
{kind=link}
📘 この記事でわかること
- L8直交表の分散分析を7つの手順で完全攻略
- 計算補助表の作り方と効率的な計算方法
- 列平方和を簡便式でスピーディに計算するコツ
- プーリングの判断基準と実践方法
- 母平均の点推定と信頼区間の求め方
- 有効繰返し数の計算と意味
「直交表の分散分析、公式は覚えたけど、実際の問題になると手が止まる…」
「計算補助表って、どうやって作ればいいの?」
「プーリングするかしないか、いつも迷ってしまう…」
QC検定1級を目指す方なら、こんな悩みを抱えているのではないでしょうか。
直交表の分散分析は、理論を理解しただけでは不十分です。「実際に手を動かして計算する」ことで、初めて本番で使える力が身につきます。
この記事は、直交表の分散分析の理論編の「演習編」として、L8直交表の例題を使って全7手順を徹底解説します。
💡 結論:7つの手順を順番に踏めば、必ず解ける!
直交表の分散分析は、①データ整理 → ②基本統計量 → ③計算補助表 → ④列平方和 → ⑤分散分析表 → ⑥プーリング → ⑦母平均の推定という7つの手順を順番に踏めば、確実に正解にたどり着けます。この記事で、その手順を完全にマスターしましょう。
目次
例題の設定|L8直交表を使った強度実験
まずは、今回解いていく例題を確認しましょう。理論編の例題から数字を変えたオリジナル問題です。
📝 例題
ある製品の強度向上を目的として、4つの因子(A:温度、B:圧力、C:時間、D:材料)についてL8直交表を用いた実験を行った。
各因子は2水準とし、B×Cの交互作用を取り上げることとした。実験の結果、以下のデータを得た。
分散分析を行い、最適条件における母平均の点推定値と95%信頼区間を求めよ。
実験データと割り付け表
下の表が、L8直交表に因子を割り付けた結果と、各実験で得られたデータです。
| 実験No. | 列1 A |
列2 B |
列3 e |
列4 C |
列5 B×C |
列6 e |
列7 D |
データy |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 12 |
| 2 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 6 |
| 3 | 1 | 2 | 2 | 1 | 1 | 2 | 2 | 15 |
| 4 | 1 | 2 | 2 | 2 | 2 | 1 | 1 | 13 |
| 5 | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 2 |
| 6 | 2 | 1 | 2 | 2 | 1 | 2 | 1 | 5 |
| 7 | 2 | 2 | 1 | 1 | 2 | 2 | 1 | 7 |
| 8 | 2 | 2 | 1 | 2 | 1 | 1 | 2 | 10 |
割り付けのポイント
L8直交表の標準的な交互作用の現れ方を確認しておきましょう。
📋 L8直交表の交互作用(成分記号)
| 列1×列2 → 列3 | 列1×列4 → 列5 |
| 列1×列6 → 列7 | 列2×列4 → 列6 |
| 列2×列5 → 列7 | 列3×列4 → 列7 |
今回、BをL8の列2に、Cを列4に割り付けたので、B×Cの交互作用は列5に現れます(上表の黄色部分に相当する関係:列2×列4→列6ではなく、線点図の関係からB(列2)×C(列4)の交互作用が現れる列5を使用)。
