使う場面 |
|---|---|---|
| 削除 | 外れ値のデータを取り除く | 明らかな入力ミス・計測エラーの場合 |
| クリッピング(ウィンザライズ) | 外れ値を上限値・下限値に置き換える | 「本物の外れ値だが極端な影響を抑えたい」場合 |
| 対数変換 | データ全体にlog変換を適用し、スケールを圧縮する | 年収など右に裾が長い分布(右スキュー)の場合 |
| そのまま残す | 外れ値が分析対象そのものの場合 | 不正検知(外れ値=不正取引)の場合 |
「外れ値は常に削除すべきか?」→ No。分析目的によって判断する。不正検知では外れ値こそが分析対象
「IQR法で外れ値と判定される基準は?」→ Q1 - 1.5×IQR 未満、または Q3 + 1.5×IQR を超えるデータ


{kind=link}
標準化と正規化の違い|「単位のバラバラな成績表」を揃える
機械学習では複数の特徴量を同時に使いますが、特徴量ごとにスケール(値の範囲)がバラバラだと問題が起きます。例えば「年齢(0〜100)」と「年収(0〜10,000,000)」を同時に使う場合、年収の方が圧倒的に数値が大きいため、モデルが年収の影響を過大に評価してしまいます。
身長170cmと体重60kgを足して「230点!」としても意味がありません。身長のほうが数値が大きいので、身長が高い人ばかりが有利になります。スケーリングとは、異なる単位のデータを「同じ土俵」に揃える作業です。
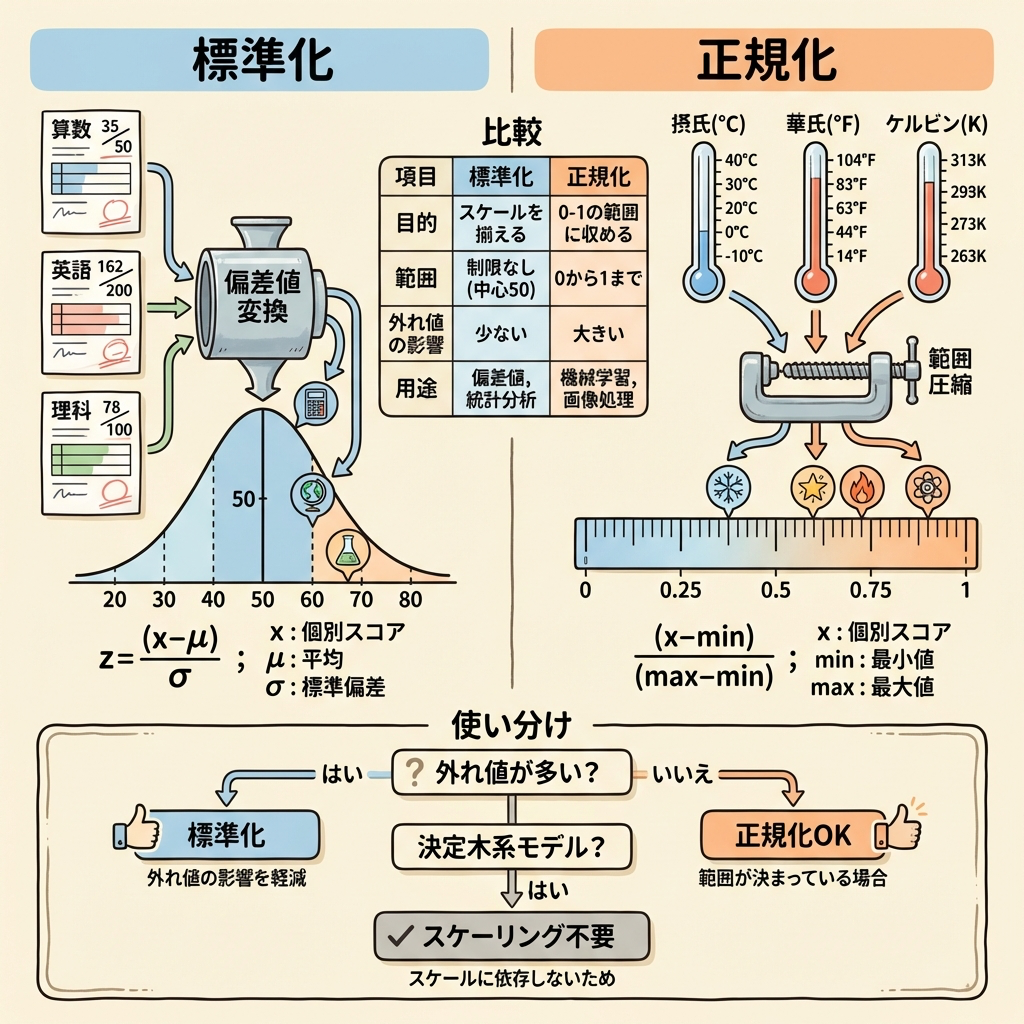
標準化(Standardization / Z-score変換)
結果:平均0、標準偏差1の分布に変換される
受験で使う「偏差値」は標準化の身近な例です。科目ごとに平均点も難易度もバラバラですが、偏差値にすれば「平均が50、標準偏差が10」という共通の基準で比較できます。標準化はまさにこの「偏差値化」を行う操作です。
