
の検定って何をしているのかわからない 残差を「純粋誤差){kind=link}
- 回帰直線を引いたけど、「本当に直線でいいの?」と不安になる
- Lack of Fit(適合性の欠如)の検定って何をしているのかわからない
- 残差を「純粋誤差」と「モデル不適合」に分解する意味がピンとこない
- 分散分析表の計算手順が複雑で、手が止まる
- Lack of Fitの検定が「何を見破る」ための手法なのか
- 残差を2つに分解する仕組みを「射撃の的」で直感的に理解
- 分散分析表の作り方を、具体的な数値例でSTEP by STEPで完全マスター
- 検定結果が有意だったときの「次のアクション」
回帰分析で直線を引いて、決定係数R²もそこそこ高い。「よし、このモデルでOKだ」と結論づけたくなりますよね。
でも、ちょっと待ってください。そもそも「直線」で当てはめたこと自体が間違っている可能性を考えたことはありますか?
たとえば、本当はデータが曲線的な関係を持っているのに、無理やり直線を引いてしまったら──R²がそれなりに高くても、予測はズレます。
この「直線モデルが本当に適切なのか?」を統計的に判定する方法が、今回解説する「Lack of Fit(適合性の欠如)の検定」です。
この検定を理解すると、回帰分析の結果を「なんとなくOK」ではなく、「統計的に根拠を持ってOK」と言えるようになります。計算例もつけて丁寧に解説していくので、ぜひ最後まで読んでみてください。
目次
Lack of Fit(適合性の欠如)とは何か?
💡 一言でいうと「直線モデルの限界」を暴く検定
回帰分析では、データに直線 ŷ = a + bx を当てはめますよね。でも、現実のデータが本当に直線的な関係とは限りません。
Lack of Fit検定は、「残差のうち、直線モデルでは説明しきれないズレがどのくらいあるか」を調べるための手法です。
ここで重要なのは、残差が生まれる原因は「2つある」ということです。
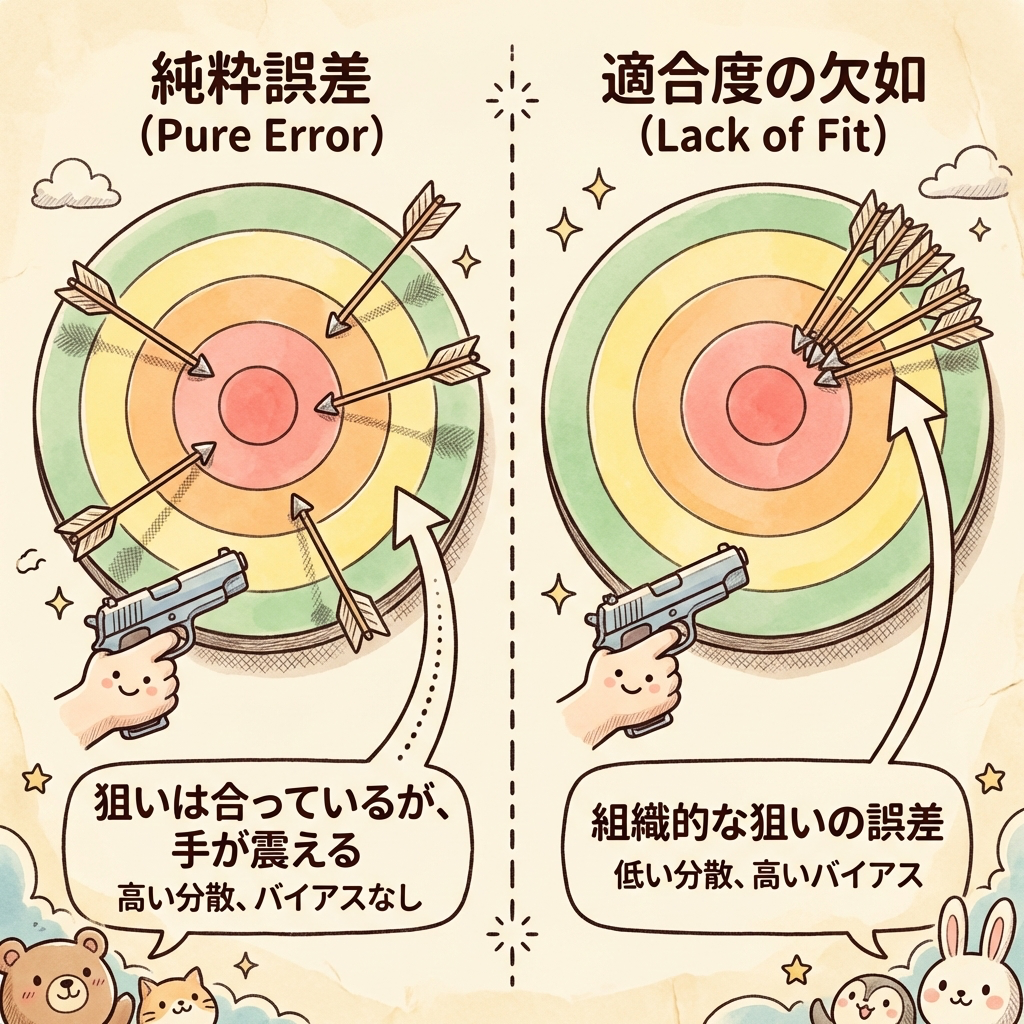
🎯 「射撃の的」でイメージする ── 残差の2つの原因
