
{kind=link}
- 「工程異常」と「不良品の発生」は何が違うの?
- 管理図で点が管理限界を超えたら、具体的に何をすればいい?
- 「応急処置」と「恒久対策」の違いがよくわからない
- 異常を見逃さない仕組みって、どうやって作ればいいの?
- 「工程異常」の定義と、なぜ早期発見が重要なのか
- 偶然原因と異常原因(特殊原因)の違い
- 管理図が発する「アラーム」の種類と見方
- 異常発見から恒久対策までの処置フロー
- 異常に強い工程を作るための仕組みづくり
工場で製品を作っていると、「いつもと何か違う」という瞬間があります。
管理図の点が急に跳ね上がった。機械から聞き慣れない音がする。製品の寸法が、いつもより少しずれている気がする──。
この「いつもと違う」を見逃さずにキャッチし、適切に対処することが、品質管理の核心です。
この記事では、QC検定1級で問われる「工程異常」について、異常の定義から発見方法、処置の流れまでを、初心者でもイメージできるようにやさしく解説します。
目次
「工程異常」とは何か?──川の流れでイメージする
まず、「工程異常」とは何かを明確にしましょう。
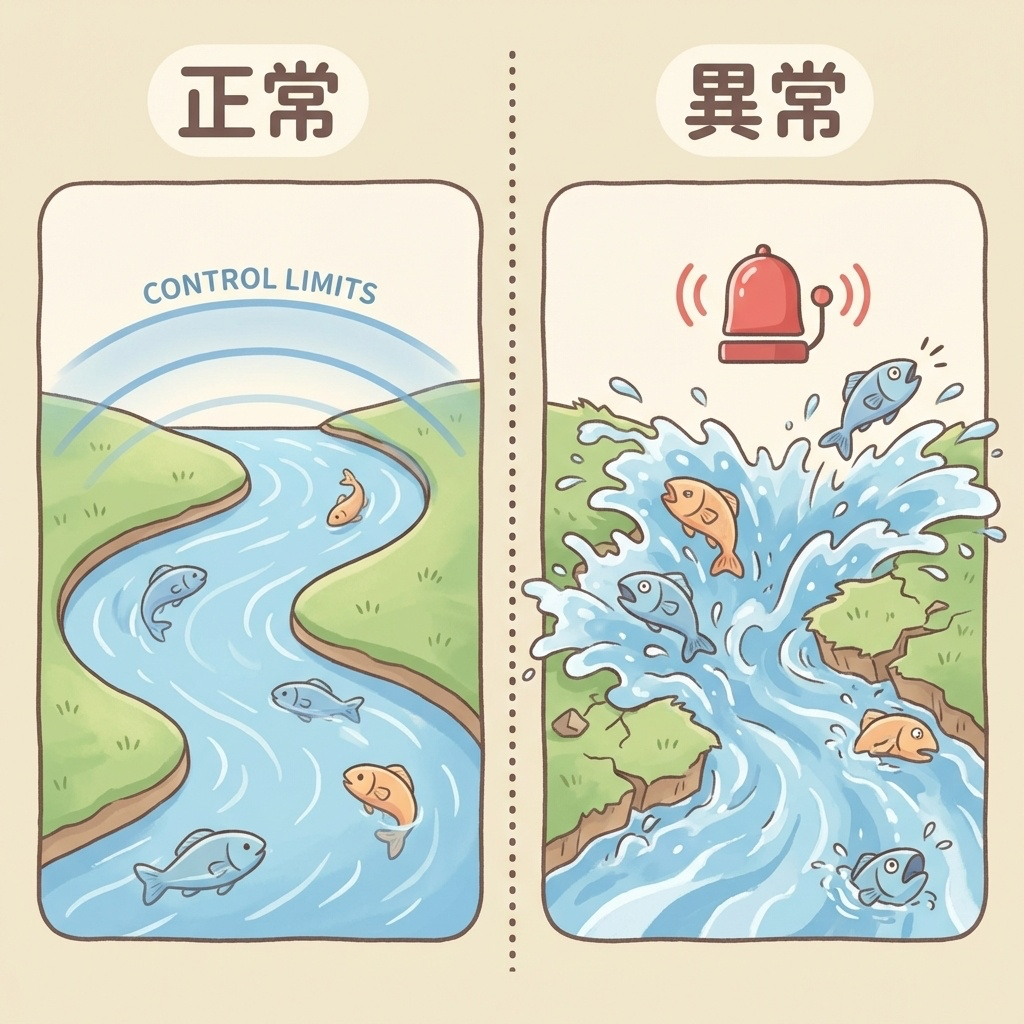
🌊 川の流れで考える「正常」と「異常」
工程を「川の流れ」に例えてみましょう。
川には両岸があります。この両岸が「管理限界」です。
正常な状態
川の水は、多少の波はあっても、両岸の間を穏やかに流れています。魚も安心して泳いでいる。これが「工程が管理状態にある」状態です。
異常な状態
突然、上流で大雨が降ったとします。川の水位が急上昇し、水が両岸を越えて溢れ出す。魚が岸に打ち上げられる。これが「工程異常」です。
「工程が通常の管理状態から外れ、製品品質に影響を及ぼす可能性がある状態」
⚠️ 重要:異常 ≠ 不良
ここで重要なポイントがあります。
「工程異常」と「不良品の発生」は、同じではありません。