正規化(Normalization / Min-Maxスケーリング)
結果:すべてのデータが0〜1の範囲に収まる
英語のテストは200点満点、数学は50点満点だとします。そのまま比較はできませんが、「全教科を100点満点に換算」すれば比較できます。正規化はこの「最低点を0、最高点を1に揃える」操作です。
標準化 vs 正規化の使い分け
| 比較項目 | 標準化(Z-score) | 正規化(Min-Max) |
|---|---|---|
| 変換後の範囲 | 平均0、標準偏差1(範囲は不定) | 0〜1 |
| 外れ値の影響 | 受けにくい | 受けやすい(minやmaxが外れ値だとスケールが崩れる) |
| 向いているモデル | SVM、ロジスティック回帰、PCA | ニューラルネットワーク、k-NN |
| 覚え方 | 「偏差値化」 | 「100点満点への換算」 |
「標準化と正規化の違いは?」はDS検定の定番問題です。
標準化:平均0、標準偏差1に変換。外れ値に強い
正規化:0〜1に変換。外れ値に弱い
「決定木やランダムフォレストはスケーリング不要」も覚えておきましょう。木ベースのモデルは分割ルールで動作するため、スケールの影響を受けません。
分散と標準偏差|「バラつき」を数値化する魔法の公式 →
カテゴリ変数のエンコーディング|「文字」を「数字」に変換する
機械学習モデルは数値しか扱えません。「性別(男/女)」「都道府県(東京/大阪/愛知…)」のようなカテゴリ変数は、そのままではモデルに入力できないため、数値に変換する必要があります。この変換操作をエンコーディングと呼びます。
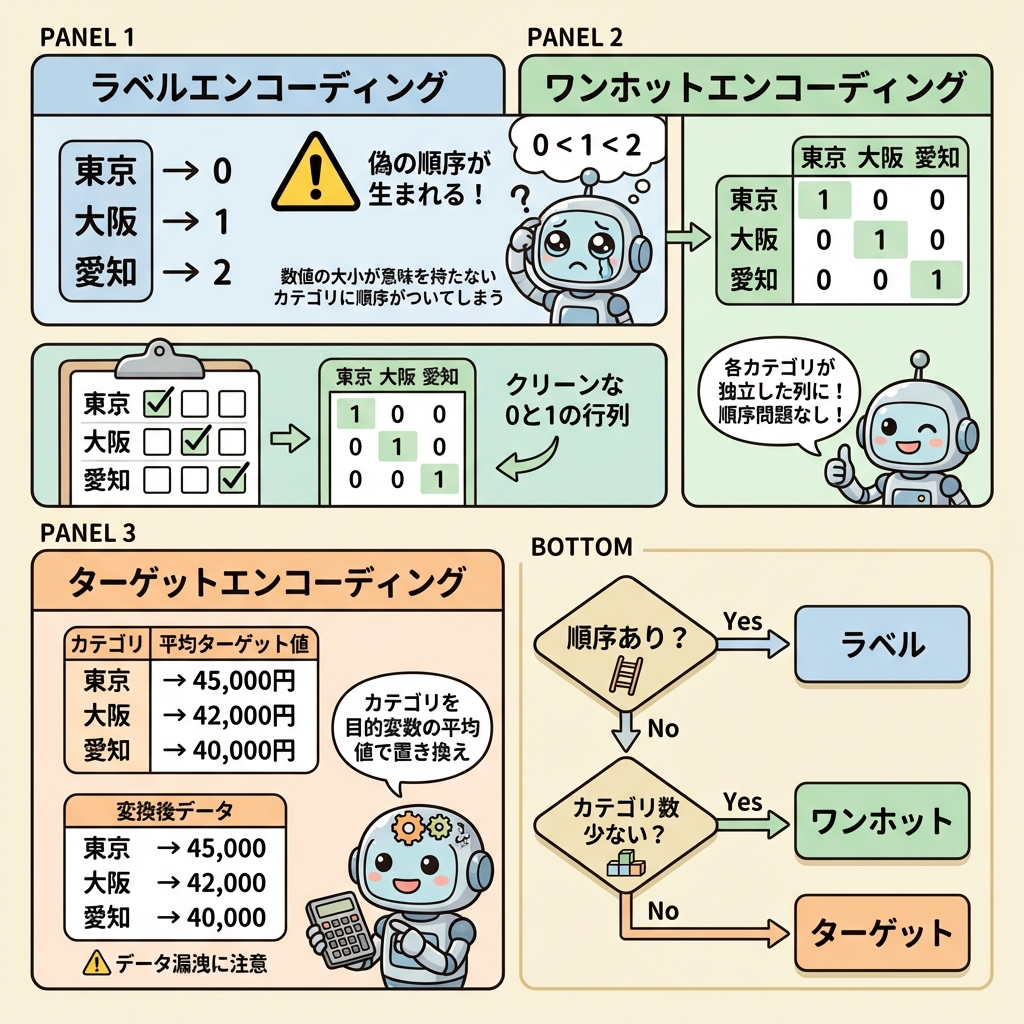
① ラベルエンコーディング(Label Encoding)
カテゴリに整数の連番を割り当てる方法です。「東京→0、大阪→1、愛知→2」のように変換します。