射撃で的の中心を狙うとき、弾が中心からズレる原因は2つあります。
原因① 腕のブレ
(Pure Error:純粋誤差)
照準は正しいのに、手が震えてバラつく。これは撃つ人のランダムなブレであり、どうしても避けられない。統計学でいう「純粋誤差」に相当します。
原因② 照準のズレ
(Lack of Fit:モデル不適合)
そもそも照準器の狙いが的の中心からズレている。腕が安定していても当たらない。これが「モデル自体が間違っている」ことによるズレです。
回帰分析に置き換えると、こうなります。
残差(Se)= 純粋誤差(SPE)+ モデル不適合(SLOF)
純粋誤差(Pure Error)は、同じ条件(同じx)で実験しても生じるランダムなバラつきです。これはモデルのせいではなく、測定誤差や個体差などの「避けられないノイズ」です。
Lack of Fit(モデル不適合)は、直線モデルでは捉えきれないズレです。もし本当の関係が曲線なのに直線を引いたら、このズレが大きくなります。
🔁 なぜ「繰り返しデータ」が必要なのか?
ここで重要な問題があります。もし各xに対してyが1つしかなければ、「純粋誤差」を見積もることができません。
なぜでしょうか? たとえば、x=2のときy=7という1つのデータしかなければ、「y=7のうち、どこまでがランダムな誤差で、どこからがモデルのズレか」を区別する手がかりがないからです。
しかし、同じx=2に対してy=5, 7, 6の3つのデータがあれば、この3つのバラつき(分散)が「純粋誤差」の大きさを教えてくれます。
Lack of Fit検定には「同じxで複数のyを測定したデータ(繰り返しデータ)」が不可欠です。繰り返しがなければ、この検定は実施できません。
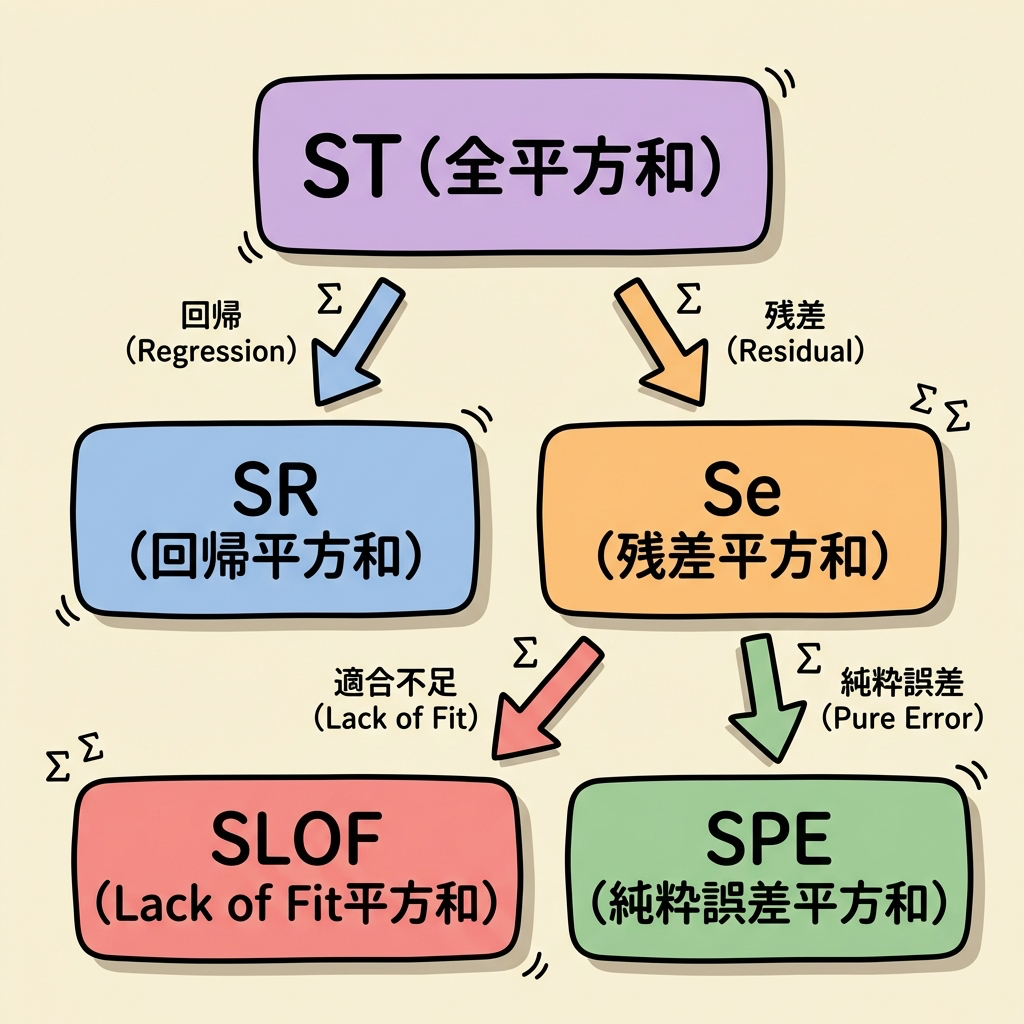
分散分析表の構造 ── 残差を「2つに分解」する
📊 通常の回帰分析の分散分析表(復習)
まず、通常の単回帰分析の分散分析表を復習しましょう。全体のバラつき(ST)を「回帰で説明できた部分(SR)」と「説明できなかった部分=残差(Se)」に分解します。
