{kind=link}
- データマイニングって何?品質管理にどう使うの?
- クラスタリング、分類、回帰、アソシエーションの違いがわからない
- テキストマイニングで顧客の声をどう分析するの?
- QC検定1級でどのように出題されるか知りたい
- データマイニングの基本概念と主要な手法
- クラスタリング・分類・回帰・アソシエーション分析の違い
- テキストマイニングの仕組みと活用法
- 品質管理でのデータマイニング活用事例
「データは21世紀の石油だ」
そう言われて久しいですが、石油も精製しなければガソリンにはなりません。同じように、データも分析しなければ価値は生まれないのです。
品質管理の現場には、膨大なデータが眠っています。検査データ、不良データ、顧客クレーム、設備ログ…。これらのデータから「隠れたパターン」や「予兆」を見つけ出す技術が「データマイニング」です。
また、顧客の声(VOC)やクレーム内容など、テキストデータを分析するのが「テキストマイニング」です。
QC検定1級では、これらのデータ活用技術が出題されます。この記事では、データマイニング・テキストマイニングの基本を、品質管理との関連を意識しながら解説します。
目次
データマイニングとは何か?
まず、「データマイニング」の定義を確認しましょう。
データマイニングの定義
大量のデータから、統計学・機械学習・パターン認識などの手法を用いて、有用なパターンや知識を発見する技術。「データの山から金(知見)を掘り出す」イメージ。
「マイニング(Mining)」は「採掘」という意味。データという鉱山から、価値ある知見を掘り出す作業です。