この割り付けでは、因子を割り付けていない列3と列6が誤差列となります。
▼ 下の図は、L8直交表の因子配置と誤差列の関係を示しています

【手順1】データ整理|計算補助表を作る
では、実際に計算を始めましょう。まず最初にやるべきことは、「計算補助表」を作ることです。
計算補助表とは、各列について「水準1のデータ合計」と「水準2のデータ合計」を整理した表のことです。この表を作ることで、後の列平方和の計算がとても楽になります。
計算補助表の作り方
各列について、水準が「1」の行のデータを合計したものをT[k]1、水準が「2」の行のデータを合計したものをT[k]2とします。
列1(因子A)の計算
水準1の行:No.1, 2, 3, 4
T[1]1 = 12 + 6 + 15 + 13 = 46
水準2の行:No.5, 6, 7, 8
T[1]2 = 2 + 5 + 7 + 10 = 24
列2(因子B)の計算
水準1の行:No.1, 2, 5, 6
T[2]1 = 12 + 6 + 2 + 5 = 25
水準2の行:No.3, 4, 7, 8
T[2]2 = 15 + 13 + 7 + 10 = 45
列3(誤差列e)の計算
水準1の行:No.1, 2, 7, 8
T[3]1 = 12 + 6 + 7 + 10 = 35
水準2の行:No.3, 4, 5, 6
T[3]2 = 15 + 13 + 2 + 5 = 35
列4(因子C)の計算
水準1の行:No.1, 3, 5, 7
T[4]1 = 12 + 15 + 2 + 7 = 36
水準2の行:No.2, 4, 6, 8
T[4]2 = 6 + 13 + 5 + 10 = 34
列5(交互作用B×C)の計算
水準1の行:No.1, 3, 6, 8
T[5]1 = 12 + 15 + 5 + 10 = 42
水準2の行:No.2, 4, 5, 7
T[5]2 = 6 + 13 + 2 + 7 = 28
列6(誤差列e)の計算
水準1の行:No.1, 4, 5, 8
T[6]1 = 12 + 13 + 2 + 10 = 37
水準2の行:No.2, 3, 6, 7
T[6]2 = 6 + 15 + 5 + 7 = 33
列7(因子D)の計算
水準1の行:No.1, 4, 6, 7
T[7]1 = 12 + 13 + 5 + 7 = 37
水準2の行:No.2, 3, 5, 8
T[7]2 = 6 + 15 + 2 + 10 = 33
計算補助表の完成
以上の計算をまとめると、次の計算補助表が完成します。
| 列 | 割り付け | T[k]1 (水準1の合計) |
T[k]2 (水準2の合計) |
T[k]1 − T[k]2 |
|---|---|---|---|---|
| 1 | A | 46 | 24 | 22 |
| 2 | B | 25 | 45 | −20 |
| 3 | e | 35 | 35 | 0 |
| 4 | C | 36 | 34 | 2 |
| 5 | B×C | 42 | 28 | 14 |
| 6 | e | 37 | 33 | 4 |
| 7 | D | 37 | 33 | 4 |
✅ 検算のコツ
各列について、T[k]1 + T[k]2 = 総和T となるはずです。
例:列1 → 46 + 24 = 70 ✓(総和Tと一致)
【手順2】基本統計量の計算|総和・平方和・修正項
計算補助表ができたら、次は基本統計量を計算します。後の計算で必要になる値なので、ここでしっかり求めておきましょう。