| 変換前 | 変換後 |
|---|---|
| 東京 | 0 |
| 大阪 | 1 |
| 愛知 | 2 |
数字に変換すると、モデルが「東京(0) < 大阪(1) < 愛知(2)」という大小関係があると誤解する可能性があります。本来、都道府県に順序はないので、この変換は「順序のないカテゴリ」には不適切です。
ラベルエンコーディングが適切なのは「低・中・高」「小学生・中学生・高校生」のように順序があるカテゴリだけです。
② ワンホットエンコーディング(One-Hot Encoding)
カテゴリの数だけ新しい列(ダミー変数)を作り、該当するカテゴリの列だけ1、それ以外を0にする方法です。順序がないカテゴリに最適です。
| 元データ | 東京 | 大阪 | 愛知 |
|---|---|---|---|
| 東京 | 1 | 0 | 0 |
| 大阪 | 0 | 1 | 0 |
| 愛知 | 0 | 0 | 1 |
複数の選択肢がある質問で「あてはまるものに✓を入れてください」というチェックシートと同じ発想です。「東京に住んでいる→東京欄に✓」「大阪に住んでいる→大阪欄に✓」。✓がついた列が1、ついていない列が0です。
3カテゴリ(東京・大阪・愛知)をワンホットすると3列できますが、実は2列で十分です。「東京=0, 大阪=0」なら自動的に「愛知」とわかるからです。3列すべて使うと列同士が完全に相関し(多重共線性)、回帰モデルなどで問題が起きます。これをダミー変数トラップと呼びます。
エンコーディングの使い分けまとめ
| 手法 | 適切な場面 | 注意点 |
|---|---|---|
| ラベルエンコーディング | 順序があるカテゴリ(低/中/高) 決定木系モデル |
順序なしカテゴリに使うと偽の大小関係が生じる |
| ワンホットエンコーディング | 順序がないカテゴリ(性別、都道府県) 線形モデル・NN |
