」なのか腑に落ちない F){kind=link}
- 「平均は同じくらいなのに、製品のバラつきが気になる」けど比べ方がわからない
- なぜ分散の比較は「引き算」ではなく「割り算(比)」なのか腑に落ちない
- F検定・カイ二乗検定・Welchの検定、どれをいつ使うか混乱する
- QC検定でF分布表の読み方や、Welchの「線形補間」でつまずく
- F検定(等分散の検定)の考え方と分散比の計算手順(例題つき)
- なぜ「比」を使うのか=F分布のイメージ
- 3つ以上のバラつきを比べるハートレーの検定
- 等分散でない2群の平均を比べるWelchの検定と「線形補間」
- 1つの母分散を調べるカイ二乗検定・区間推定(Z検定との違いも)
F検定(等分散の検定)とは、2つのグループのバラつき(分散)に差があるかを判定する検定です。
やることは1つ。2つの不偏分散の比(大きい方÷小さい方)を計算し、F分布表の値と比べるだけ。比が1に近ければバラつきは同じ、1から大きく離れればバラつきが違うと判断します。
「割合・平均」ではなく「バラつきそのもの」を比べるのが、この分野の特徴です。
目次
F検定とは?なぜ「差」ではなく「比」で比べるのか
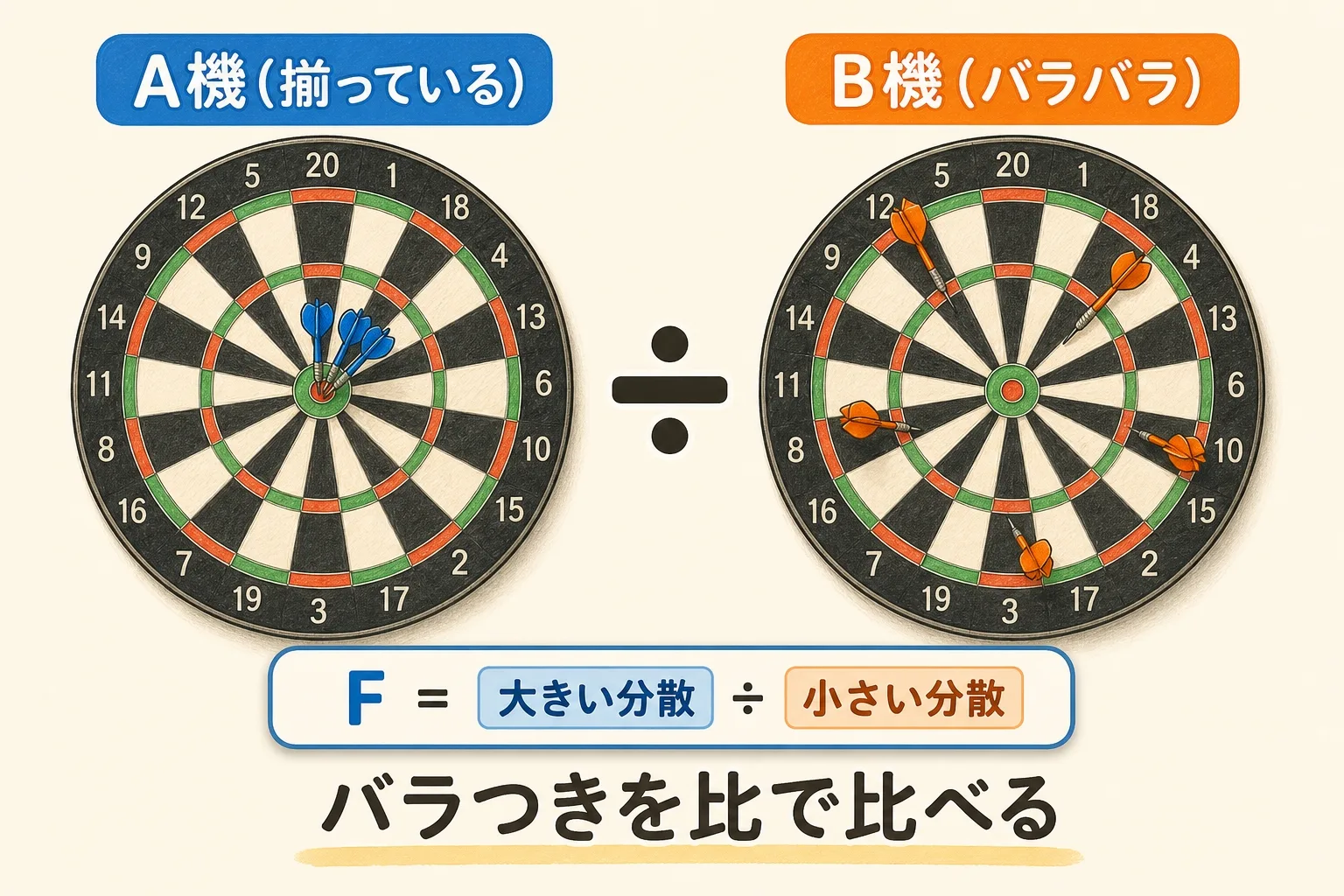
F検定は「2つのグループのバラつき(分散)が同じかどうか」を調べる検定です。たとえば、同じ部品を作るA機械とB機械。平均寸法は同じでも、A機は寸法がそろっていて、B機はバラバラなら、精度が良いのはA機ですよね。この「バラつきの差」を統計的に判定するのがF検定です。
平均の比較では「A−B」と引き算をします。でも分散の比較では「A÷B」と割り算(比)を使います。これがF検定の正体で、最初につまずくポイントです。理由を次で説明します。
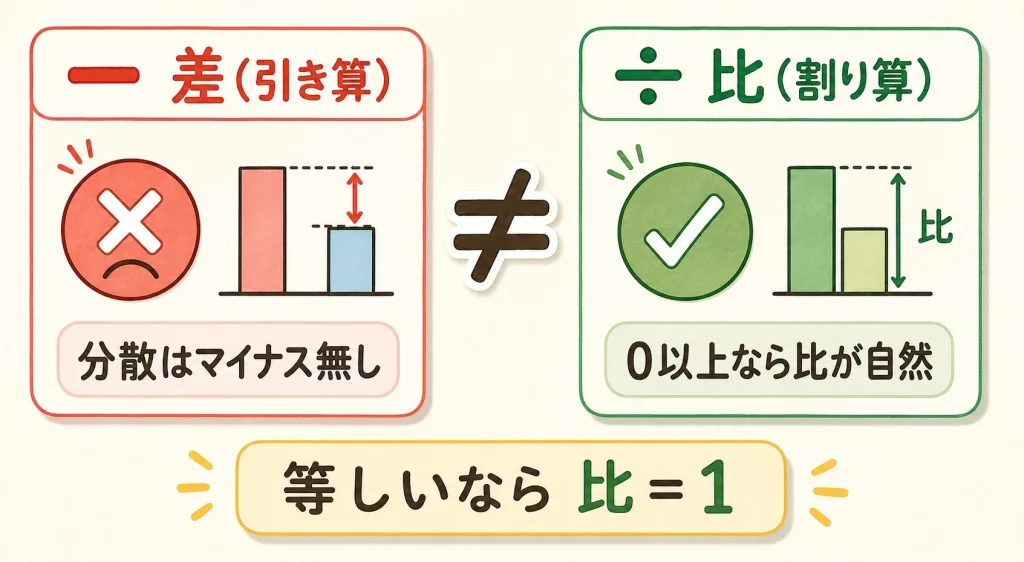
「比」を使う理由|分散はマイナスにならないから
分散は「バラつきの2乗の平均」なので、絶対にマイナスにならず、0以上の値になります。0以上の2つの量を比べるとき、自然なのは「何倍か(比)」を見ることです。
「2と4」の差は2、「100と102」の差も2。でも前者は「2倍」も違い、後者は「ほぼ同じ」です。0以上の量は、差より比のほうが実態に合うのです。