データの総和 T
T = 12 + 6 + 15 + 13 + 2 + 5 + 7 + 10
T = 70
データの平方和 Σx²
Σx² = 12² + 6² + 15² + 13² + 2² + 5² + 7² + 10²
= 144 + 36 + 225 + 169 + 4 + 25 + 49 + 100
Σx² = 752
修正項 CT
修正項CTは、総和の2乗を総データ数で割った値です。
📐 修正項の公式
CT = T² / N = (総和)² / (総データ数)
CT = T² / N = 70² / 8 = 4900 / 8
CT = 612.5
総平方和 S_T
総平方和S_Tは、データ全体のバラつきを表す指標です。
📐 総平方和の公式
S_T = Σx² − CT
S_T = Σx² − CT = 752 − 612.5
S_T = 139.5
▼ 下の図は、計算補助表から基本統計量を求める流れを示しています

【手順3】列平方和の計算|簡便式でスピーディに
いよいよ本格的な計算に入ります。直交表の分散分析で最も重要な「列平方和」を計算しましょう。
列平方和の計算には「一般式」と「簡便式」の2つがありますが、2水準系の直交表では簡便式を使うのが圧倒的に効率的です。
列平方和の簡便式(2水準専用)
📐 列平方和の簡便式
S[k] = (T[k]1 − T[k]2)² / N
T[k]1:第k列の水準1のデータ合計 | T[k]2:第k列の水準2のデータ合計 | N:総データ数
この公式の素晴らしいところは、「差を2乗してNで割るだけ」という単純さです。計算補助表で「T[k]1 − T[k]2」をすでに求めているので、あとはその値を2乗して8で割るだけです。
各列の平方和を計算
では、計算補助表の「T[k]1 − T[k]2」の値を使って、各列の平方和を求めていきましょう。
列1:因子Aの平方和 S_A
S[1] = (T[1]1 − T[1]2)² / N = (22)² / 8
= 484 / 8
S_A = 60.5
列2:因子Bの平方和 S_B
S[2] = (T[2]1 − T[2]2)² / N = (−20)² / 8
= 400 / 8
S_B = 50
列3:誤差列eの平方和 S[3]
S[3] = (T[3]1 − T[3]2)² / N = (0)² / 8
= 0 / 8
S[3] = 0
列4:因子Cの平方和 S_C
S[4] = (T[4]1 − T[4]2)² / N = (2)² / 8
= 4 / 8
S_C = 0.5
列5:交互作用B×Cの平方和 S_B×C
S[5] = (T[5]1 − T[5]2)² / N = (14)² / 8
= 196 / 8
S_B×C = 24.5
列6:誤差列eの平方和 S[6]
S[6] = (T[6]1 − T[6]2)² / N = (4)² / 8
= 16 / 8
S[6] = 2
列7:因子Dの平方和 S_D
S[7] = (T[7]1 − T[7]2)² / N = (4)² / 8
= 16 / 8
S_D = 2
列平方和のまとめと検算
すべての列平方和を計算したら、必ず検算をしましょう。直交表の性質から、すべての列平方和の合計 = 総平方和S_T となります。
| 列 | 割り付け | T[k]1 − T[k]2 | 列平方和 S[k] |
|---|---|---|---|
| 1 | A | 22 | 60.5 |