| 要因 | 平方和(SS) | 自由度(df) | 平均平方(MS) |
|---|---|---|---|
| 回帰(R) | SR | 1 | VR = SR / 1 |
| 残差(e) | Se | n − 2 | Ve = Se / (n−2) |
| 全体(T) | ST | n − 1 | ─ |
ここまでは、単回帰の分散分析で学んだ内容ですね。
単回帰の分散分析表|回帰・残差・全体の平方和を完全理解 →
🔍 Lack of Fit検定の分散分析表 ── 残差をさらに分解する
Lack of Fit検定では、この残差(Se)をさらに2つに分解します。
(照準のズレ)
(腕のブレ)
つまり、分散分析表は以下のように拡張されます。
| 要因 | 平方和(SS) | 自由度(df) | 平均平方(MS) | F値 |
|---|---|---|---|---|
| 回帰(R) | SR | 1 | VR | ─ |
| Lack of Fit | SLOF | k − 2 | VLOF | VLOF / VPE |
| Pure Error | SPE | n − k | VPE | ─ |
| 残差(e)合計 | Se | n − 2 | ─ | ─ |
| 全体(T) | ST | n − 1 | ─ | ─ |
ここで k は「xの水準数(何種類のxがあるか)」、n は「データの総数」です。
📏 自由度の配分を理解する
自由度の構造が少し複雑なので、整理しておきましょう。
| 要因 | 自由度 | 意味 |
|---|---|---|
| 全体(T) | n − 1 | データ全体の自由度 |
| 回帰(R) | 1 | 単回帰の場合、傾きbの1つ |
| Lack of Fit | k − 2 | xの水準数 − 回帰のパラメータ数(a, bの2つ) |
| Pure Error | n − k | 各水準内のバラつき(各群で ni − 1 の合計) |
検算してみましょう。回帰 + LOF + PE = 1 + (k−2) + (n−k) = n−1 = 全体。ちゃんと合いますね。
各平方和の求め方 ── 何を計算しているのか?
