{kind=link}
- 分散分析の解説を読んでも、いきなり「修正項CT」「平方和」と専門用語が並んでフリーズする
- 「分散分析表を作れ」と言われたが、どこから手をつければいいか全くわからない
- 教科書では計算結果だけ書かれていて、途中式がわからない
- F値が出ても、F分布表のどこを見て判定すればいいか自信がない
- QC検定・統計検定の過去問で分散分析が出るたびに頭が真っ白になる
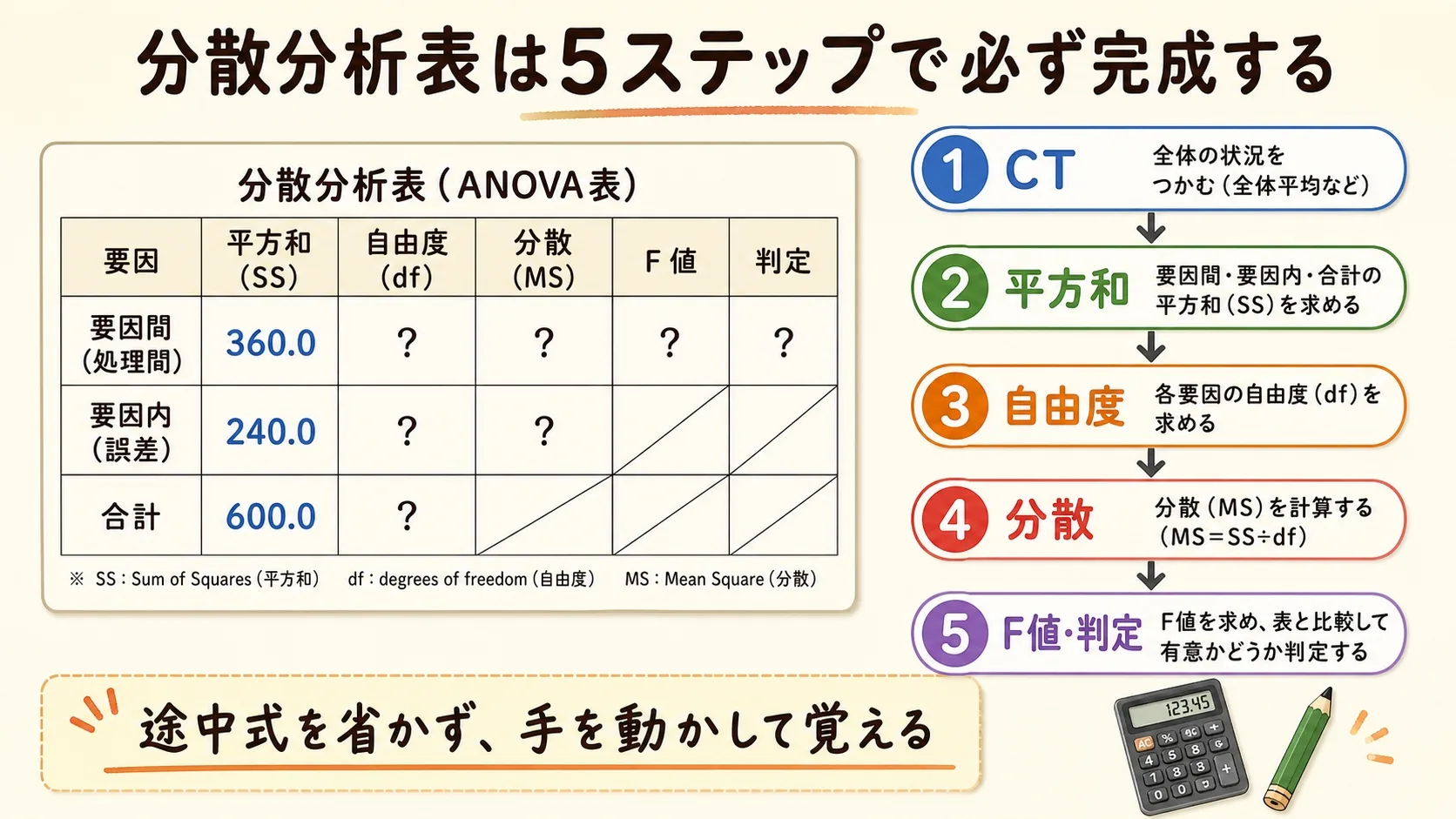
- 分散分析表が「5ステップ」で必ず埋まる、その完全な手順
- 修正項CTを「なぜ最初に計算するのか」の理由
- 平方和を「群間」と「群内」に分解する意味と計算式
- 自由度φの直感的な意味と計算ルール
- F値の出し方とF分布表の正しい引き方
- カレーの試食データで、1から分散分析表を完成させるまでの全途中式
分散分析表は「CT(修正項)→ 平方和S → 自由度φ → 分散V → F値」の順に5ステップで埋めれば必ず完成します。
難しそうに見える数式も、やることは「足す・引く・割る」だけ。
記号アレルギーを克服する最短ルートは、1度だけでいいから途中式を全部書いて手を動かすこと。この記事ではカレーの試食データで、その「1度」を一緒にやります。
本記事は「分散分析の計算編」です。「なぜ平均の差を分散で見るのか?」という概念編を先に読みたい方は、下記の関連記事を先にチェックしてください。
分散分析とは?「平均の差」を"分散"で判定する理由を初心者向けに完全図解 →
目次
分散分析表とは?まず完成形を見る
計算手順に入る前に、「ゴールはこれだ!」というイメージを持つことがとても大切です。ここで道に迷わないために、まず完成形を見ておきましょう。
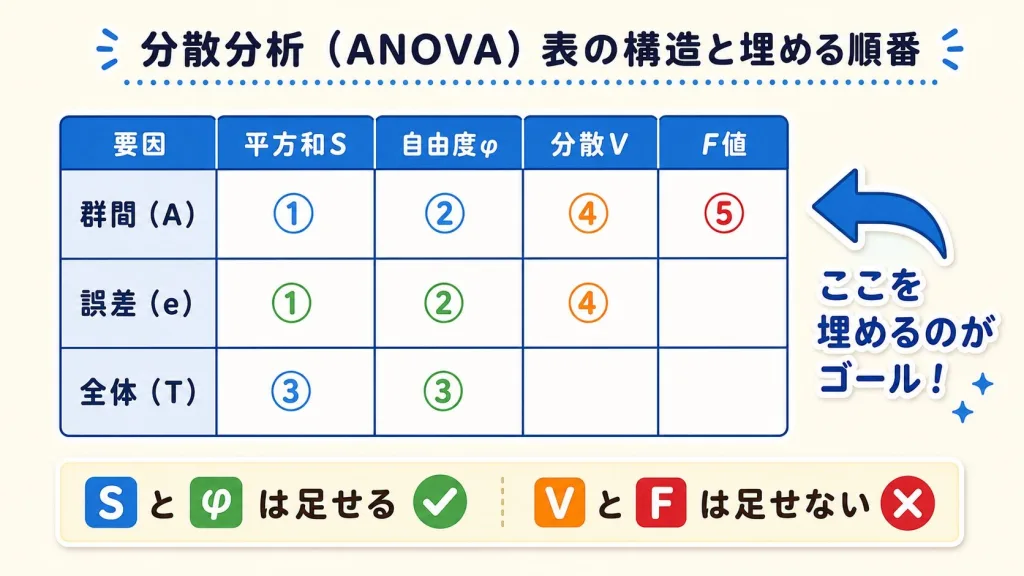
これが分散分析表(ANOVA表)の完成形
| 要因 | 平方和 S | 自由度 φ | 分散 V | F₀ | 判定 |
|---|---|---|---|---|---|
| 群間(A) | SA | φA | VA | F₀ | **または ns |
| 誤差(e) | Se | φe | Ve | — | — |
| 全体(T) | ST | φT | — | — | — |
これからやることは、たった1つ。
「この表のマスを、左から右へ、上から下へ、5ステップで埋めていく」──ただそれだけです。