| 工程異常 | 不良発生 | |
|---|---|---|
| 何を見ている? | 工程の状態(プロセス) | 製品の状態(結果) |
| 判断基準 | 管理限界(UCL・LCL) | 規格限界(USL・LSL) |
| 目的 | 不良を未然に防ぐ | 不良品を除去する |
川の例で言えば、「水が岸を越えそうになっている」のが工程異常、「魚が岸に打ち上げられた」のが不良発生です。
工程異常を早期に発見すれば、不良品が出る前に対処できます。これが「予防」の考え方であり、品質管理の本質です。不良品を検査で取り除くのは「事後対応」であり、コストも時間もかかります。
「偶然原因」と「異常原因」──2種類の変動を区別する
工程には、常に「ばらつき」があります。でも、すべてのばらつきが異常ではありません。
ばらつきの原因は、大きく2種類に分けられます。
🎲 偶然原因(Common Cause)
工程に常に存在する、小さな変動要因の積み重ねです。
例えば:
- 原材料のわずかな成分ばらつき
- 室温の微妙な変化
- 作業者の手の動きの微差
- 機械の微小な振動
これらは特定が困難で、ゼロにすることはできません。でも、たくさんの小さな要因が足し合わさっても、その影響は管理限界の中に収まります。
偶然原因だけが存在する工程は「管理状態にある」と言います。
⚡ 異常原因(Assignable Cause / Special Cause)
工程に突発的に発生する、特定可能な大きな変動要因です。
例えば:
- 機械の部品が摩耗・破損した
- 原材料のロットが不良だった
- 作業者が手順を間違えた
- 設備の設定値がずれた
これらは特定でき、取り除くことができます。そして、取り除かなければなりません。
異常原因が存在する工程は「管理状態にない」と言います。
📊 2つの原因を表で比較
| 偶然原因 | 異常原因 | |
|---|---|---|
| 別名 | 共通原因、慢性原因 | 特殊原因、突発原因 |