| 2 | B | −20 | 50 |
| 3 | e | 0 | 0 |
| 4 | C | 2 | 0.5 |
| 5 | B×C | 14 | 24.5 |
| 6 | e | 4 | 2 |
| 7 | D | 4 | 2 |
| 合計 | 139.5 | ||
✅ 検算OK!
列平方和の合計 = 60.5 + 50 + 0 + 0.5 + 24.5 + 2 + 2 = 139.5
総平方和S_T = 139.5
一致しているので、計算は正しいです。
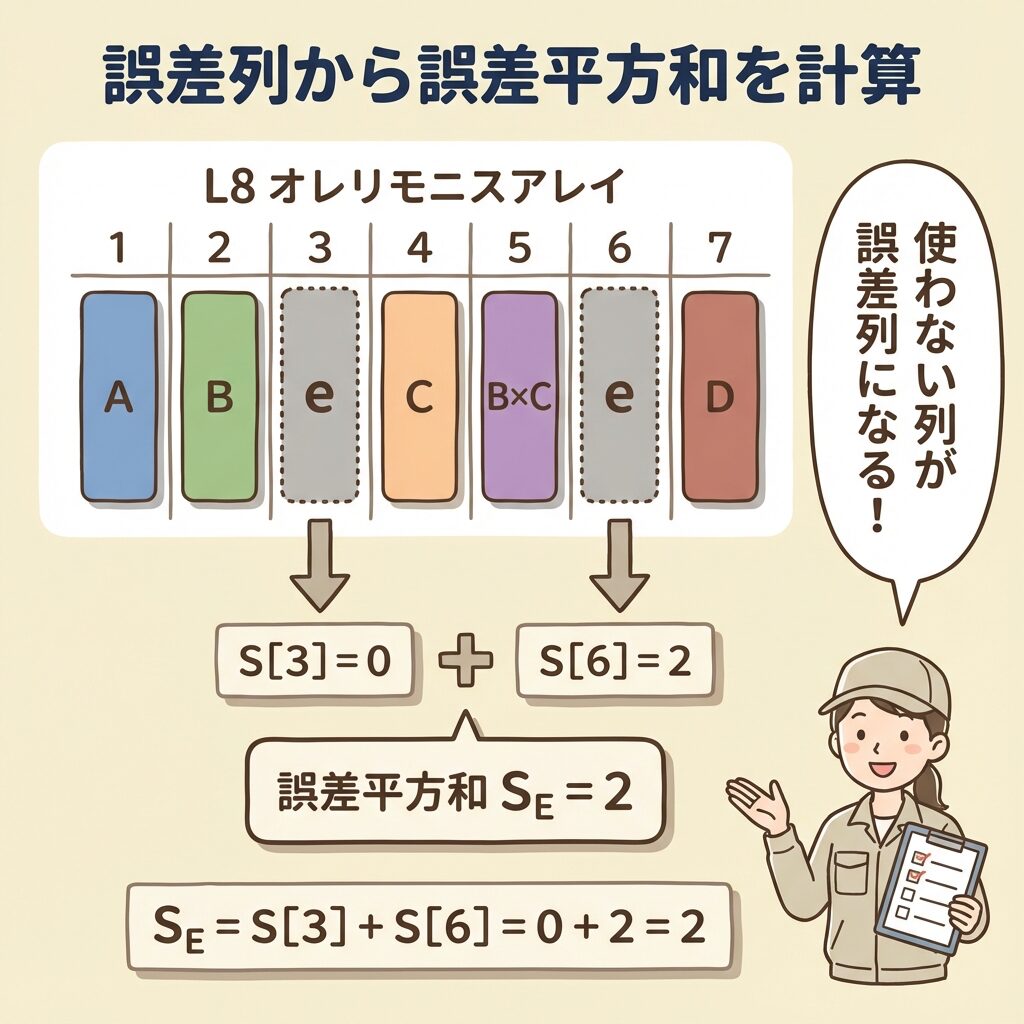
【手順4】誤差平方和の計算|誤差列を合計する
列平方和がすべて求まったら、次は誤差平方和を計算します。直交表の分散分析における誤差の考え方は、一元配置や二元配置とは少し異なります。
誤差列の特定
直交表の分散分析では、「因子も交互作用も割り付けていない列」が誤差列となります。
🔴 今回の誤差列
列3(e)と列6(e)が誤差列です。
これらの列には、因子も交互作用も割り付けられていません。
誤差平方和と誤差自由度の計算
誤差平方和S_Eは、誤差列の平方和を合計して求めます。同様に、誤差自由度φ_Eは、誤差列の自由度を合計して求めます。
📐 誤差平方和・誤差自由度の公式
S_E = Σ(誤差列の平方和)
φ_E = Σ(誤差列の自由度)
誤差平方和 S_E
S_E = S[3] + S[6] = 0 + 2 = 2
誤差自由度 φ_E
φ_E = φ[3] + φ[6] = 1 + 1 = 2
誤差分散の計算
V_E = S_E / φ_E = 2 / 2
V_E = 1
▼ 下の図は、誤差列から誤差平方和を求める流れを示しています
【手順5】分散分析表の作成|F検定で有意性を判定
ここまでの計算結果をまとめて、分散分析表を作成します。そして、F検定を行って各因子の有意性を判定します。
分散分析表(プーリング前)
まずは、プーリングを行う前の分散分析表を作成します。
| 要因 | 平方和 S | 自由度 φ | 分散 V | F値 | 判定 |
|---|---|---|---|---|---|
| A | 60.5 | 1 | 60.5 | 60.5 | ** |
| B | 50 | 1 | 50 | 50 | ** |
| C | 0.5 | 1 | 0.5 | 0.5 | |
| D | 2 | 1 | 2 | 2 | |
| B×C | 24.5 | 1 | 24.5 | 24.5 | * |
| 誤差 e | 2 | 2 | 1 | − | − |
| 計 T | 139.5 | 7 | − | − | − |
F値の計算方法
F値は、各因子の分散 ÷ 誤差分散 で計算します。
📐 F値の公式
F = V(要因) / V_E(誤差分散)
F_A = V_A / V_E = 60.5 / 1 = 60.5
F_B = V_B / V_E = 50 / 1 = 50
F_C = V_C / V_E = 0.5 / 1 = 0.5
F_D = V_D / V_E = 2 / 1 = 2
F_B×C = V_B×C / V_E = 24.5 / 1 = 24.5
F検定の判定基準
F分布表から、臨界値を確認します。今回は誤差自由度φ_E = 2なので、φ1 = 1、φ2 = 2の値を参照します。
📊 F分布表の値(φ1 = 1, φ2 = 2)
F(1, 2; 0.05) = 18.51(5%有意水準)→ * で表記