記号の意味を整理しておく
| 記号 | 読み方 | 意味 |
|---|---|---|
| CT | シーティー(修正項) | 平方和計算の準備に使う"基準値" |
| ST | エス・ティー(総平方和) | データ全体のバラつきの合計 |
| SA | エス・エー(群間平方和) | グループ間のバラつき(因子の効果) |
| Se | エス・イー(群内平方和・誤差平方和) | グループ内のバラつき(偶然の誤差) |
| φ | ファイ(自由度) | 平方和を「ならす」ための割る数 |
| V | ブイ(分散・平均平方) | S を φ で割った、ならしたバラつき |
| F₀ | エフ・ゼロ(観測されたF値) | VA ÷ Ve。差の判定指標 |
計算の5ステップ|全体の地図
修正項 CT を計算する
CT = T² ÷ N。すべての平方和計算で使う"出発点"。
平方和 S を3種類計算する
総平方和 ST、群間平方和 SA、群内平方和 Se。Se = ST − SA の引き算でOK。
自由度 φ を計算する
φT = N−1、φA = a−1、φe = N−a。
分散 V を計算する
V = S ÷ φ。割り算するだけ。
F₀ を計算してF分布表で判定する
F₀ = VA ÷ Ve。F表の値と比較して有意差判定。
分散分析の計算は「上から下へ流れる」イメージで覚えてください。
CT → 平方和 → 自由度 → 分散 → F値 → 判定。
どこか1つでも怪しくなったら、「自分は今、どのステップにいる?」と問い直すと迷子になりません。
STEP1:修正項CT(CT)を計算する
分散分析の計算で最初に必ず出てくる謎の記号が「CT」です。
「Correction Term(修正項)」の略で、すべての平方和計算で使う"スタート地点"。
これを最初に押さえれば、あとは芋づる式に表が埋まっていきます。
CTの公式
T:データの合計値(全データを足したもの)
N:データの総数(全データの個数)
CTとは何か?|なぜ最初に引くのか
CTを一言で説明すると、「全データの平均から計算される基準値」です。
実は、CT = T²/N は 「全データの平均」×「データの合計」と同じ意味。つまり「全体の平均レベルが作るバラつきの基準」を表します。
平方和を計算するとき、本来なら「各データ − 全体平均」を2乗して合計します。
でも、それを毎回やるのは面倒。そこで数学的に式変形すると、