だから「2つの分散が同じなら、比は1になるはず」という考えでF検定が組み立てられています。
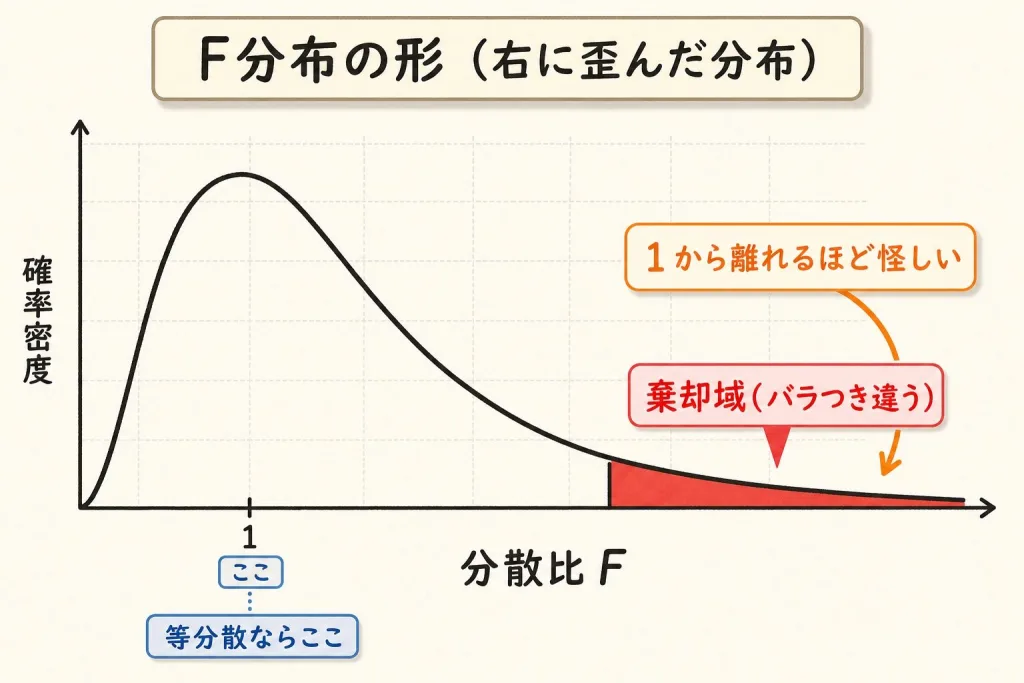
F分布のイメージ|「1」が中心の山
F分布は、この「分散比」が従う分布です。2つの分散が本当は等しいなら、比はだいたい1の周りに集まるはず。だからF分布は1付近に山があり、右に長く裾を引く非対称な形をしています。
比が1から大きく離れる(=F₀が大きくなる)ほど、「偶然では説明できないほどバラつきが違う」ことになります。F分布表で決めた境界線(棄却限界値)を超えたら「等分散とは言えない」と判定します。
F検定の計算手順|A機とB機、精度がいいのはどっち
実際に手を動かしてみましょう。A機とB機で部品の寸法を測り、バラつきに差があるかを有意水準5%(両側)で検定します。
| 機械 | データ数 n | 不偏分散 V |
|---|---|---|
| A機 | 10 | 0.45 |
| B機 | 8 | 0.15 |
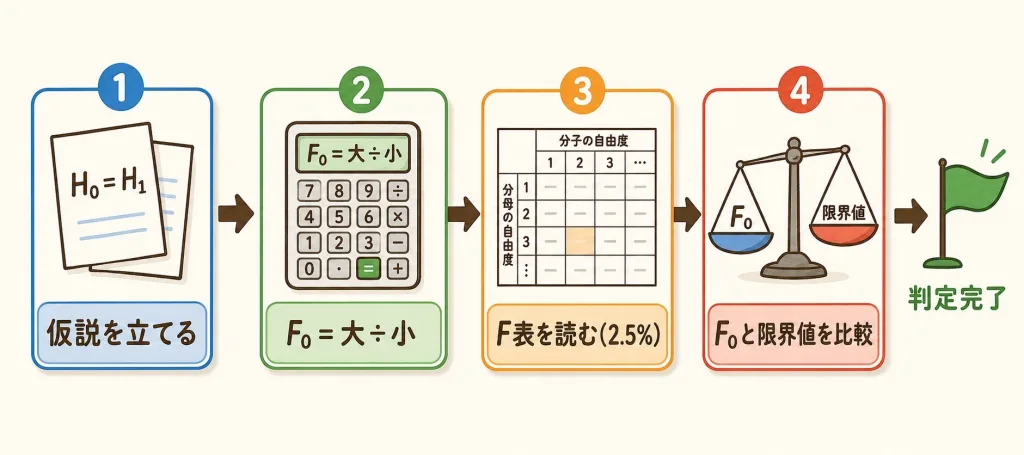
仮説を立てる
H₀:σ₁²=σ₂²(バラつきは等しい)/ H₁:σ₁²≠σ₂²(バラつきが違う・両側)
分散比F₀を計算(大きい方÷小さい方)
F₀ = 0.45 ÷ 0.15 = 3.0
このとき分子の自由度 φ₁=10−1=9、分母の自由度 φ₂=8−1=7。
F分布表から棄却限界値を読む
両側5%なので、片側2.5%(0.025)の表を使う。F(9, 7; 0.025) ≒ 4.82。
判定する
F₀=3.0 < 4.82 なので棄却できない →「A機とB機のバラつきに差があるとは言えない」。
有意水準5%の両側検定でも、F分布表は片側2.5%(0.025)の表を引きます。常に「大÷小」で右側だけを見るので、5%を両側に分けた片方(2.5%)を使うのです。ここを5%の表で引いてしまうミスが多いので注意してください。
分散と標準偏差|「バラつき」を数値化する魔法の公式 →
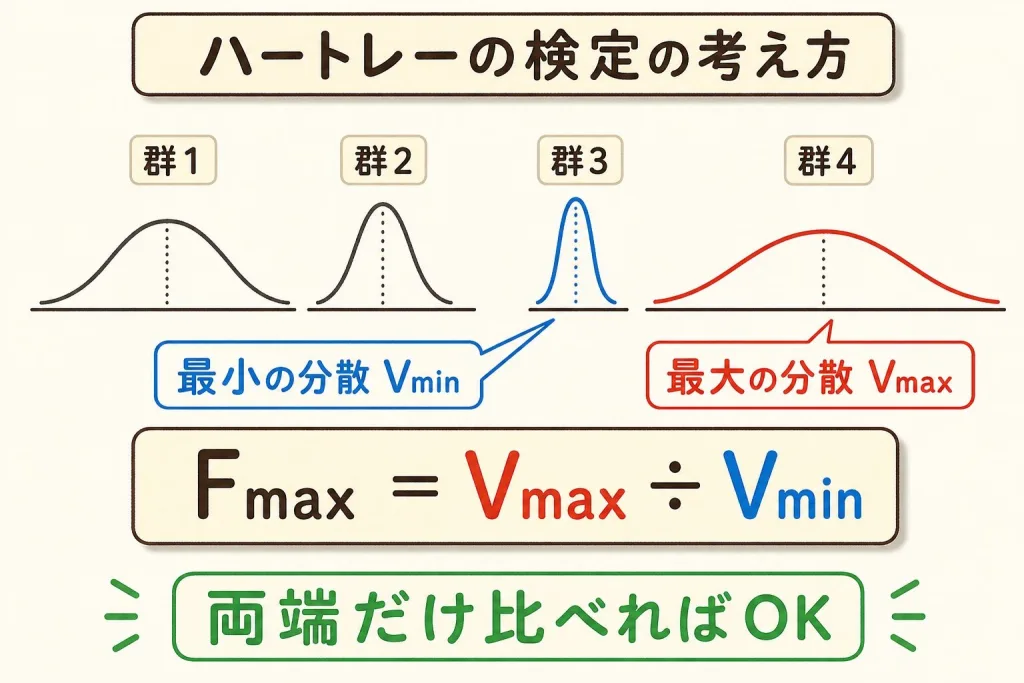