金鉱山には大量の岩石がありますが、その中に金が含まれています。
岩石 = 生データ(大量だが、そのままでは価値がない)
金 = 知見・パターン(価値がある)
採掘技術 = データマイニング手法
適切な技術を使わなければ、金は見つけられません。
データマイニングと従来の統計分析の違い
| 比較項目 | 従来の統計分析 | データマイニング |
|---|---|---|
| アプローチ | 仮説検証型 | 仮説探索型 |
| プロセス | 仮説を立てて検証する | データからパターンを発見する |
| データ量 | 比較的少量 | 大量(ビッグデータ) |
| 目的 | 仮説の正しさを確認 | 未知のパターンを発見 |
従来の統計分析は「AとBに関係があるはず」という仮説ありきのアプローチ。一方、データマイニングは「何か面白いパターンはないか?」とデータから発見するアプローチです。
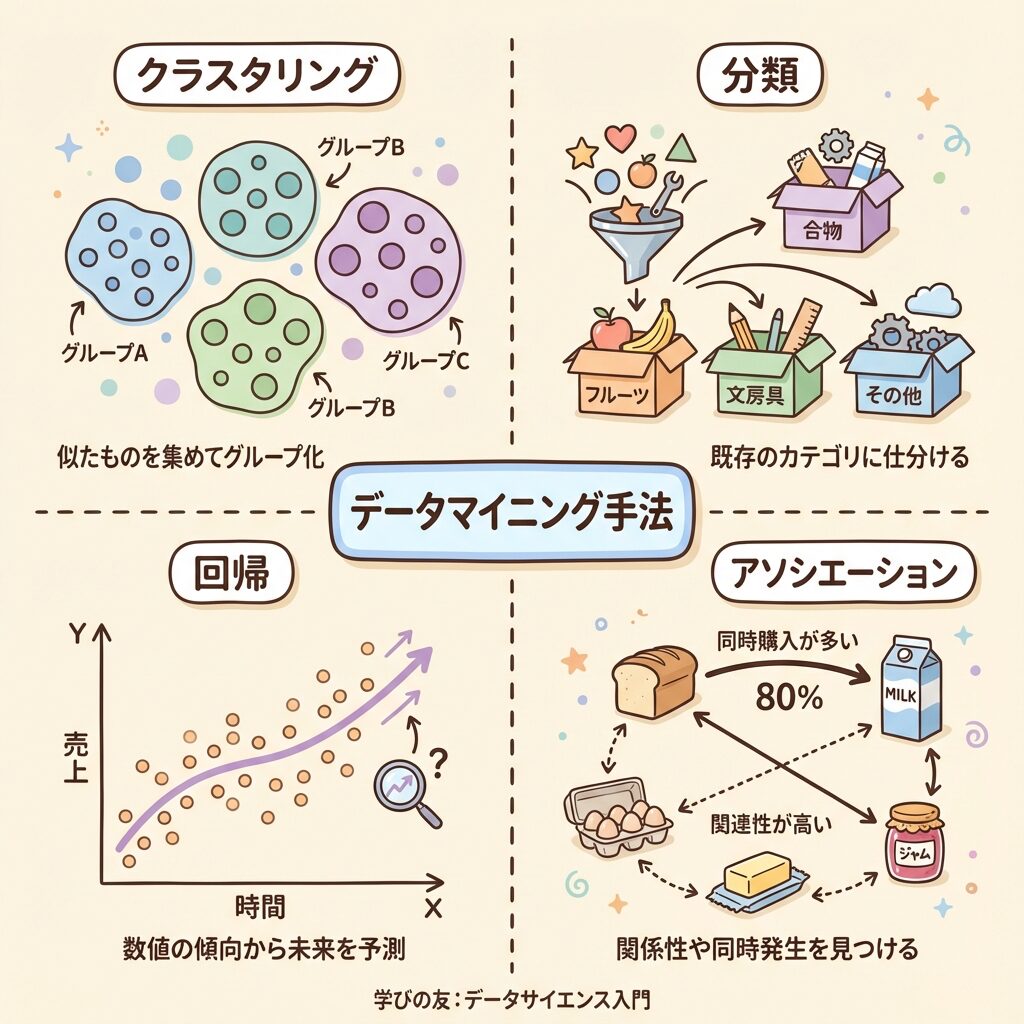
データマイニングの主要な手法
データマイニングには様々な手法がありますが、QC検定1級では以下の4つを押さえておきましょう。
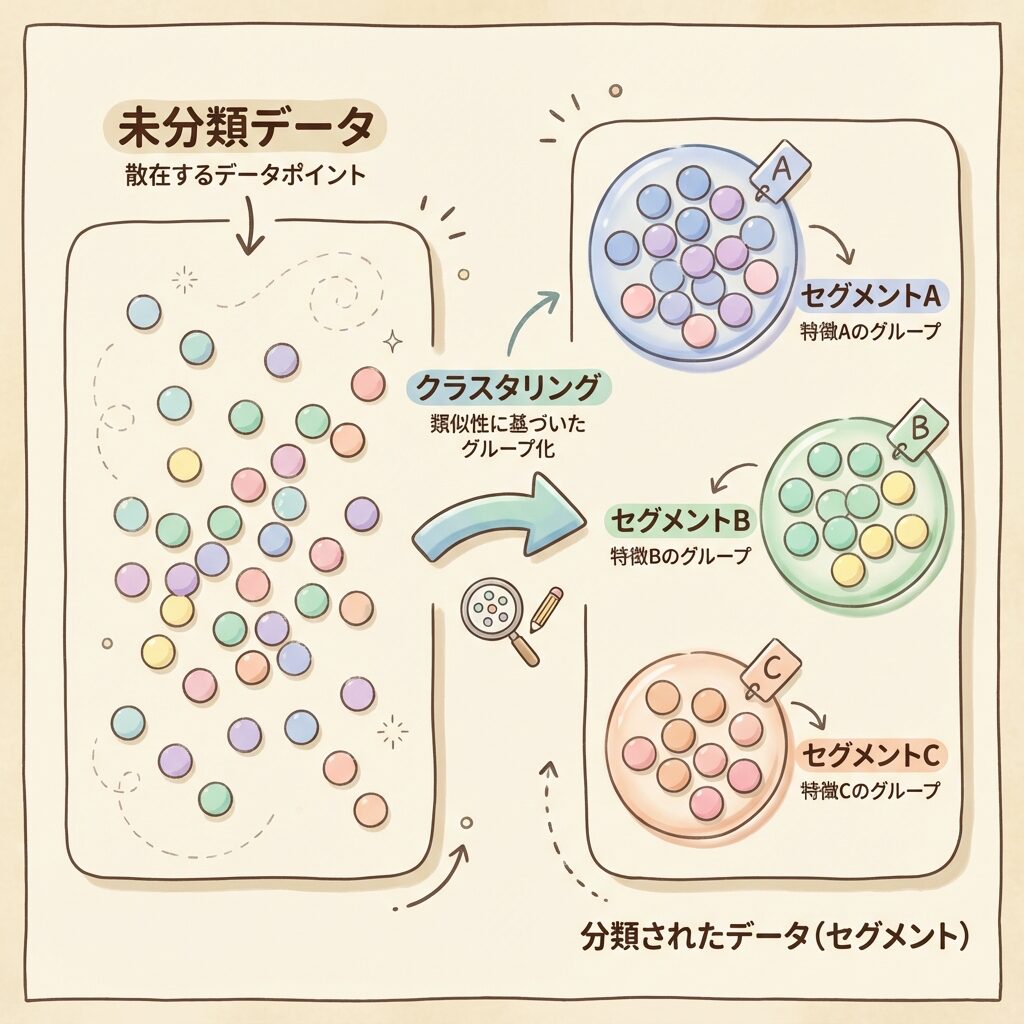
手法①:クラスタリング(Clustering)
データを似た特徴を持つグループ(クラスター)に分ける手法。事前にグループを決めず、データの特徴から自動的にグループ化する。
- 不良品の分類:不良の特徴から、原因ごとにグループ化
- 顧客セグメンテーション:顧客を購買パターンでグループ化