「データの2乗の合計」− CT
という形でラクに計算できることが分かっています。
つまりCTは、「面倒な引き算をまとめて一発で済ますためのショートカット」なんです。
CTの計算例|カレーの試食データで実演
例として、3種類のカレー配合(A・B・C)で各5人が試食して10点満点で評価したデータを使います。
| 配合A | 配合B | 配合C |
|---|---|---|
| 6 | 8 | 7 |
| 7 | 7 | 6 |
| 5 | 9 | 8 |
| 6 | 8 | 7 |
| 6 | 8 | 7 |
| 合計 30 | 合計 40 | 合計 35 |
各配合の合計、全データの合計、データ数を出します。
配合A合計:6+7+5+6+6 = 30
配合B合計:8+7+9+8+8 = 40
配合C合計:7+6+8+7+7 = 35
T(全データの合計):30+40+35 = 105
N(全データ数):5×3 = 15
これでCTが計算できます。
CT = T² ÷ N
= 105² ÷ 15
= 11025 ÷ 15
= 735
CT = T²/N の T を「全データの平均」と勘違いするミスが多いです。
Tは「全データを足した合計値」。平均ではありません。落ち着いて式を確認しましょう。

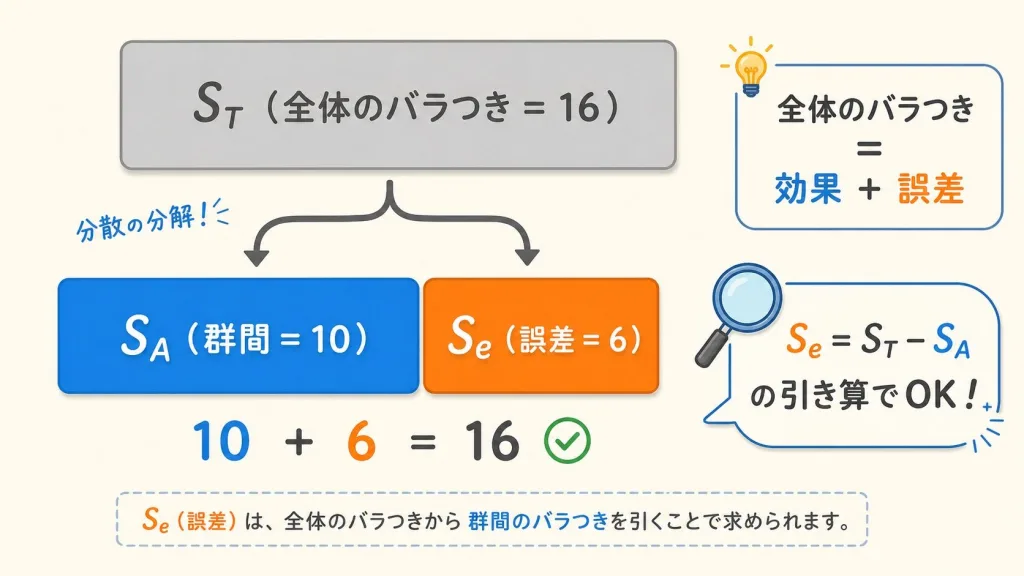
STEP2:平方和を3種類に分解する(計算の心臓部)
ここが分散分析の計算の心臓部です。
全体のバラつき(ST)を「群間のバラつき(SA)」と「群内のバラつき(Se)」に分解します。
平方和分解の公式
ST = SA + Se
(全体のバラつき = 群間のバラつき + 群内のバラつき)
ST と SA さえ計算できれば、Se は 引き算で出せます。
Se = ST − SA
つまり、計算する平方和は実質「ST と SA の2つだけ」。これがわかると気持ちが楽になります。
① 総平方和 ST を計算する
総平方和 ST は「全データのバラつきの合計」。データ全部を1つの集団とみなしたときのバラつきです。
ST = Σx² − CT
Σx²:全データを1つずつ2乗してから合計したもの
CT:先ほど計算した修正項(=735)
カレーデータで計算します。各データを2乗して全部足します。
配合A:6² + 7² + 5² + 6² + 6² = 36 + 49 + 25 + 36 + 36 = 182