| 特徴 | 常に存在、小さい | 突発的、大きい |
| 特定可能か | 困難 | 可能 |
| 除去可能か | ゼロにはできない | 除去すべき |
| 工程の状態 | 管理状態 | 管理状態にない |
管理図の役割は、「偶然原因によるばらつき」と「異常原因によるばらつき」を区別することです。管理限界内に収まっていれば偶然原因、管理限界を超えたら異常原因が発生している可能性が高い、と判断します。

管理図が発する「アラーム」を見逃すな
異常原因を早期発見するための最強ツールが「管理図」です。
管理図は、単にデータを記録するだけのグラフではありません。「異常が起きているぞ!」という警報(アラーム)を発する仕組みが組み込まれています。
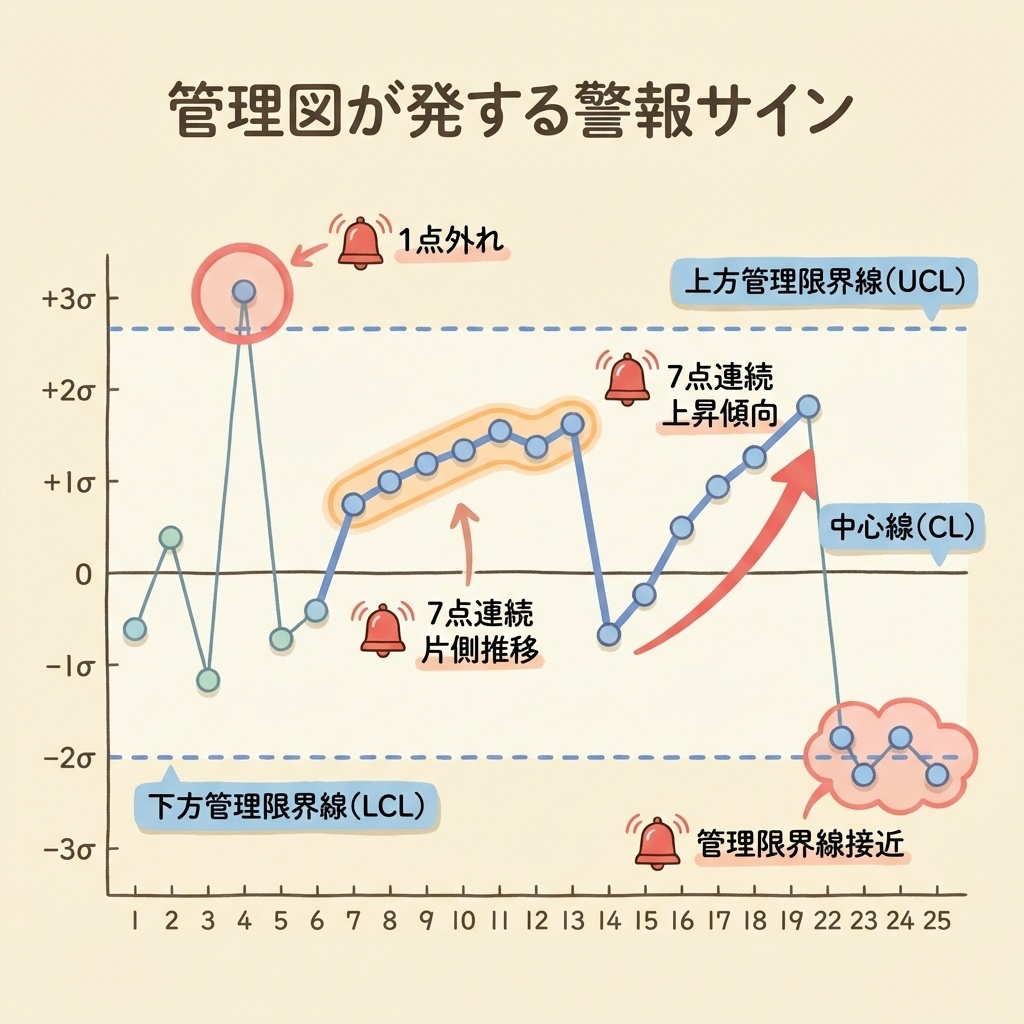
🚨 アラーム①:管理限界を超えた点
最もわかりやすい異常サインです。
データ点がUCL(上方管理限界)を上回った、またはLCL(下方管理限界)を下回った場合、異常原因が発生している可能性が非常に高いと判断します。
1点でも管理限界を超えたら、即座に原因調査を開始する
🚨 アラーム②:連(ラン)のルール
管理限界内であっても、異常を示すパターンがあります。
「連(ラン)」とは、中心線(CL)の片側に連続して点が並ぶ現象です。
7点以上が中心線の同じ側に連続して並んだ場合、工程に偏り(シフト)が発生している可能性がある
コイン投げで7回連続で表が出たら「このコイン、おかしくない?」と思いますよね。それと同じです。
🚨 アラーム③:傾向(トレンド)のルール
「傾向」とは、点が一定方向に連続して上昇または下降するパターンです。
7点以上が連続して上昇(または下降)している場合、工程に徐々に変化が起きている可能性がある
例えば、刃物の摩耗が進むと、加工寸法が徐々に大きくなっていきます。
🚨 アラーム④:その他のパターン
JISやISOでは、さらに細かい異常判定ルールが定められています。