- 設備状態の分類:センサーデータから設備状態をグループ化
代表的なアルゴリズムにはk-means法、階層的クラスタリングなどがあります。
手法②:分類(Classification)
過去のデータから学習し、新しいデータをあらかじめ決められたカテゴリに振り分ける手法。「教師あり学習」の一種。
- 良品/不良品の判定:検査データから自動判定
- クレーム分類:クレーム内容を自動でカテゴリ分け
- 故障予測:設備データから「故障しそう/正常」を判定
代表的なアルゴリズムには決定木、ランダムフォレスト、サポートベクターマシン(SVM)などがあります。
クラスタリング:グループが事前に決まっていない(教師なし学習)
分類:グループが事前に決まっている(教師あり学習)
この違いはQC検定でよく問われるので、しっかり区別しましょう。
手法③:回帰(Regression)
変数間の関係をモデル化し、連続的な数値を予測する手法。「この条件だと、結果はどのくらいになるか?」を予測する。
- 不良率の予測:製造条件から不良率を予測
- 寿命予測:使用条件から製品寿命を予測
- 需要予測:過去データから将来の需要を予測
代表的な手法には線形回帰、重回帰分析、ロジスティック回帰などがあります。
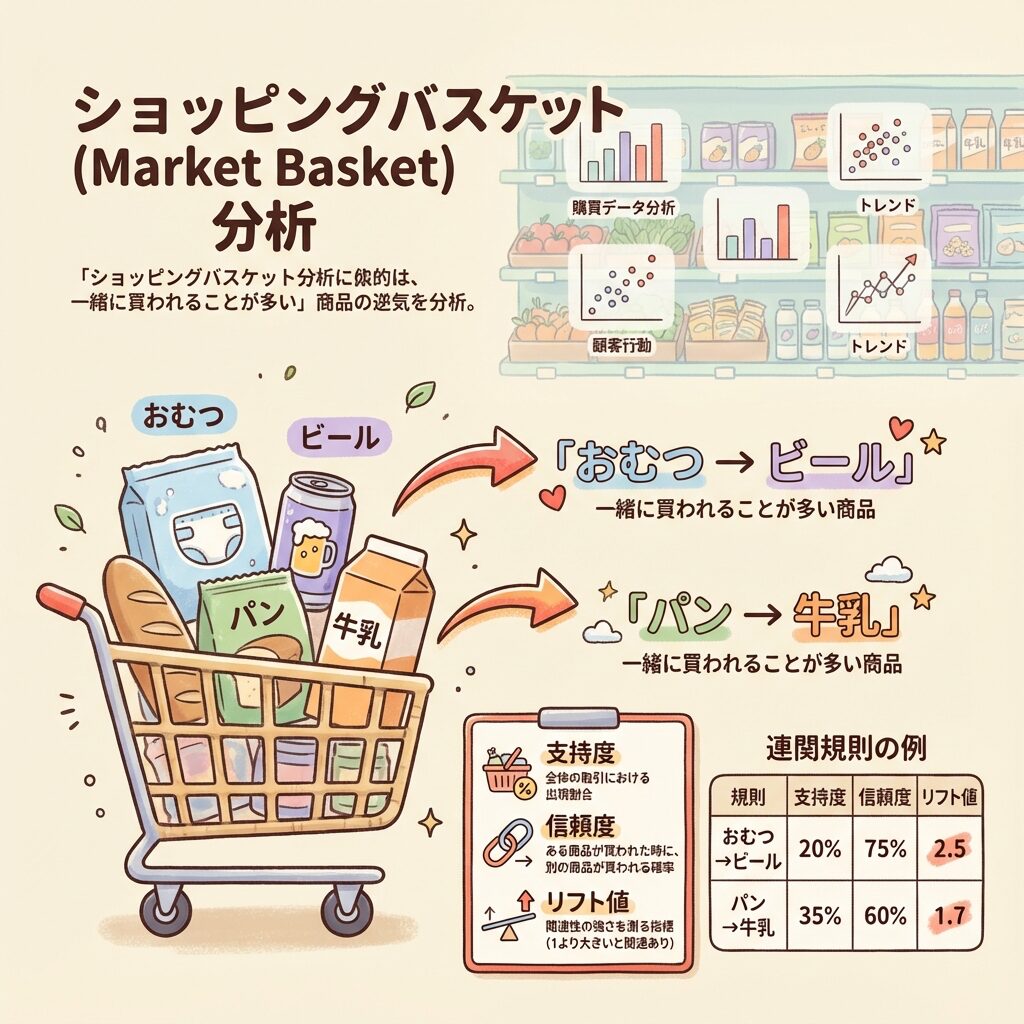
手法④:アソシエーション分析(Association Analysis)
データの中から「AならばB」という関連ルール(相関関係)を発見する手法。「バスケット分析」とも呼ばれ、小売業でよく使われる。