配合B:8² + 7² + 9² + 8² + 8² = 64 + 49 + 81 + 64 + 64 = 322
配合C:7² + 6² + 8² + 7² + 7² = 49 + 36 + 64 + 49 + 49 = 247
Σx² = 182 + 322 + 247 = 751
ST = Σx² − CT
= 751 − 735
= 16
② 群間平方和 SA を計算する
群間平方和 SA は「グループ平均同士のバラつき」。配合A・B・Cの平均がどれだけ離れているかを表します。
これが「因子の効果」に対応します。
Ti:i番目のグループの合計値
n:各グループのデータ数(繰返し数)
a:水準数(グループの数)
カレーデータで計算します。
各配合の合計:TA=30, TB=40, TC=35
各配合の2乗:30² + 40² + 35² = 900 + 1600 + 1225 = 3725
n(繰返し数):各配合5人 → n=5
SA = (TA² + TB² + TC²) ÷ n − CT
= 3725 ÷ 5 − 735
= 745 − 735
= 10
③ 群内平方和(誤差平方和)Se を計算する
ここが裏ワザの出番。Se は 引き算で一発です。
Se = ST − SA
Se = ST − SA
= 16 − 10
= 6
ここまでの結果を表に書き込む
| 要因 | 平方和 S | 自由度 φ | 分散 V | F₀ |
|---|---|---|---|---|
| 群間(A) | 10 | ? | ? | ? |
| 誤差(e) | 6 | ? | ? | — |
| 全体(T) | 16 | ? | — | — |
平方和の列がすべて埋まりました。SA + Se = 10 + 6 = 16 = ST となっていることを必ず確認してください。これが検算になります。
STEP3:自由度φを求める
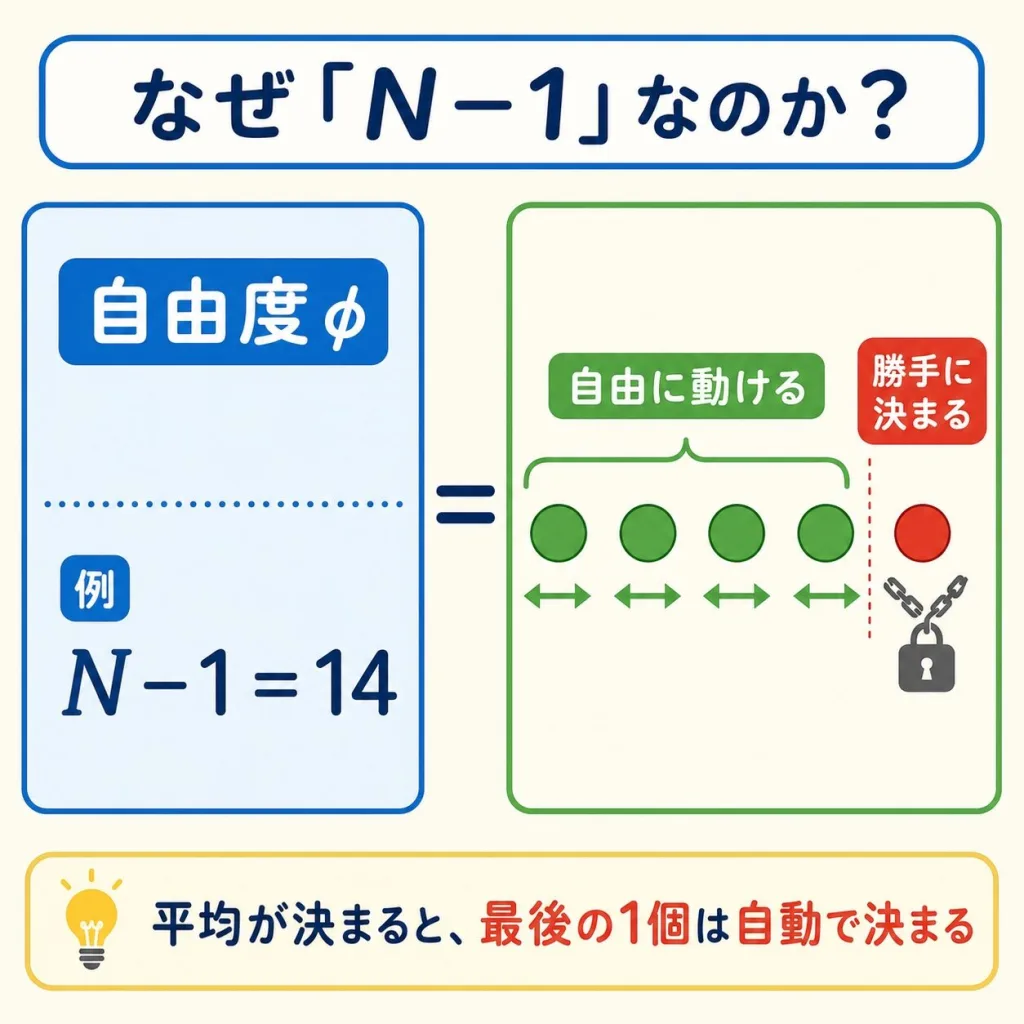
自由度(φ:ファイ)は「平方和をならすときに割る数」。
難しく考える必要はありません。引き算で出るだけです。
自由度の3つの公式
φT(全体の自由度)= N − 1
φA(群間の自由度)= a − 1
φe(誤差の自由度)= N − a
N:全データ数 a:水準数(グループ数)
自由度も平方和と同じく φA + φe = φT が成立します。
計算が合っているかを確認するのに便利な性質です。
なぜ「n−1」「a−1」と1引くのか?