3つ以上のバラつきを比べる|ハートレーの検定
F検定は2つのバラつきの比較でした。では3つ以上のグループのバラつきが「全部そろっているか」を一気に調べたいときは?そこで使うのがハートレーの検定です。
考え方はシンプルで、「一番バラついている子」と「一番揃っている子」だけを取り出して比べる方法です。両端さえ問題なければ、間のグループも問題ないだろう、という発想です。
ハートレーの検定は各グループのサンプル数が同じ(等しいn)であることが前提です。データ数がバラバラの場合は、バートレットの検定など別の手法を使います。
なお、ハートレー表は「群の数 k」と「各群の自由度 φ」で限界値が決まります。Fmax が表の値を超えたら「等分散とは言えない(バラつきがそろっていない)」と判定します。
3つ以上の平均を比べる分散分析(ANOVA)は、「各群のバラつきが同じ」が前提です。だから本番の前に、ハートレーやバートレットの検定で等分散性をチェックすることがあります。
等分散でないとき|Welchの検定と線形補間
F検定で「2群のバラつきは違う(等分散でない)」とわかったとします。このとき、その2群の平均を比べたいなら、普通のt検定は使えません。等分散を前提としないWelch(ウェルチ)の検定の出番です。
① F検定で等分散かどうかを確認
② 等分散なら → 普通の2標本t検定
③ 等分散でないなら → Welchの検定
Welchはバラつきが違っても使える「万能型のt検定」と覚えておけば十分です。
普通のt検定は2群のバラつきを1つにまとめて(プールして)使いますが、Welchはバラつきが違うので、それぞれ別々に扱うのが特徴です。
最難関:Welchの「等価自由度 φ*」の計算
Welchの検定が難しいのは、自由度が整数にならない「等価自由度(φ*)」を計算する点です。サタースウェイトの式で求めます。
自由度が小数になる!?「線形補間」で表を読む
等価自由度は「7.4」のように小数になります。ところがt分布表には整数(7や8)しか載っていません。そこで「7のときの値」と「8のときの値」のあいだを比例配分で求める=線形補間(直線補間)を使います。
・t(7) = 2.365、t(8) = 2.306 とする