アメリカのスーパーでアソシエーション分析を行ったところ、「おむつを買う人は、ビールも一緒に買う傾向がある」というルールが発見されました。
理由を調べると、「父親がおむつを買いに来たついでに、自分用のビールを買っていた」ことが判明。これを受けて、おむつとビールを近くに配置したところ、売上が向上したと言われています。
アソシエーション分析の指標
アソシエーション分析では、以下の3つの指標でルールの強さを評価します。
| 指標 | 意味 | 計算式 |
|---|---|---|
| 支持度(Support) | AとBが一緒に出現する頻度 | P(A∩B) |
| 信頼度(Confidence) | Aが起きたとき、Bも起きる確率 | P(B|A) = P(A∩B)/P(A) |
| リフト値(Lift) | ルールの「意外性」の度合い | P(B|A)/P(B) |
リフト値が1より大きいと、「AとBには正の関連がある」と判断できます。
- 不良の併発パターン:「不良Aが起きると、不良Bも起きやすい」
- 設備故障の連鎖:「部品Aが故障すると、部品Bも故障しやすい」
- クレームの関連:「この苦情を言う人は、別の苦情も言いやすい」
4つの手法の比較まとめ
| 手法 | 目的 | 学習タイプ | 出力 |
|---|---|---|---|
| クラスタリング | グループ化 | 教師なし | グループ |
| 分類 | カテゴリ予測 | 教師あり | カテゴリ |
| 回帰 | 数値予測 | 教師あり | 連続値 |
| アソシエーション | 関連ルール発見 | 教師なし | ルール |
テキストマイニングとは?