「自由度って何?なぜ1引くの?」は、誰もが一度はぶつかる疑問です。
ざっくり言うと、「平均を1つ計算した時点で、自由に動けるデータの数が1個減るから」です。
例えばデータが5個あって、平均が「7」と決まっているとします。
1番目〜4番目は好きな値を入れられますが、5番目だけは「合計が35になるように」自動で決まってしまいます。
つまり、自由に動けるのは 5 − 1 = 4 個。これが自由度の正体です。
カレーデータで自由度を計算
今回のカレー実験は、N=15(5人×3配合)、a=3(配合A・B・C)です。
φT = N − 1 = 15 − 1 = 14
φA = a − 1 = 3 − 1 = 2
φe = N − a = 15 − 3 = 12
検算:φA + φe = 2 + 12 = 14 = φT ✅
| 要因 | 平方和 S | 自由度 φ | 分散 V | F₀ |
|---|---|---|---|---|
| 群間(A) | 10 | 2 | ? | ? |
| 誤差(e) | 6 | 12 | ? | — |
| 全体(T) | 16 | 14 | — | — |
STEP4:分散(平均平方 V)を計算する
ここまでくればゴールが見えてきました。
分散 V は「平方和 S を自由度 φ で割るだけ」。電卓があれば数秒で出ます。
分散の公式
分散分析の文脈では、V を 「平均平方(Mean Square)」 と呼ぶこともあります。
意味は同じ。「1個あたりにならしたバラつき」のことです。
平方和(バラつきの合計)を自由度(割る数)で割ると、1個あたりのバラつきになる──そう覚えておけばOK。
VA と Ve を計算する
分散分析では、必要な分散は VA(群間分散) と Ve(誤差分散) の2つだけです。
全体分散 VT は計算しなくてOK(だから表でも「—」になっています)。
VA = SA ÷ φA = 10 ÷ 2 = 5
Ve = Se ÷ φe = 6 ÷ 12 = 0.5
ここまでの表
| 要因 | 平方和 S | 自由度 φ | 分散 V | F₀ |
|---|---|---|---|---|
| 群間(A) | 10 | 2 | 5 | ? |
| 誤差(e) | 6 | 12 | 0.5 | — |
| 全体(T) | 16 | 14 | — | — |
VA(5)+ Ve(0.5)= 5.5 となりますが、これは VT ではありません。
「平方和は足せる、自由度も足せる、でも分散は足せない」──これが分散分析のルールです。
STEP5:F₀を求めてF分布表で判定する
いよいよ最後のステップ。「配合の違いに本当に差があるのか?」を判定します。
F₀の公式
これは「効果の大きさ」÷「誤差の大きさ」。
F₀ が大きいほど、誤差では説明できない差がある、つまり因子の効果があると判定できます。
F₀の計算
F₀ = VA ÷ Ve
= 5 ÷ 0.5
= 10
F分布表の使い方|どこを見るのか
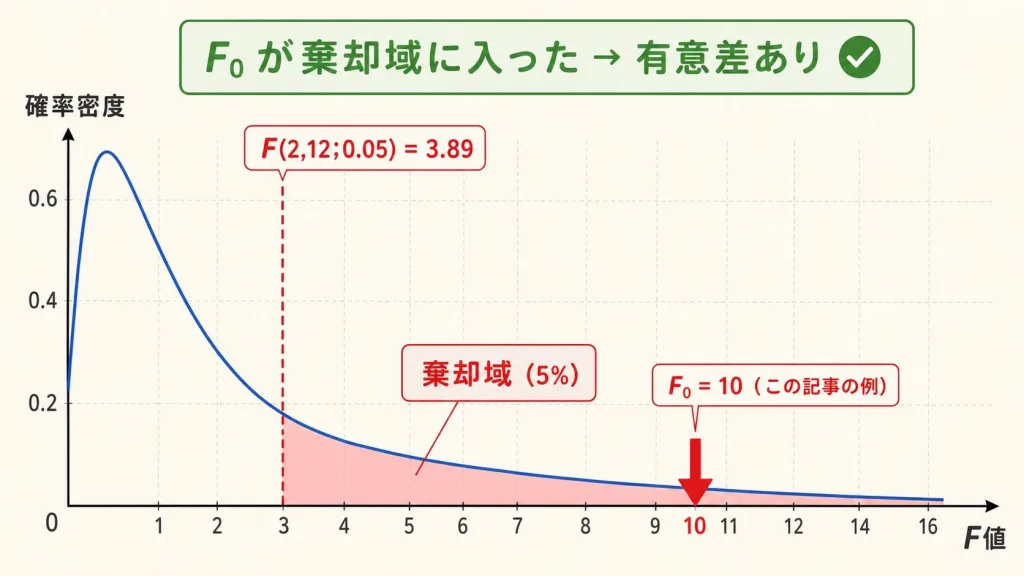
F₀ = 10 が出ましたが、これだけでは判定できません。
「F分布表」と呼ばれる表に書かれた基準値(F(φ1, φ2; α))と比較する必要があります。
φ1(分子の自由度):群間の自由度 φA