・7と8の間で「7.4」は 0.4 の位置
・差は 2.306 − 2.365 = −0.059
・補間値 = 2.365 + (−0.059)×0.4 = 2.365 − 0.0236 = 約 2.341
「2点を直線で結んで、その途中の値を読む」だけ。中学で習った比例配分と同じです。
自由度が30を超えると、直線補間より逆数(1/φ)で補間するほうが正確とされます。ただしQC検定では自由度が小さい範囲が多く、線形補間で対応できる出題がほとんどです。
1つの母分散を調べる|カイ二乗検定(この機械、バラつき増えてない?)
ここまでは「2つ以上のバラつきの比較」でした。次は「1つの機械のバラつきが、基準値より大きくなっていないか」を調べます。比べる相手が決まった基準値(σ₀²)なので、F分布ではなくカイ二乗分布を使います。
やることは、「実際のバラつきの合計(平方和S)」を「基準のバラつき(σ₀²)」で割るだけです。値が大きければ「基準よりバラついている」ことになります。
例題:バラつきが基準より増えたか
基準の母分散は σ₀²=0.20 でした。最近、16個(n=16)のデータから平方和 S=4.5 が得られました。バラつきが増えたか、有意水準5%(片側)で検定します。
仮説:H₀:σ²=0.20 / H₁:σ²>0.20(増えた・片側)。自由度 φ=16−1=15。
χ₀²を計算:χ₀² = 4.5 ÷ 0.20 = 22.5
棄却限界値を読む:「増えたか」を見るので上側を使う。χ²(15; 0.05) ≒ 24.996。
判定:χ₀²=22.5 < 24.996 なので棄却できない →「バラつきが増えたとは言えない」。
カイ二乗分布は左右対称ではありません。だから「バラつきが増えたか(上側)」「減ったか(下側)」「変わったか(両側)」で、表のどちら側を読むかが変わります。
・増えた? → 上側(例:0.05)
・減った? → 下側(例:0.95)
・変わった?(両側5%) → 上側0.025 と 下側0.975 の両方
ここは間違えやすいので、詳しくは下の関連記事で確認してください。
【参考】Z検定(母分散が既知の場合)