データマイニングが「数値データ」を対象とするのに対し、テキストマイニングは「文章データ」を対象とします。
テキストマイニングの定義
大量のテキストデータ(文章)から、有用な情報やパターンを抽出する技術。自然言語処理(NLP)の技術を活用し、非構造化データである文章を分析可能な形に変換する。
品質管理の現場には、数値化されていない「テキストデータ」が大量にあります。
- 顧客からのクレーム内容
- アンケートの自由回答
- コールセンターの対応記録
- SNSでの口コミ・レビュー
- 作業日報・報告書
これらのテキストデータには貴重な情報が眠っているのに、人手では読み切れない量があります。テキストマイニングは、この課題を解決します。
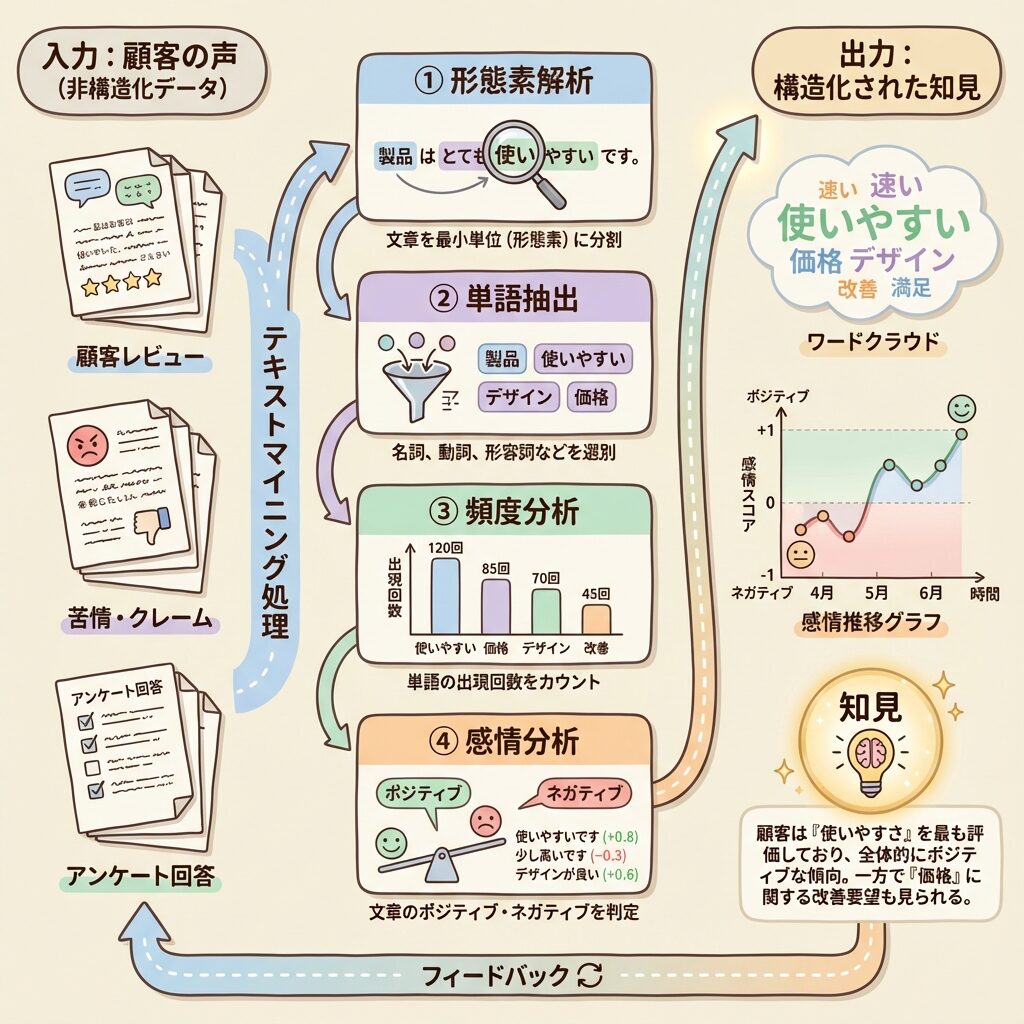
テキストマイニングの処理プロセス
- 形態素解析:文章を単語に分解する
- 単語抽出:重要な単語を取り出す
- 頻度分析:単語の出現頻度をカウント
- 共起分析:一緒に出現しやすい単語の組み合わせを発見
- 感情分析:ポジティブ/ネガティブを判定
形態素解析とは
日本語は英語と違い、単語の区切りがありません。そこで、文章を単語(形態素)に分解するのが形態素解析です。
入力:「この製品の品質はとても良いです」
出力:「この/製品/の/品質/は/とても/良い/です」
さらに品詞情報も付与:
この(指示詞)/製品(名詞)/の(助詞)/品質(名詞)/は(助詞)/とても(副詞)/良い(形容詞)/です(助動詞)
品質管理でのテキストマイニング活用
| データソース | 分析内容 | 得られる知見 |
|---|---|---|
| クレーム内容 | 頻出キーワード、感情分析 | 品質問題の傾向、顧客の不満ポイント |
| SNS・レビュー | 口コミ分析、評判分析 | 市場での評価、競合との比較 |
| 作業日報 | 異常報告の抽出 | 現場の問題点、改善のヒント |
| アンケート自由回答 | VOC分析 | 顧客ニーズ、改善要望 |
QC検定1級での出題ポイント