φ2(分母の自由度):誤差の自由度 φe
α(有意水準):普通は 0.05(5%)か 0.01(1%)
F分布表の引き方(実例)
今回は φ1 = 2、φ2 = 12、α = 0.05 で表を引きます。
F分布表(α=0.05用)を開く
横の列から φ1=2 を探す
縦の列から φ2=12 を探す
交差点の値を読む → F(2, 12; 0.05) = 3.89
F分布表の例(α=0.05、上側%点)
| φ2 \ φ1 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 10 | 4.96 | 4.10 | 3.71 | 3.48 | 3.33 |
| 11 | 4.84 | 3.98 | 3.59 | 3.36 | 3.20 |
| 12 | 4.75 | 3.89 | 3.49 | 3.26 | 3.11 |
| 13 | 4.67 | 3.81 | 3.41 | 3.18 | 3.03 |
上の表で、φ1=2 と φ2=12 が交差する場所が 3.89。これが基準値です。
判定ルール
F₀ ≧ F表の値
「有意差あり」と判定
→ 配合の違いに本当に差がある
(記号で「**」と書く)
F₀ < F表の値
「有意差なし」と判定
→ 差は誤差の範囲内
(記号で「ns」と書く)
カレーデータの判定
F₀ = 10 vs F(2, 12; 0.05) = 3.89
10 > 3.89 → 有意差あり(**)
つまり、3つの配合の間には「偶然では説明できない」差があると判定できます。
分散分析で分かるのは「どこかに差がある」ということだけです。
「A対B」「B対C」など、どの組み合わせに差があるかを調べるには、多重比較法(テューキー法など)を別途行う必要があります。
例題:カレーの試食データで分散分析表を1から完成させる
ここまでの5ステップを一気に通して復習しましょう。
この章では、データを見るところから判定までを1問通しで解きます。手元に紙と電卓を用意して、一緒に手を動かしてください。
問題設定
あるカレー店で、3種類のスパイス配合(A・B・C)を試作し、それぞれ5人の評価員に10点満点で採点してもらった。
配合によって評価点に差があると言えるか、有意水準 α = 0.05 で分散分析を行いなさい。
| No. | 配合A | 配合B | 配合C |
|---|---|---|---|
| 1 | 6 | 8 | 7 |
| 2 | 7 | 7 | 6 |
| 3 | 5 | 9 | 8 |
| 4 | 6 | 8 | 7 |
| 5 | 6 | 8 | 7 |
| 合計 | 30 | 40 | 35 |
| 平均 | 6.0 | 8.0 | 7.0 |
解答|5ステップで一気に解く
T = 30 + 40 + 35 = 105 N = 5×3 = 15
CT = T² ÷ N = 105² ÷ 15 = 11025 ÷ 15 = 735
【Σx²の計算】
A:6²+7²+5²+6²+6² = 182
B:8²+7²+9²+8²+8² = 322
C:7²+6²+8²+7²+7² = 247
Σx² = 182 + 322 + 247 = 751
【総平方和】
ST = Σx² − CT = 751 − 735 = 16