カテゴリ数が多いと列が爆発する(次元の呪い)。ダミー変数トラップに注意 |
| ターゲットエンコーディング | カテゴリ数が非常に多い場合 | 目的変数の平均値で置換。過学習のリスクがある |
特徴量エンジニアリング|「原石を宝石に磨く」技術
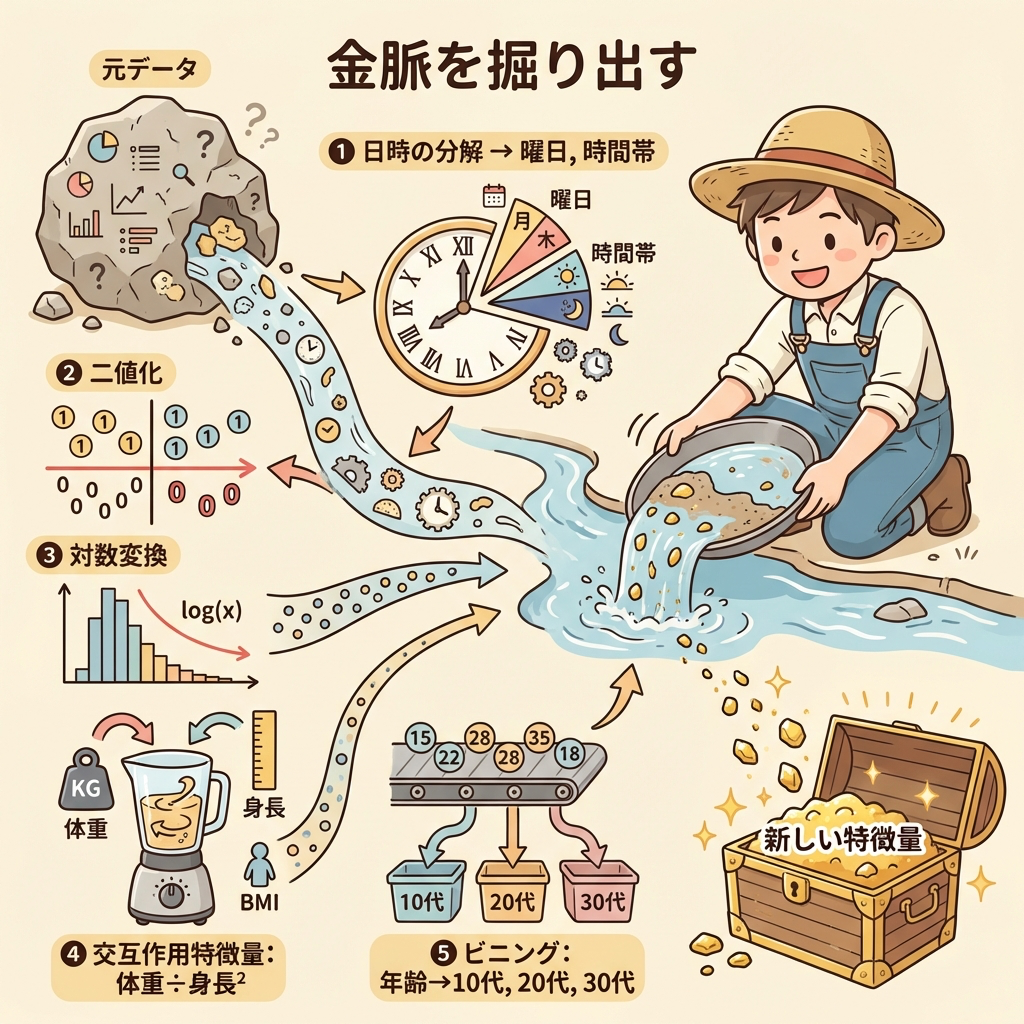
特徴量エンジニアリング(Feature Engineering)とは、モデルの予測精度を上げるために、既存のデータから新しい「特徴量(列)」を作成する技術です。前処理が「データを綺麗にする」作業だとすれば、特徴量エンジニアリングは「データから金脈を掘り出す」作業です。
履歴書に「生年月日:1993年5月15日」と書いてあります。この情報から、直接書かれていない「年齢」「星座」「入社時の年齢」などを計算で導き出せます。元データにはなかった新しい列を作るのが特徴量エンジニアリングです。
代表的な特徴量エンジニアリングのテクニック
| テクニック | やること | 具体例 |
|---|---|---|
| 日時の分解 | 日時データから「年」「月」「曜日」「時間帯」などを抽出 | 購買日時 → 「土日フラグ」「午前/午後」「月末フラグ」 |
| 二値化(Binarization) | 数値をある閾値で「0 or 1」に変換 | 年収 → 「500万円以上なら1、未満なら0」 |
| 対数変換(Log変換) | 右に裾が長い分布を対数で圧縮して正規分布に近づける | 年収、人口、PVなど「桁がバラバラ」なデータ |
| ビニング(離散化) | 連続値をいくつかの区間に分割してカテゴリ化 | 年齢 → 「10代」「20代」「30代」… |
| 交互作用特徴量 | 2つ以上の特徴量を掛け算・割り算して新しい特徴量を作成 | 体重 ÷ 身長² = BMI(身長と体重の交互作用) |
| 集約特徴量 | グループごとの平均、合計、最大値などを新しい特徴量にする | 「顧客ID」ごとの「過去3ヶ月の購入回数」「平均購入金額」 |