🟢 純粋誤差平方和(SPE)の計算
純粋誤差平方和は、「同じxの中で、yがどれだけバラついているか」を測ります。
具体的には、各水準(各xの値)ごとに、グループ内のバラつき(偏差平方和)を計算して、すべて足し合わせます。
ȳi:水準iにおけるyの平均 yij:水準iのj番目のデータ
やっていることはシンプルです。各グループの中で「平均からどれだけズレているか」を二乗して合計する。これは一元配置実験の「群内平方和」と同じ計算です。
🔴 Lack of Fit平方和(SLOF)の計算
Lack of Fit平方和は、引き算で求まります。
SLOF = Se − SPE
残差平方和から純粋誤差平方和を引くだけ
直接計算する公式もあります。
SLOF = Σi=1k ni(ȳi − ŷi)²
ȳi:水準iのyの実測平均 ŷi:回帰直線による水準iの予測値
この式の意味を考えてみましょう。「各水準の実測平均 ȳi」と「回帰直線の予測値 ŷi」のズレを二乗して合計しています。
もし直線モデルが完全に正しければ、各水準の平均は回帰直線上にほぼ乗るはずです。つまり ȳi ≈ ŷi となり、SLOFはゼロに近づきます。逆に、直線では捉えきれない曲線的なパターンがあれば、ȳiとŷiのズレが大きくなり、SLOFも大きくなります。
⚖️ F検定で「直線モデルは適切か?」を判定する
最後に、F検定で判定します。
この検定の考え方はこうです。
| 項目 | 内容 |
|---|---|
| 帰無仮説 H0 | 直線モデルは適切である(Lack of Fitはない) |
| 対立仮説 H1 | 直線モデルは適切でない(Lack of Fitがある) |
| 判定 | F0 ≥ F(k−2, n−k, α) なら H0 を棄却 → 直線モデルは不適切 |
直感的に理解しましょう。VLOF(モデル不適合によるバラつき)が VPE(純粋な誤差のバラつき)と比べて大きすぎるなら、「そのズレはランダムな誤差では説明できない=モデルが間違っている」と判断するわけです。
F0が棄却されない(有意でない)場合は、「直線モデルで十分」と判断します。ただし、これは「直線モデルが完璧」という意味ではなく、「現在のデータでは直線モデルの不適合を検出できなかった」という意味です。
【計算例】具体的な数値で分散分析表を完成させる
📋 例題のデータ
ある工場で、加熱温度(x)と製品の強度(y)の関係を調べるため、4つの温度水準でそれぞれ3回ずつ実験を行いました。
| 温度 x | y(1回目) | y(2回目) | y(3回目) | 水準平均 ȳi |
|---|---|---|---|---|
| 1 | 3 | 4 | 5 | 4.0 |
| 2 | 5 | 6 | 7 | 6.0 |
| 3 | 9 | 10 | 11 | 10.0 |
| 4 | 14 | 15 | 16 | 15.0 |
データの基本情報を整理しておきます。
| 記号 | 意味 | 値 |
|---|---|---|
| n | データ総数 | 12 |
| k | xの水準数 | 4 |
| x̄ | xの全体平均 | 2.5 |
| ȳ | yの全体平均 | 8.75 |
STEP 1:回帰直線を求める
まず、最小二乗法で回帰直線 ŷ = a + bx を求めます。
= 3×[(1−2.5)² + (2−2.5)² + (3−2.5)² + (4−2.5)²]
= 3×[2.25 + 0.25 + 0.25 + 2.25]
= 3 × 5 = 15
Sxy = Σ(xi − x̄)(yi − ȳ)
※ 12個すべてのデータで計算すると = 55.5
傾き b = Sxy / Sxx = 55.5 / 15 = 3.7
切片 a = ȳ − b × x̄ = 8.75 − 3.7 × 2.5 = −0.5
ŷ = −0.5 + 3.7x
各水準での予測値を計算します。
| x | 実測平均 ȳi | 予測値 ŷi | ズレ(ȳi − ŷi) |
|---|---|---|---|
| 1 | 4.0 | 3.2 | +0.8 |