| パターン | 条件 | 疑われる異常 |
|---|---|---|
| 限界超え | 1点がUCLまたはLCLを超える | 突発的な異常原因 |
| 連(ラン) | 7点以上が中心線の片側に連続 | 工程平均のシフト |
| 傾向 | 7点以上が連続して上昇または下降 | 徐々に進行する変化(摩耗など) |
| 周期 | 点が規則的に上下を繰り返す | 周期的な外部要因(温度変化など) |
| 中心線への密集 | 15点中14点以上が±1σ内にある | 層別の問題、データの取り方の問題 |
異常を発見する「仕組み」を作る
管理図でアラームが出たとき、それに気づける仕組みがなければ意味がありません。
🔄 異常発見のサイクル
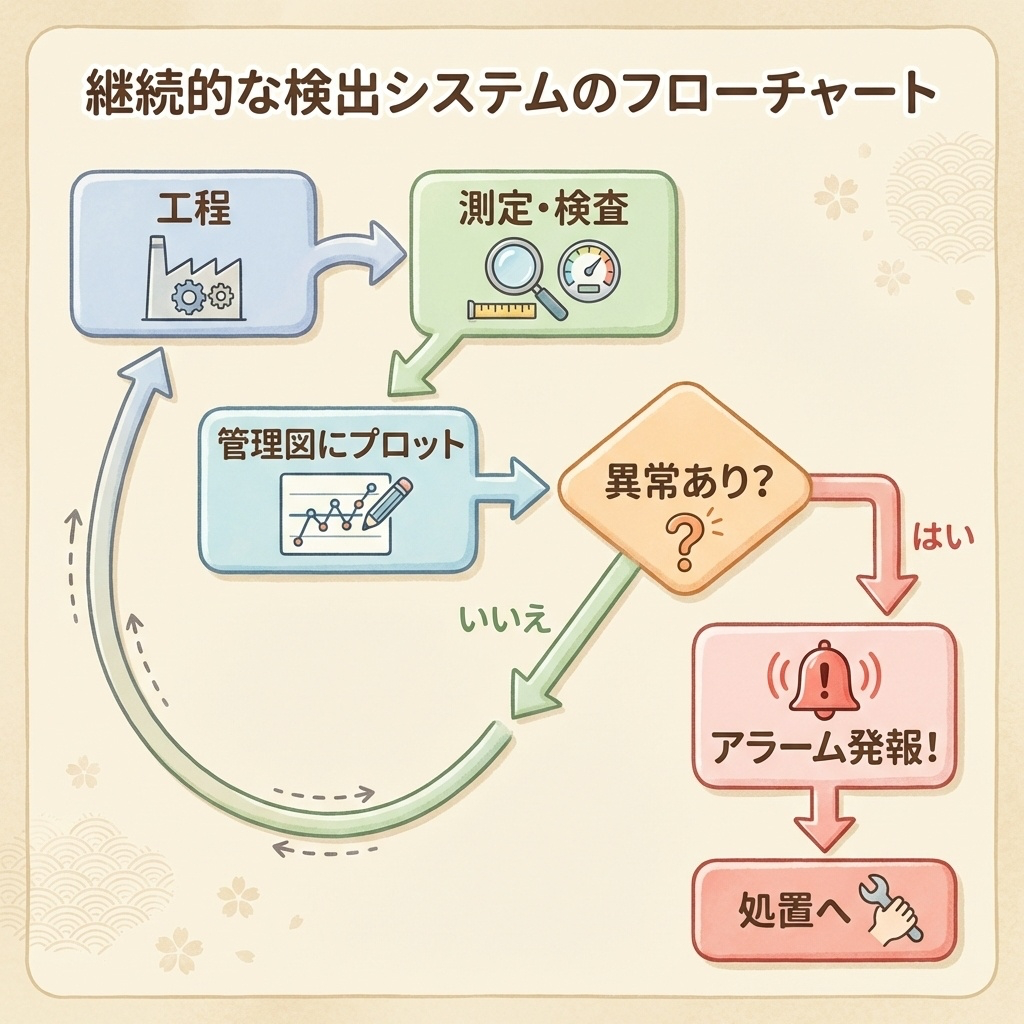
異常を見逃さないためには、以下のサイクルを継続的に回す仕組みが必要です。
異常発見サイクル
①工程で製品を作る
↓
②データを測定・収集する
↓
③管理図にプロットする
↓
④アラーム条件をチェックする
↓
異常あり? → Yes:処置へ / No:①に戻る
⚙️ 仕組み化のポイント
ポイント①:誰がやっても同じ判断ができる
「ベテランは気づくけど、新人は気づかない」では困ります。アラーム条件を明文化し、誰でも判断できるようにしましょう。
- 管理限界線を赤線で引く
- 「7点連続で片側」などのルールを作業手順書に明記
- チェックリストを作成する
ポイント②:リアルタイムに近づける
異常発生から発見までの時間が短いほど、被害を小さく抑えられます。
- 測定頻度を上げる(全数→抜取でも、頻度は維持)
- 自動測定・自動プロットのシステムを導入する
- 異常時に自動でアラームが鳴る仕組みを作る
ポイント③:「異常かも?」を言いやすい文化
作業者が「異常かも」と思っても、「言ったら怒られる」「面倒くさがられる」と感じると報告しません。