| テキスト特徴量 | テキストから数値的な特徴を抽出 | 「メール本文の文字数」「感嘆符の数」「URLの有無」 |
良い特徴量とは、「目的変数(予測したいもの)と強い関係を持つ」列です。例えば「住宅価格を予測するモデル」に「住所」というテキストをそのまま入れても役に立ちません。しかし「住所」から「最寄り駅までの距離」を計算して列を作れば、強力な特徴量になります。
「どんなデータがあれば予測に役立つか?」をドメイン知識(業務知識)で考えることが、特徴量エンジニアリングの本質です。

データリーケージ|「未来の答えをカンニングする」致命的ミス
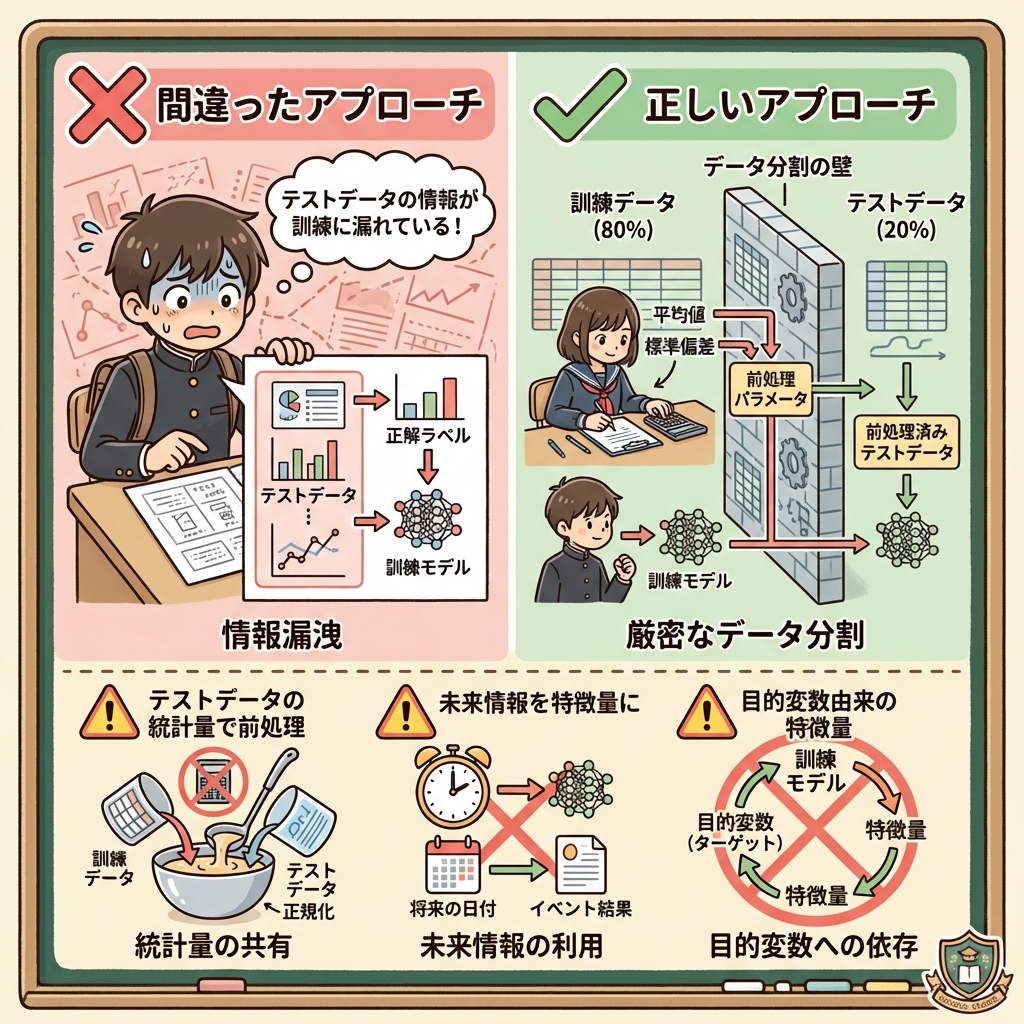
前処理に関連して、DS検定で出題される重要な概念がデータリーケージ(Data Leakage)です。これは、学習時に「本来使ってはいけない情報」が紛れ込むことで、モデルの評価が不正に高くなってしまう現象です。
試験の前に「答え」をチラッと見てしまった受験生は、そのテストで高得点を取れます。しかし、本当の実力ではありません。別のテストを受けたら惨敗します。
データリーケージもこれと同じです。訓練データにテストデータの情報が漏れ込むと、訓練時の精度は高くなりますが、未知のデータでは通用しません。
リーケージが起きる代表的なパターン
| パターン | 何が起きるか | 防ぎ方 |
|---|---|---|
| 前処理でテストデータの情報を使う | 全データの平均値で欠損補完→テストデータの情報が訓練に混入 | 訓練データのみで平均値・標準偏差を計算し、その値でテストデータも変換する |
| 未来の情報を特徴量にする | 「翌月の売上」を予測するのに「翌月のアクセス数」を特徴量にしてしまう | 予測時点で手に入るデータのみを特徴量にする |