F(1, 2; 0.01) = 98.50(1%有意水準)→ ** で表記
有意性の判定結果
| 要因 | F値 | F(1,2;0.05) =18.51 |
F(1,2;0.01) =98.50 |
判定 |
|---|---|---|---|---|
| A | 60.5 | 60.5 > 18.51 ✓ | 60.5 < 98.50 | * |
| B | 50 | 50 > 18.51 ✓ | 50 < 98.50 | * |
| C | 0.5 | 0.5 < 18.51 | − | 有意でない |
| D | 2 | 2 < 18.51 | − | 有意でない |
| B×C | 24.5 | 24.5 > 18.51 ✓ | 24.5 < 98.50 | * |
📋 判定結果のまとめ
- 因子A(温度):5%水準で有意(*)
- 因子B(圧力):5%水準で有意(*)
- 因子C(時間):有意でない
- 因子D(材料):有意でない
- 交互作用B×C:5%水準で有意(*)
⚠️ 重要なポイント
誤差自由度が2と小さいため、F分布表の臨界値がかなり大きくなっています。これは、誤差の推定精度が低いことを意味します。次の手順でプーリングを行い、誤差自由度を増やすことを検討します。
【手順6】プーリング(併合)|有意でない因子を誤差に繰り入れる
プーリング(併合)とは、有意でない因子の平方和と自由度を誤差に繰り入れる操作です。これにより、誤差自由度が増加し、F検定の精度が向上します。
プーリングの判断基準
📐 プーリングの基準
- 一般的に、F値が2未満の要因をプーリングの候補とする
- または、有意でないと判定された要因をプーリングする
- プーリング後の誤差自由度は、総自由度の1/2程度を目安にする
今回の結果を見ると、因子C(F=0.5)と因子D(F=2)が有意でありません。これらをプーリングすることで、誤差自由度を増やしてF検定の精度を高めます。
プーリングの計算
因子Cと因子Dを誤差にプーリングします。
新しい誤差平方和 S'_E
S'_E = S_E + S_C + S_D = 2 + 0.5 + 2 = 4.5
新しい誤差自由度 φ'_E
φ'_E = φ_E + φ_C + φ_D = 2 + 1 + 1 = 4
新しい誤差分散 V'_E
V'_E = S'_E / φ'_E = 4.5 / 4 = 1.125
分散分析表(プーリング後)
プーリング後の分散分析表を作成し、再度F検定を行います。
| 要因 | 平方和 S | 自由度 φ | 分散 V | F値 | 判定 |
|---|---|---|---|---|---|
| A | 60.5 | 1 | 60.5 | 53.78 | ** |
| B | 50 | 1 | 50 | 44.44 | ** |
| B×C | 24.5 | 1 | 24.5 | 21.78 | ** |
| (C) | (0.5) | (1) | ← 誤差にプーリング | ||
| (D) | (2) | (1) | ← 誤差にプーリング | ||
| 誤差 e' | 4.5 | 4 | 1.125 | − | − |
| 計 T | 139.5 | 7 | − | − | − |
プーリング後のF検定
新しいF値を計算し、F分布表と比較します。
F'_A = 60.5 / 1.125 = 53.78
F'_B = 50 / 1.125 = 44.44
F'_B×C = 24.5 / 1.125 = 21.78