| 2 | 6.0 | 6.9 | −0.9 |
| 3 | 10.0 | 10.6 | −0.6 |
| 4 | 15.0 | 14.3 | +0.7 |
実測平均と予測値にズレがありますが、これが「Lack of Fit」です。このズレが「誤差の範囲」なのか「モデルの問題」なのかを検定で判断します。
STEP 2:全体平方和 ST を求める
= (3−8.75)² + (4−8.75)² + (5−8.75)² + (5−8.75)² + (6−8.75)² + (7−8.75)²
+ (9−8.75)² + (10−8.75)² + (11−8.75)² + (14−8.75)² + (15−8.75)² + (16−8.75)²
= 33.0625 + 22.5625 + 14.0625 + 14.0625 + 7.5625 + 3.0625
+ 0.0625 + 1.5625 + 5.0625 + 27.5625 + 39.0625 + 52.5625
= 219.75
STEP 3:回帰平方和 SR と残差平方和 Se を求める
Se = ST − SR = 219.75 − 205.35 = 14.40
STEP 4:純粋誤差平方和 SPE を求める
各水準内で「平均からのズレ」を二乗して合計します。
(3−4)² + (4−4)² + (5−4)² = 1 + 0 + 1 = 2
x=2(ȳ₂ = 6.0):
(5−6)² + (6−6)² + (7−6)² = 1 + 0 + 1 = 2
x=3(ȳ₃ = 10.0):
(9−10)² + (10−10)² + (11−10)² = 1 + 0 + 1 = 2
x=4(ȳ₄ = 15.0):
(14−15)² + (15−15)² + (16−15)² = 1 + 0 + 1 = 2
SPE = 2 + 2 + 2 + 2 = 8.00
STEP 5:Lack of Fit平方和 SLOF を求める
引き算で求まります。
念のため、直接計算でも検算しておきましょう。
= 3×(4.0 − 3.2)² + 3×(6.0 − 6.9)² + 3×(10.0 − 10.6)² + 3×(15.0 − 14.3)²
= 3×0.64 + 3×0.81 + 3×0.36 + 3×0.49
= 1.92 + 2.43 + 1.08 + 1.47
= 6.90
上の直接計算では 6.90、引き算では 6.40 と差が出ています。これは傾き b = 3.7 の丸め誤差が原因です。厳密には b = 55.5/15 = 3.7000 ですが、中間計算の丸めの影響で直接計算の方にわずかな誤差が生じています。実務では「引き算(SLOF = Se − SPE)」を使うのが安全です。以下では引き算の 6.40 を採用します。
STEP 6:分散分析表を完成させてF検定
すべての計算結果を分散分析表にまとめます。
| 要因 | SS | df | MS | F0 |
|---|---|---|---|---|
| 回帰(R) | 205.35 | 1 | 205.35 | ─ |
| Lack of Fit | 6.40 | 2 | 3.20 | 3.20 |
| Pure Error | 8.00 | 8 | 1.00 | ─ |
| 残差(e)合計 | 14.40 | 10 | ─ | ─ |
| 全体(T) | 219.75 | 11 | ─ | ─ |
STEP 7:結果を判定する
F分布表より:F(2, 8, 0.05) = 4.46
F0 = 3.20 < 4.46 = F(2, 8, 0.05)
→ 帰無仮説を棄却できない
有意水準5%で、Lack of Fitは有意ではない。つまり、直線モデル ŷ = −0.5 + 3.7x は、このデータに対して十分適切であると判断できます。
射撃の例え話に戻ると、「照準のズレ(Lack of Fit)は、腕のブレ(純粋誤差)と比較して無視できるレベル」ということです。安心して直線モデルを使えます。

よくある疑問と注意点
❓ 「Lack of Fitが有意」だったらどうする?