【群間平方和】
SA = (30² + 40² + 35²) ÷ 5 − 735 = 3725 ÷ 5 − 735 = 745 − 735 = 10
【誤差平方和】
Se = ST − SA = 16 − 10 = 6
φT = N − 1 = 15 − 1 = 14
φA = a − 1 = 3 − 1 = 2
φe = N − a = 15 − 3 = 12
VA = SA ÷ φA = 10 ÷ 2 = 5
Ve = Se ÷ φe = 6 ÷ 12 = 0.5
F₀ = VA ÷ Ve = 5 ÷ 0.5 = 10
F(2, 12; 0.05) = 3.89 → F₀ = 10 > 3.89
∴ 有意差あり(**):配合の違いが評価点に影響している
完成した分散分析表
| 要因 | 平方和 S | 自由度 φ | 分散 V | F₀ | 判定 |
|---|---|---|---|---|---|
| 群間(A) | 10 | 2 | 5.0 | 10.0 | ** |
| 誤差(e) | 6 | 12 | 0.5 | — | — |
| 全体(T) | 16 | 14 | — | — | — |
これで分散分析表が1から完成しました。
「データを見たら → 5ステップで表を埋めて → F分布表と比較して判定」。
この型さえ覚えれば、データが変わってもまったく同じ手順で解けます。

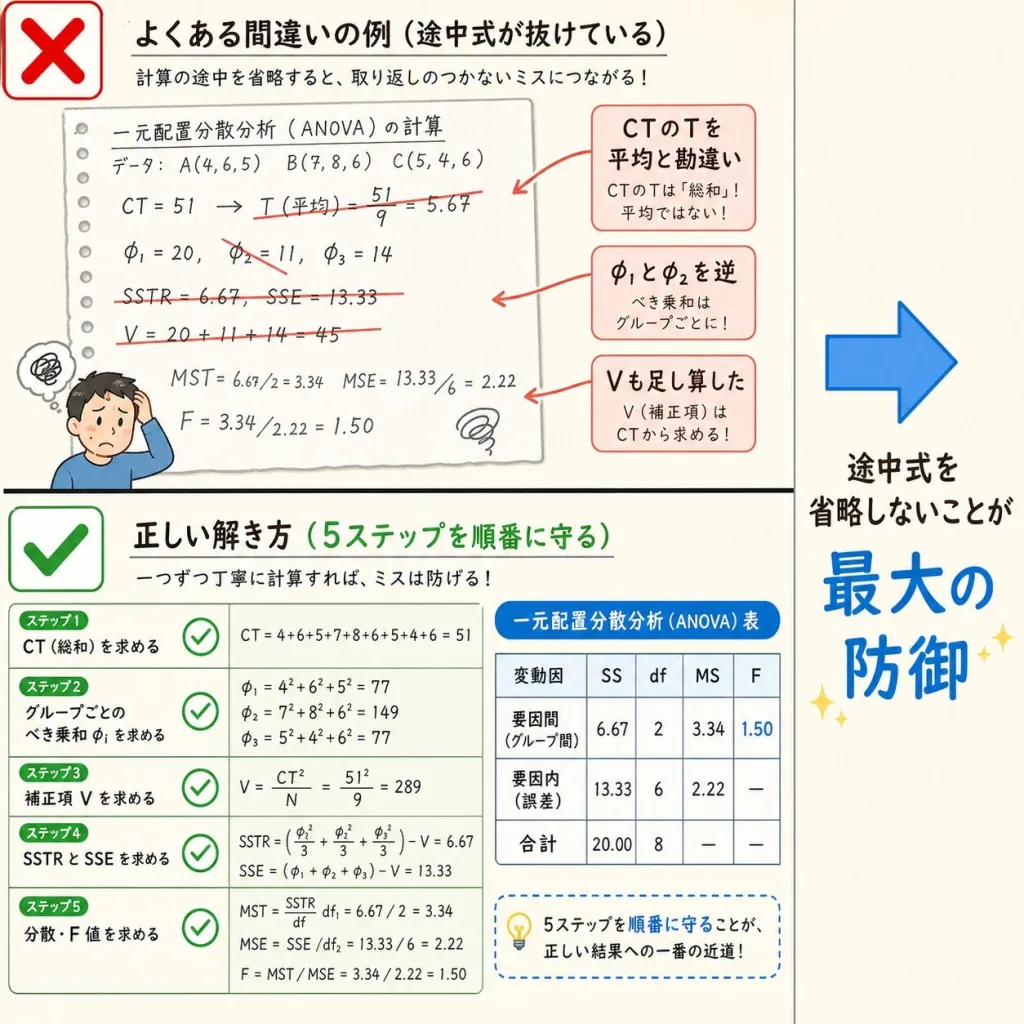
よくあるつまずきポイントと対処法
分散分析の計算でつまずく定番ポイントを5つ、対処法とセットで紹介します。
つまずき①|平方和の検算が合わない
SA + Se が ST と一致しない
まずCTを計算し直す。CT = T²/N で、T は全データの合計(平均ではない)。
次に Σx² を確認。「2乗してから足す」。「足してから2乗」ではない。
最後にSAの式 (TA² + TB² + TC²)/n を確認。グループ合計の2乗を足してからnで割る。
つまずき②|自由度を間違える
「N」と「a」と「n」がごちゃごちゃになる
記号を一覧で整理すること:
N = 全データ数(カレー例:15)
a = 水準数(カレー例:3)
n = 各水準のデータ数(カレー例:5)
そして、N = a × n の関係を必ず確認する。
つまずき③|分散も足し算できると思ってしまう
VA + Ve = VT だと思って計算してしまう
足し算が成立するのは「平方和」と「自由度」だけ。
「分散」と「F値」は足し算できません。分散分析表でも、VT の欄は「—」になっています。
つまずき④|F分布表のφ1とφ2を逆に引く
F表で φ1 と φ2 を取り違えて、間違った基準値で判定する
F₀ = VA ÷ Ve の分子の自由度がφ1(=φA)、分母の自由度がφ2(=φe)。
F分布表は「横軸=分子の自由度」「縦軸=分母の自由度」と覚える。
つまずき⑤|有意差ありで満足してしまう
「有意差あり」で結論を終え、「どの配合が一番良いのか」を答えない
分散分析が言うのは「どこかに差がある」だけ。「Bが一番」と結論するには多重比較法か、各水準の母平均の点推定・区間推定を別途行う。
分散分析はゴールではなく、「次の解析への入口」と覚えておく。
よくある質問(FAQ)