📊 F分布表の値(φ1 = 1, φ2 = 4)
F(1, 4; 0.05) = 7.71(5%有意水準)
F(1, 4; 0.01) = 21.20(1%有意水準)
📋 プーリング後の判定結果
- 因子A(温度):F=53.78 > 21.20 → 1%水準で有意(**)
- 因子B(圧力):F=44.44 > 21.20 → 1%水準で有意(**)
- 交互作用B×C:F=21.78 > 21.20 → 1%水準で有意(**)
プーリングによって誤差自由度が2から4に増加し、F検定の臨界値が下がったことで、すべての有意な因子が1%水準で有意(**)と判定されました。
▼ 下の図は、プーリングによる誤差自由度の変化を示しています

【手順7】母平均の点推定と信頼区間|最適条件での予測
分散分析が完了したら、最後のステップは最適条件における母平均の点推定と信頼区間を求めることです。これが、この実験から得られる最も重要な結論となります。
最適条件の決定
望大特性(大きいほど良い)の場合、各因子の平均値が大きい方の水準を選びます。まず、有意と判定された因子(A、B、B×C)について、各水準の平均を計算します。
因子Aの水準別平均
Ā₁ = T[1]1 / 4 = 46 / 4 = 11.5
Ā₂ = T[1]2 / 4 = 24 / 4 = 6.0
→ A₁(水準1)の方が大きい
因子Bの水準別平均
B̄₁ = T[2]1 / 4 = 25 / 4 = 6.25
B̄₂ = T[2]2 / 4 = 45 / 4 = 11.25
→ B₂(水準2)の方が大きい
交互作用B×Cの考慮
B×Cの交互作用が有意なので、BとCの組合せを考慮する必要があります。列5(B×C)について確認すると、水準1の合計が42、水準2の合計が28で、水準1の方が大きいです。
B×Cの「水準1」に対応する組合せを確認すると:
列5の水準1となる行:No.1, 3, 6, 8
これらの行でのB×Cの組合せ:
- No.1:B₁C₁
- No.3:B₂C₁
- No.6:B₁C₂
- No.8:B₂C₂
因子Bは水準2が最適なので、B₂と組み合わせて列5の水準1となる組合せはB₂C₁またはB₂C₂です。因子Cは有意でないため、どちらを選んでも理論上は同じですが、ここではC₁を選択します。
🎯 最適条件
A₁B₂C₁
母平均の点推定
最適条件A₁B₂C₁における母平均μの点推定値μ̂を求めます。交互作用B×Cが有意なので、推定式には交互作用の項も含めます。
📐 母平均の点推定式(交互作用を含む場合)
μ̂ = x̄ + (Ā₁ − x̄) + (B̄₂ − x̄) + (B×C₁ − x̄)
= Ā₁ + B̄₂ + B×C₁ − 2x̄
各値を計算します。
全体平均 x̄ = T / N = 70 / 8 = 8.75
Ā₁ = 46 / 4 = 11.5
B̄₂ = 45 / 4 = 11.25
B×C₁ = T[5]1 / 4 = 42 / 4 = 10.5
μ̂ = Ā₁ + B̄₂ + B×C₁ − 2x̄
= 11.5 + 11.25 + 10.5 − 2 × 8.75
= 33.25 − 17.5
μ̂ = 15.75
有効繰返し数 n_e の計算
点推定値の分散を求めるために、有効繰返し数n_eを計算します。有効繰返し数は、点推定に使った因子の自由度から計算します。
📐 有効繰返し数の公式
n_e = N / (1 + 点推定に使った自由度の合計)