最後に、QC検定1級でデータマイニング・テキストマイニングがどのように出題されるか、ポイントを整理します。
頻出テーマと出題ポイント
| 頻出テーマ | 出題ポイント |
|---|---|
| データマイニングの定義 | 従来の統計分析との違い(仮説検証 vs 仮説探索) |
| クラスタリングと分類 | 教師なし/教師ありの違い、それぞれの活用例 |
| アソシエーション分析 | 支持度・信頼度・リフト値の意味 |
| テキストマイニング | 形態素解析、頻度分析、感情分析の概念 |
| 品質管理への応用 | 各手法がどのような品質課題に使えるか |
データマイニングの問題は、手法の名称と特徴を正確に覚えることが重要です。
特に「クラスタリング vs 分類」「教師あり vs 教師なし」の違いは頻出。また、アソシエーション分析の3つの指標(支持度・信頼度・リフト値)も押さえておきましょう。
まとめ:データドリブンな品質管理へ
最後に、この記事のポイントをまとめます。
- データマイニングは大量データからパターンを発見する技術
- クラスタリング:似たものをグループ化(教師なし)
- 分類:カテゴリを予測(教師あり)
- 回帰:数値を予測(教師あり)
- アソシエーション:「A→B」の関連ルールを発見
- テキストマイニングは文章データから知見を抽出する技術
- 品質管理では不良予測、原因分析、顧客分析などに活用できる
品質管理の現場には、活用されていない膨大なデータが眠っています。
検査データ、設備ログ、顧客クレーム…。これらのデータを「ただ保存しているだけ」ではもったいない。データマイニング・テキストマイニングの技術を使えば、データから価値ある知見を引き出せます。
「勘と経験」から「データドリブン」へ——これからの品質管理者には、データ活用のスキルが求められます。
📚 次に読むべき記事
データマイニングと組み合わせて活用するマーケティングの基礎を解説。
データマイニングの主要な活用先であるCRMを解説。
データマイニングの基盤となる多変量解析を体系的に解説。