| 目的変数と直接つながる特徴量 | 「退職したか」を予測するのに「退職日」を特徴量にしてしまう | 目的変数から派生した列を除外する |
「標準化は訓練データとテストデータのどちらで計算すべきか?」→ 訓練データのみで平均と標準偏差を計算し、その値をテストデータにも適用する
「なぜ全データで標準化してから分割してはいけないのか?」→ テストデータの情報が訓練に漏れる(リーケージ)
前処理の判断フローチャート|「何をすればいい?」を一発解決
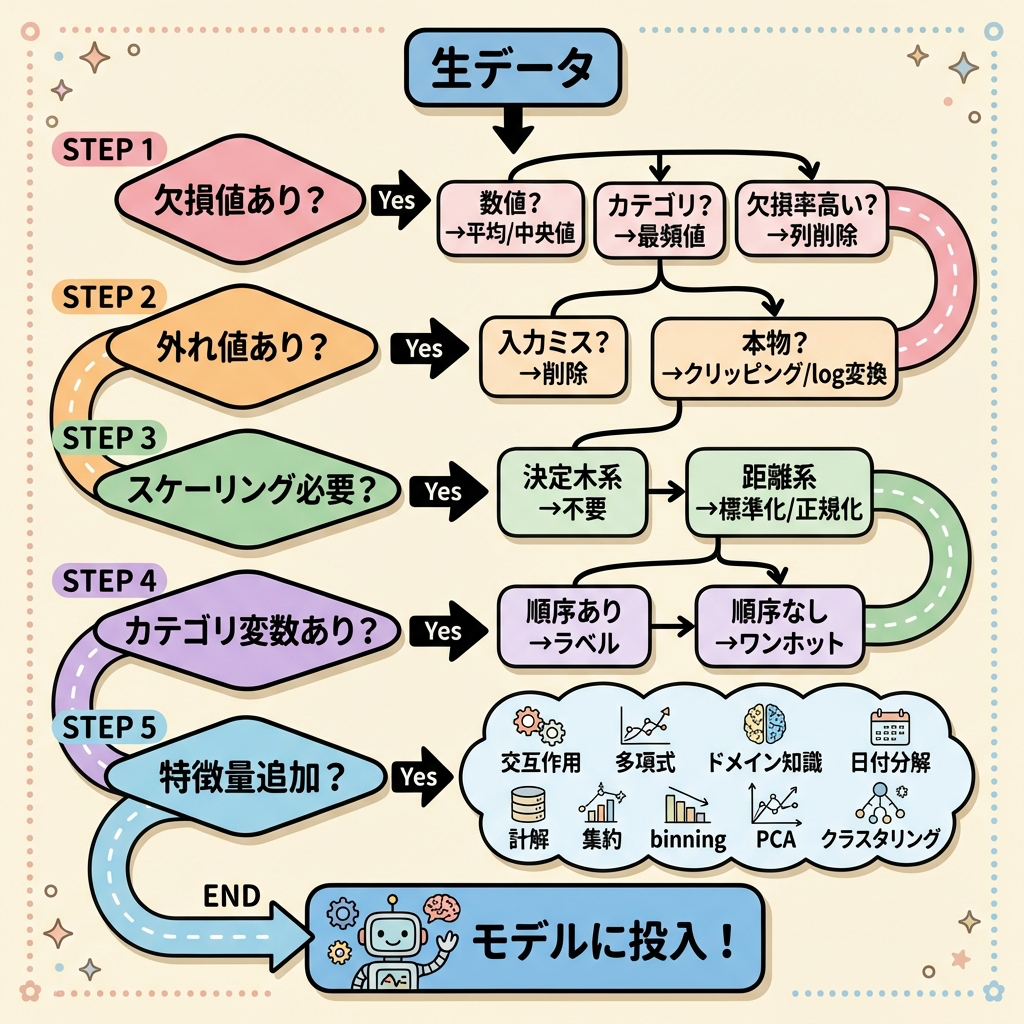
ここまで学んだ前処理手法をフローチャート形式で整理します。DS検定でも実務でも、「このデータにはどの前処理をすべきか?」を素早く判断できるようにしておきましょう。
各列の欠損率を確認 → 欠損率が高すぎる列は削除を検討 → 数値列は平均値/中央値で補完 → カテゴリ列は最頻値で補完
箱ひげ図やヒストグラムで分布を可視化 → IQR法で外れ値を検出 → 入力ミスなら削除 → 本物の外れ値ならクリッピングまたは対数変換
モデルに距離計算が含まれるか確認(SVM, k-NN, NN, 回帰 → 必要 / 決定木系 → 不要)→ 外れ値が多い場合は標準化 → 外れ値が少ない場合は正規化でもOK
カテゴリ変数の有無を確認 → 順序あり:ラベルエンコーディング → 順序なし:ワンホットエンコーディング → カテゴリ数が多い:ターゲットエンコーディングを検討
日時データ → 曜日・時間帯を抽出 / 数値データ → 対数変換・二値化・ビニング / 複数列の組み合わせ → 交互作用特徴量を作成
① 前処理は必ず訓練データだけで統計量(平均、標準偏差、min、max)を計算し、テストデータにはその値を適用する(リーケージ防止)
② 決定木系モデル(ランダムフォレスト、XGBoost等)はスケーリング不要(分割ルールで動作するため)