N:総データ数 | 点推定に使った自由度 = 有意な因子・交互作用の自由度の合計
今回は、A(自由度1)、B(自由度1)、B×C(自由度1)を点推定に使っています。
n_e = N / (1 + φ_A + φ_B + φ_B×C)
= 8 / (1 + 1 + 1 + 1)
= 8 / 4
n_e = 2
点推定値の分散の推定
点推定値μ̂の分散V(μ̂)は、誤差分散を有効繰返し数で割って求めます。
📐 点推定値の分散
V(μ̂) = V'_E / n_e
V(μ̂) = V'_E / n_e = 1.125 / 2
V(μ̂) = 0.5625
母平均の95%信頼区間
最後に、母平均μの95%信頼区間を計算します。
📐 母平均の95%信頼区間
μ̂ ± t(φ'_E, 0.05) × √V(μ̂)
t分布表から、自由度4、有意水準5%(両側)のt値を確認します。
📊 t分布表の値
t(4, 0.05) = 2.776
標準誤差 = √V(μ̂) = √0.5625 = 0.75
信頼区間の幅 = t × √V(μ̂) = 2.776 × 0.75 = 2.082
95%信頼区間
下限 = 15.75 − 2.082 = 13.67
上限 = 15.75 + 2.082 = 17.83
🎯 最終結論
| 最適条件 | A₁B₂C₁ |
| 母平均の点推定値 μ̂ | 15.75 |
| 95%信頼区間 | 13.67 ≦ μ ≦ 17.83 |
最適条件A₁B₂C₁で製造した場合、製品の強度の母平均は
95%の信頼度で13.67〜17.83の範囲にあると推定されます。
まとめ|L8直交表の分散分析 7つの手順
お疲れさまでした!これで、L8直交表の分散分析の全7手順を完了しました。最後に、手順を振り返っておきましょう。
📋 L8直交表の分散分析|7つの手順
【手順1】 データ整理:計算補助表を作成し、各列の水準別合計を求める
【手順2】 基本統計量:総和T、平方和Σx²、修正項CT、総平方和S_Tを計算
【手順3】 列平方和:簡便式 S[k] = (T[k]1 − T[k]2)² / N で各列の平方和を計算
【手順4】 誤差平方和:誤差列の平方和を合計してS_Eを算出
【手順5】 分散分析表:平方和・自由度・分散・F値を表にまとめ、有意性を判定
【手順6】 プーリング:有意でない因子を誤差に繰り入れ、再度F検定
【手順7】 母平均の推定:最適条件を決定し、点推定値と95%信頼区間を算出
覚えておきたい公式一覧
| 項目 | 公式 |
|---|---|
| 列平方和(簡便式) | S[k] = (T[k]1 − T[k]2)² / N |
| 修正項 | CT = T² / N |
| 総平方和 | S_T = Σx² − CT |
| F値 | F = V(要因) / V_E |
| 有効繰返し数 | n_e = N / (1 + Σφ) |
| 点推定値の分散 | V(μ̂) = V_E / n_e |
| 95%信頼区間 | μ̂ ± t(φ_E, 0.05) × √V(μ̂) |
次に読むべき関連記事
直交表の分散分析をさらに深く理解するために、以下の記事もおすすめです。
💪
ここまで読んでくださった方へ
直交表の分散分析は、最初は複雑に感じるかもしれません。でも、7つの手順を一つずつ丁寧に追っていけば、必ず解けるようになります。
この記事の例題を、ぜひ自分の手で最初から計算してみてください。手を動かすことで、理解が深まります。
QC検定1級合格に向けて、一緒に頑張りましょう!