「異常を報告した人を褒める」文化を作ることが、仕組み以上に重要です。
異常を見逃さない仕組みは、「技術」と「文化」の両輪で成り立ちます。どんなに優れた管理図システムを作っても、報告をためらう文化があれば機能しません。
「応急処置」と「恒久対策」──2段階で考える
異常を発見したら、次は「処置」です。
処置には2つの段階があります。これを混同すると、「対策したのにまた再発した」という事態になります。
🩹 応急処置(Emergency Response)
「今すぐ被害を止める」ための処置です。
家の水道管から水漏れが起きたとき、まず何をしますか?バケツを置いて水を受ける、元栓を閉める──これが応急処置です。
工場での応急処置の例:
- 作業を停止する:これ以上の不良品を作らない
- 異常品を隔離する:良品と混ざらないようにする
- 選別する:すでに作った製品から不良を取り除く
- 設定を元に戻す:ずれた設定を正常値に戻す
応急処置は「原因を取り除いていない」ことに注意。バケツを置いても、水道管の穴は塞がっていません。応急処置だけで終わると、同じ異常が必ず再発します。
🔧 恒久対策(Permanent Corrective Action)
「二度と同じ異常が起きないようにする」ための処置です。
水漏れの例で言えば、配管を修理する、破損した部品を交換する──これが恒久対策です。
工場での恒久対策の例:
- 原因を特定する:なぜ異常が起きたのか調査
- 設備を修理・交換する:摩耗した部品を交換
- 作業手順を改善する:ミスが起きにくい手順に変更
- ポカヨケを導入する:間違えられない仕組みを作る
- 標準を改訂する:作業標準書に反映
📊 応急処置と恒久対策の比較
| 応急処置 | 恒久対策 | |
|---|---|---|
| 目的 | 被害の拡大を防ぐ | 再発を防止する |
| タイミング | 異常発見後すぐ | 原因調査後 |
| 原因への対応 | 触れない | 取り除く |
| 効果の持続 | 一時的 | 永続的 |