Q1. 修正項CTを使わずに計算する方法はありますか?
あります。「各データ − 全体平均」を全部2乗して足せば、CTを使わずに ST が計算できます。ただし手計算では非常に面倒。CT方式の方が圧倒的にラクです。QC検定でも統計検定でも、CT方式が標準的に使われています。
Q2. 繰返し数が水準ごとに違っても計算できますか?
できます。ただし SA の式が少し変わります。
SA = TA²/nA + TB²/nB + TC²/nC − CT
(各水準ごとに合計の2乗をそのデータ数で割る)。本記事のように繰返し数が同じなら、全体をnで割れます。
Q3. Excelで分散分析できますか?
できます。「データ」タブ→「データ分析」→「分散分析:一元配置」を選ぶだけで、本記事の表とまったく同じ結果が出ます。ただし手計算を一度経験せずにExcelに頼ると、出力結果の意味がわからなくなるのでおすすめしません。
Q4. 「**」と「*」の違いは何ですか?
慣習として、「*」は α=0.05 で有意(少し差がある)、「**」は α=0.01 で有意(はっきり差がある)を表します。本記事のカレー例では、α=0.01の基準値 F(2, 12; 0.01) = 6.93 と比較すると F₀=10 > 6.93 なので、「**」を付けても問題ありません。
Q5. データに外れ値があるときはどうしますか?
分散分析は外れ値の影響を受けやすい手法です。明らかな異常値(記入ミス、実験ミスなど)は除外する、またはノンパラメトリック検定(クラスカル・ウォリス検定)に切り替えるなどの対応が必要。「データの正規性」と「等分散性」が分散分析の前提なので、事前にヒストグラムや箱ひげ図で確認することをおすすめします。
Q6. 因子が2つ以上のときはどう計算しますか?
因子が2つになると「二元配置分散分析」と呼ばれ、計算量が増えます。基本の考え方(平方和を分解→自由度で割って分散→F値で判定)は同じですが、「交互作用」という新しい概念が加わります。一元配置の計算をマスターしてから取り組むのが鉄則です。
まとめ|分散分析表は「5ステップ」で必ず完成する
- 分散分析表は CT → 平方和S → 自由度φ → 分散V → F値 の5ステップで埋める
- CT = T²/N。全データの合計を2乗してデータ数で割る
- 平方和は ST = Σx² − CT、SA = ΣTi²/n − CT、Se = ST − SA
- 自由度は φT=N−1、φA=a−1、φe=N−a。引き算するだけ
- 分散は V = S ÷ φ。割るだけ
- F₀ = VA ÷ Ve。F分布表の値より大きければ有意差あり
- 足せるのは「平方和」と「自由度」のみ。分散とF値は足せない
分散分析表が完成したら、次は「最適水準の推定」へ進みましょう。
「どの配合が一番良いのか?」「その平均値の信頼区間は?」を計算する点推定・区間推定が、分散分析の真の到達点です。
📚 次に読むべき記事
実験計画法全体のロードマップ。分散分析が体系の中でどこに位置するか、次に学ぶべき分野が一目でわかります。
分散分析で「有意差あり」となった後の応用編。「どの水準が一番良いか」を数値で具体的に推定する手順です。
因子が2つになるとどう計算するか。「交互作用」という新概念を含む、一元配置のすぐ次のステップ。