教科書には「母分散が分かっている前提のZ検定」も出てきます。ただし現実には母分散が分かっていることはほぼなく、実務では使いません。「神様だけが真の分散を知っている」という理論上の話です。
Z検定はすべての検定の「原型」だからです。「真のバラつきが分かれば正規分布(Z)で判定できる」という基礎を理解すると、「分からないからt分布やカイ二乗分布で代用する」という応用がスッと入ります。試験では深追いせず、考え方の土台として押さえれば十分です。
母分散の区間推定|本当のバラつきはどの範囲か
検定が「基準より大きいか」を判定するなら、推定は「本当の母分散はどの範囲にあるか」を予測します。母分散の区間推定も、検定と同じくカイ二乗分布を使います。
区間の下限を出すには大きいカイ二乗値(上側0.025)で割り、上限を出すには小さいカイ二乗値(下側0.975)で割ります。
「大きい数で割ると小さくなる=下限、小さい数で割ると大きくなる=上限」と考えれば納得できます。カイ二乗が非対称だからこそ起きる、引っかけ問題の定番です。
例題:母分散の信頼区間を求める
n=16(φ=15)、平方和 S=4.5 のとき、母分散 σ² の95%信頼区間を求めます。
カイ二乗値を読む(φ=15)
上側 χ²(15; 0.025)=27.488 / 下側 χ²(15; 0.975)=6.262
下限を計算:4.5 ÷ 27.488 ≒ 0.164
上限を計算:4.5 ÷ 6.262 ≒ 0.719
→ 母分散の95%信頼区間は 0.164 ≦ σ² ≦ 0.719
品質管理では、区間の上限に注目します。「本当のバラつきは、悪くてもこのくらいまで」という最悪値の見積もりになるからです。標準偏差で見たいときは、区間の両端の平方根をとればσの区間になります。
全体マップ|分散の検定はどれをいつ使うか
「バラつきの検定」は種類が多くて迷いますが、①いくつのグループを比べるか ②相手は基準値か他のグループかで整理すれば一発で選べます。
1つのグループ vs 基準値 → カイ二乗検定(母分散の検定・区間推定)
※真の分散が既知という理論なら参考としてZ検定
2つのグループのバラつき比較 → F検定(分散比)
3つ以上のバラつき比較 → ハートレーの検定(nが等しいとき)/バートレットの検定(nが違うとき)