| 水漏れの例 | バケツを置く | 配管を修理する |
応急処置は「症状」に、恒久対策は「原因」に対処すると覚えましょう。両方が必要ですが、恒久対策を忘れると「モグラ叩き」状態になります。

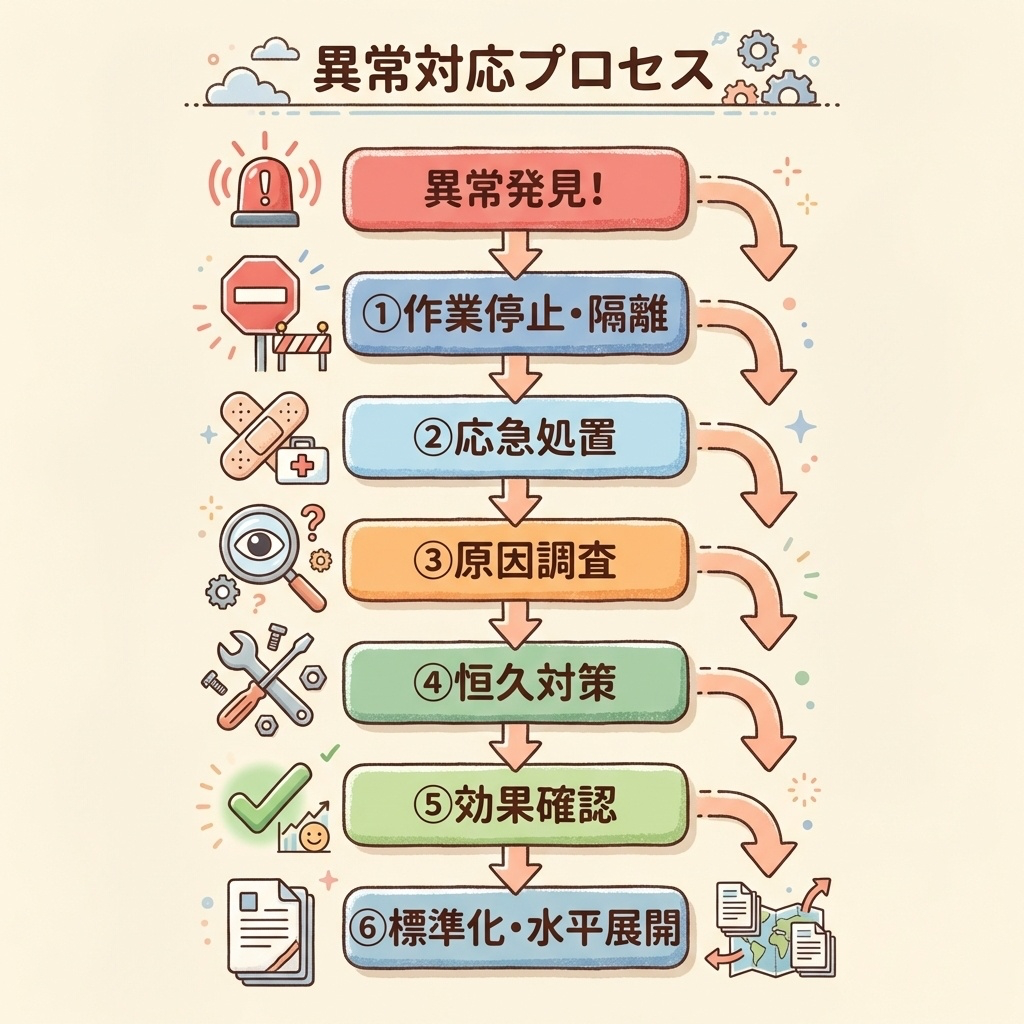
異常処置の6ステップ──発見から標準化まで
異常を発見してから最終的な対策完了まで、6つのステップで進めます。
📋 異常処置フロー
これ以上の被害を防ぐ。異常品を良品と分ける。
設定を戻す、代替手段で生産継続など。
なぜ異常が起きたのか、4M(人・機械・材料・方法)で分析。
原因を取り除く対策を実施。設備修理、手順変更など。
対策後のデータで、本当に改善されたか確認。
作業標準に反映。類似工程にも展開。
🔍 各ステップの詳細
Step 3:原因調査のポイント
原因調査では、「なぜ」を5回繰り返すことが有効です(なぜなぜ分析)。
また、4M(Man・Machine・Material・Method)の観点で網羅的にチェックします。
Step 5:効果確認のポイント
「対策したから大丈夫」ではありません。データで効果を確認することが重要です。
- 管理図で異常パターンが消えたか確認
- 工程能力指数(Cp・Cpk)が改善したか確認
- 一定期間、再発がないことを確認
Step 6:標準化・水平展開のポイント
対策が有効だと確認できたら、「組織の知識」として残すことが大切です。
- 作業標準書を改訂する
- チェックリストに追加する
- 教育資料として活用する
- 類似の工程・製品にも展開する(水平展開)
Step 6を省略すると、「個人の経験」で終わり、組織として成長しません。同じ異常が別の場所で起きたとき、また一から対応することになります。
「異常に強い工程」を作る──仕組みの全体像
ここまでの内容を、「異常管理の全体像」として整理しましょう。
🏠 異常管理システムのピラミッド