もしF0が棄却域に入り、Lack of Fitが有意と判定された場合、「直線モデルではデータを適切に表現できていない」ということになります。
この場合の次のアクションは、主に以下の3つです。
二次項(x²)を追加する:ŷ = a + bx + cx² のように多項式回帰にする。最も一般的な対処法です。
変数変換を行う:xやyを対数変換(log x, log y)や平方根変換(√x)するなど、直線関係が成り立つスケールに変換する。
区分的に回帰する:xの範囲を分割して、それぞれに直線を当てはめる(区分線形回帰)。
❓ 繰り返し数が不揃いでも検定できる?
はい、各水準の繰り返し数 ni が異なっていても検定可能です。
純粋誤差の自由度は Σ(ni − 1) = n − k で変わりませんし、SLOFの直接計算式 Σni(ȳi − ŷi)² でも ni の違いが自動的に反映されます。
ただし、繰り返しが1回しかない水準がある場合、その水準はPure Errorに寄与しません(水準内の分散が計算できないため)。最低でも各水準2回以上の繰り返しがあることが望ましいです。
❓ R²が高いのにLack of Fitが有意になることはある?
あります。これは一見矛盾しているように見えますが、ちゃんと理由があります。
R²(決定係数)は「全体のバラつきのうち、回帰で説明できた割合」を示す指標です。データの範囲が広く、全体的な傾向が強ければR²は高くなります。
しかし、R²が高くても「直線ではなく曲線で当てはめた方がさらに良い」というケースは存在します。たとえば、R² = 0.95でも、残差にS字型のパターンが残っていれば、Lack of Fit検定は有意になり得ます。
R²は「どれだけ説明できたか」、Lack of Fitは「モデルの形が正しいか」── 見ている角度が異なるのです。
まとめ ── 平方和の分解と判定フローを一枚で整理
最後に、この記事で学んだ内容を総整理しましょう。
📋 平方和の分解まとめ
🔑 この記事のポイント
| 項目 | 内容 |
|---|---|
| Lack of Fitとは | 回帰モデルの「形」が正しいかを検定する手法 |
| 残差の分解 | Se = SLOF(モデル不適合)+ SPE(純粋誤差) |
| 必要なデータ | 同じxで複数のyがある「繰り返しデータ」が必須 |
| F検定の帰無仮説 | 「直線モデルは適切である」(棄却 → モデル不適合) |
| 有意だった場合 | 二次項の追加・変数変換・区分回帰などを検討 |
Lack of Fit検定は、回帰分析の結果を「使って良いかどうか」を判断する最後の関門です。この検定をクリアして初めて、「直線モデルで予測してOK」と胸を張って言えます。
ぜひ、自分のデータでも実際に手を動かして計算してみてください。分散分析表を1つ作り上げると、理解が一気に深まりますよ。
📚 次に読むべき記事
回帰分析シリーズの全体像を確認。今回の記事がどの位置にあるかがわかります。
Lack of Fitの前提となる「繰り返しデータ」の扱い方を復習できます。
通常の回帰分析の分散分析表の基礎を確認できます。
Lack of Fitだけでなく、等分散性・正規性・独立性もチェックすべき前提条件です。
R²とLack of Fitの違いを理解するために、決定係数の本質を確認しましょう。
単回帰の次は重回帰へ。説明変数が2つ以上になったときの分析方法を学びましょう。
この記事で頻出した「残差」と「誤差」の違いを正確に理解しておきましょう。
📚 回帰分析を「武器」にする3冊
数式アレルギーだった私でも読破できた、厳選の良書です。