| 調べたいこと | 使う手法 | 使う分布 |
|---|---|---|
| 1つの分散 vs 基準値 | 母分散の検定・区間推定 | カイ二乗分布 |
| 2つの分散の比較 | F検定(等分散の検定) | F分布 |
| 3群以上の分散(n等しい) | ハートレーの検定 | Fmax分布 |
| 等分散でない2群の平均 | Welchの検定 | t分布(等価自由度) |
よくある質問(FAQ)
A. 分散は0以上の値しか取らないため、差より比(何倍か)で比べるのが自然だからです。等しいなら比は1になり、F分布で判定できます。
A. 常に「大きい方÷小さい方」で右側だけを見るため、両側5%を片側に直した2.5%(0.025)の表を引きます。
A. 2つの分散を比べるならF検定、1つの分散を基準値と比べるならカイ二乗検定です。比較する相手が「他の群」か「決まった値」かで決まります。
A. 等価自由度が小数になるため、t分布表の整数値2点を直線で結び、途中の値を比例配分で求めています。中学の比例配分と同じ計算です。
A. 平方和Sを大きい値で割ると結果が小さくなり下限に、小さい値で割ると大きくなり上限になるからです。カイ二乗が非対称なため起きます。
まとめ:分散・等分散の検定はこれで完成
- F検定=2つの分散の比(大÷小)で等分散かを判定。F分布は1が中心の非対称な山
- 両側5%検定でも、F分布表は片側2.5%を読む
- ハートレーの検定=3群以上のバラつきを「最大÷最小」で一気に比較(n等しい)
- Welchの検定=等分散でない2群の平均比較。等価自由度は小数になり線形補間で読む
- カイ二乗検定=1つの分散を基準値と比較・区間推定。上側/下側の読み間違いに注意
「いくつ比べるか」「相手は基準値か群か」で手法が決まります。この地図が頭に入れば、QC検定の計量値の検定はぐっと得点しやすくなります。
📚 次に読むべき記事
検定・推定の全体像を体系的に学べるマップ。まず最初に押さえたい1本です。
F検定で「等分散」とわかった後に使う、平均の差の検定。F検定とセットで学ぶと実戦的です。
母分散の検定・推定でつまずきやすい「表のどちらを読むか」を深掘りした隣接記事です。