③ 外れ値は「削除」が常に正解ではない。分析目的に応じて判断する

DS検定で問われる前処理の出題パターン総まとめ
| 出題パターン | 押さえるべきポイント |
|---|---|
| 「欠損値処理の方法と使い分け」 | リストワイズ削除、平均値/中央値/最頻値補完。数値は平均or中央値、カテゴリは最頻値 |
| 「MCAR・MAR・MNARの違い」 | MCARは完全ランダム(削除OK)。MNARは欠損自体に意味がある(単純削除は危険) |
| 「外れ値の検出方法」 | IQR法(Q1-1.5×IQR〜Q3+1.5×IQR)。箱ひげ図で可視化。3σ法は正規分布仮定 |
| 「標準化と正規化の違い」 | 標準化:平均0・標準偏差1(外れ値に強い)。正規化:0〜1(外れ値に弱い) |
| 「スケーリングが不要なモデル」 | 決定木、ランダムフォレスト、XGBoost(木ベースのモデル) |
| 「ワンホットエンコーディングの注意点」 | ダミー変数トラップ(n-1列にすべき)。カテゴリ数が多いと次元爆発 |
| 「ラベルエンコーディングの適切な場面」 | 順序があるカテゴリのみ。順序なしカテゴリに使うと偽の大小関係が生じる |
| 「データリーケージとは?」 | 訓練に本来使えない情報が漏れ込むこと。標準化は訓練データのみで計算 |
| 「特徴量エンジニアリングの具体例」 | 日時の分解、二値化、対数変換、交互作用特徴量(BMI等)、ビニング |
前処理は「なぜそれが必要なのか」を理解することが最も重要です。「欠損値がなぜ問題か→平均がズレるから」「スケーリングがなぜ必要か→距離ベースのモデルで特定の特徴量が過大評価されるから」という因果関係で覚えれば、初見の問題にも対応できます。
📚 次に読むべき記事
前処理後のデータを投入する「機械学習」の基礎知識を押さえよう
機械学習の次に学ぶべき「深層学習」を図解で攻略する
DS検定の全体像を把握して効率的な学習計画を立てよう