異常に強い工程は、以下の4層で構成されます。
対策を標準に反映し、組織の財産にする
異常発見時に何をするか明確にする
異常を早期に検知するシステム
何を「異常」とするか明確にする
✅ 各層のチェックポイント
| 層 | チェック項目 |
|---|---|
| 第1層 異常の定義 |
□ 管理限界(UCL・LCL)が設定されているか □ 異常判定ルール(連・傾向など)が明文化されているか □ 作業者全員が「何が異常か」を知っているか |
| 第2層 発見の仕組み |
□ 管理図が定期的にプロットされているか □ 異常時にアラームが出る仕組みがあるか □ 測定頻度は適切か |
| 第3層 処置のルール |
□ 異常発見時の連絡先・対応手順が決まっているか □ 応急処置の方法が明文化されているか □ 原因調査・恒久対策のフローがあるか |
| 第4層 再発防止 |
□ 対策が標準書に反映されているか □ 類似工程への水平展開がされているか □ 過去の異常事例が記録・共有されているか |
まとめ:異常を見逃さない仕組みを作る
- 工程異常とは、工程が通常の管理状態から外れた状態。不良が出る前に発見することが重要
- 偶然原因は常に存在する小さなばらつき、異常原因は特定・除去すべき大きな変動
- 管理図はアラーム(限界超え、連、傾向など)で異常を知らせる
- 応急処置は被害拡大を防ぐ、恒久対策は再発を防止する
- 処置は6ステップ(停止→応急→調査→恒久→確認→標準化)で進める
- 「異常に強い工程」は定義・発見・処置・再発防止の4層で構成される
異常管理は、品質管理の中でも最も実践的なテーマです。
「異常をゼロにする」のではなく、「異常が起きても、すぐに気づき、適切に対処できる」仕組みを作ることが目標です。
この記事で学んだ考え方を、ぜひ実務に活かしてください。
📚 次に読むべき記事
管理図のアラームパターンをさらに詳しく学ぶ
管理図と工程能力指数を体系的に学ぶ
異常を「未然に防ぐ」手法を学ぶ
