
- A2やD4の値が「なぜその数字なのか」がわからない
- 係数表を丸暗記しているが、理屈が理解できていない
- 「3σ」と係数の関係がピンとこない
- 管理図が「本当にやりたいこと」は何か
- 範囲Rから標準偏差σを推定する仕組み(d2の役割)
- A2・D3・D4の導出過程をステップバイステップで
目次
結論:係数は「3σ計算を簡略化する」ための変換値
いきなり結論からお伝えします。A2・D3・D4の正体は、「本来は3σで計算すべきところを、R̄(範囲の平均)だけで計算できるようにした変換係数」です。
つまり、こういうことです。
本来やりたい計算:
UCL = X̿ + 3σ(平均 + 3×標準偏差)
問題:
でも、工程の「真のσ」はわからない…
解決策:
範囲R̄から推定する! → その変換をまとめたのがA2、D3、D4
この「なぜ」がわかると、係数表がただの数字の羅列ではなく、意味のある値として見えてきます。


{kind=link}
Step 1:管理図の「本当の目的」を理解する
まず、管理図が「本当にやりたいこと」を確認しましょう。
🎯 目的:「±3σ」の範囲に線を引きたい
管理図の管理限界線(UCL・LCL)は、「平均値 ± 3σ」の位置に引くのが基本です。なぜ3σかというと、正規分布に従うデータであれば、99.73%のデータがこの範囲に収まるからです。
もし工程が正常なら、データが3σを超える確率はわずか0.27%(約370回に1回)。
逆に言えば、3σを超えたら「何か異常が起きている可能性が高い」と判断できる。
つまり、管理図の本質は以下の計算です。
UCL = μ + 3σ
LCL = μ − 3σ
μ:母平均 / σ:母標準偏差
😰 問題:母標準偏差σは「わからない」
ここで問題が生じます。母標準偏差σ(真のバラつき)は、通常わかりません。
全数検査でもしない限り、母集団のσを正確に知ることは不可能です。私たちが手にしているのは、サンプルデータだけです。
そこで、サンプルデータからσを「推定」する必要があります。
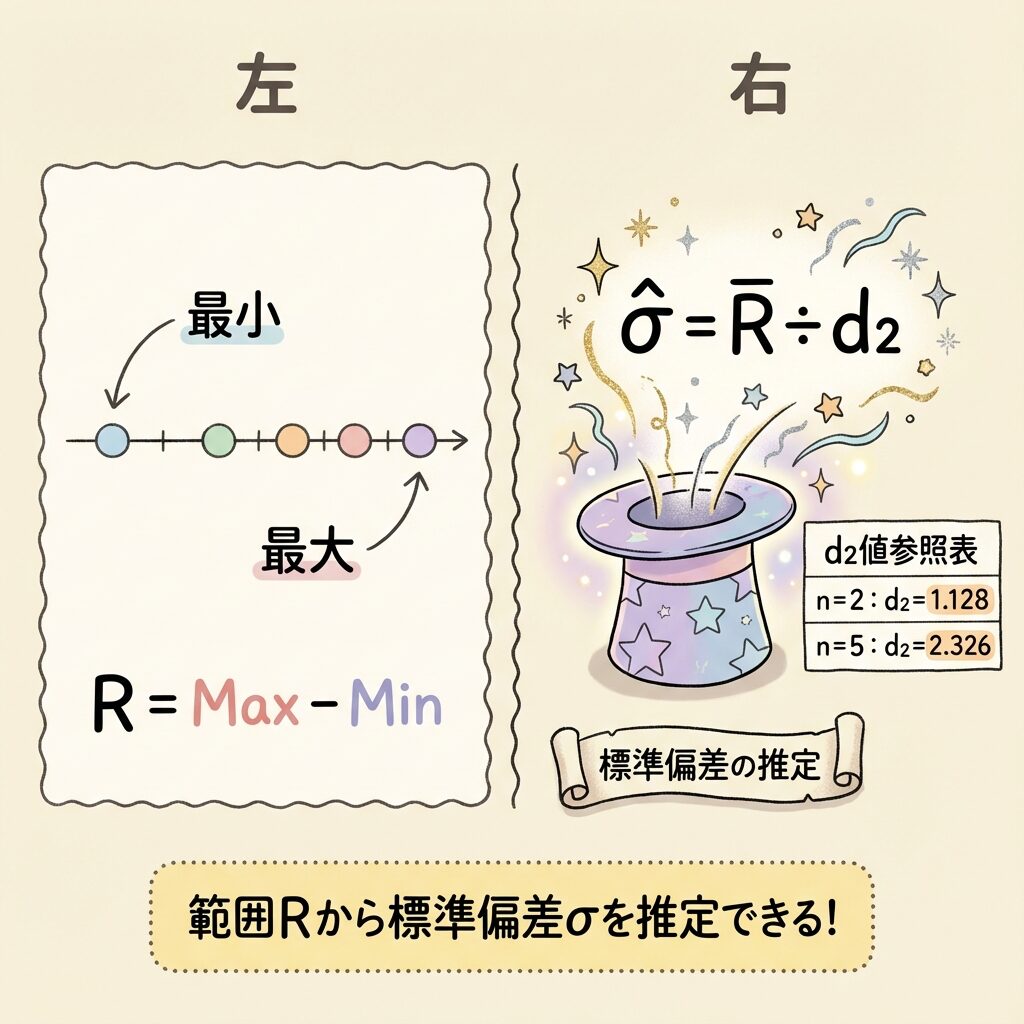
Step 2:範囲Rから標準偏差σを推定する(d2の登場)
σを推定する方法はいくつかありますが、管理図では歴史的に「範囲R」を使う方法が広く使われています。
📏 範囲R(Range)とは?
範囲Rは、サンプル内の最大値と最小値の差です。計算がとても簡単なので、現場で使いやすいという利点があります。
R = 最大値 − 最小値
例えば、5個のサンプル(10.2, 10.5, 10.1, 10.8, 10.3)があれば、R = 10.8 − 10.1 = 0.7 です。
🎩 魔法の係数「d2」:RからσへGの変換
統計学者たちは、「範囲Rと標準偏差σには一定の関係がある」ことを発見しました。
正規分布に従うデータからn個のサンプルを取ったとき、範囲Rの期待値(平均的な値)は、σのd2倍になります。
この式を変形すると、σをRから推定する式が得られます。
σ̂(シグマハット):σの推定値 / R̄:範囲の平均
📊 d2の値(サンプルサイズ別)
d2の値は、サンプルサイズnによって決まります。これも係数表に載っています。
| n | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| d2 | 1.128 | 1.693 | 2.059 | 2.326 | 2.534 |
サンプル数が多いほど、最大値と最小値の差(範囲R)は大きくなりやすいです。
だから、同じσに対してRが大きくなる分、d2も大きくなります。
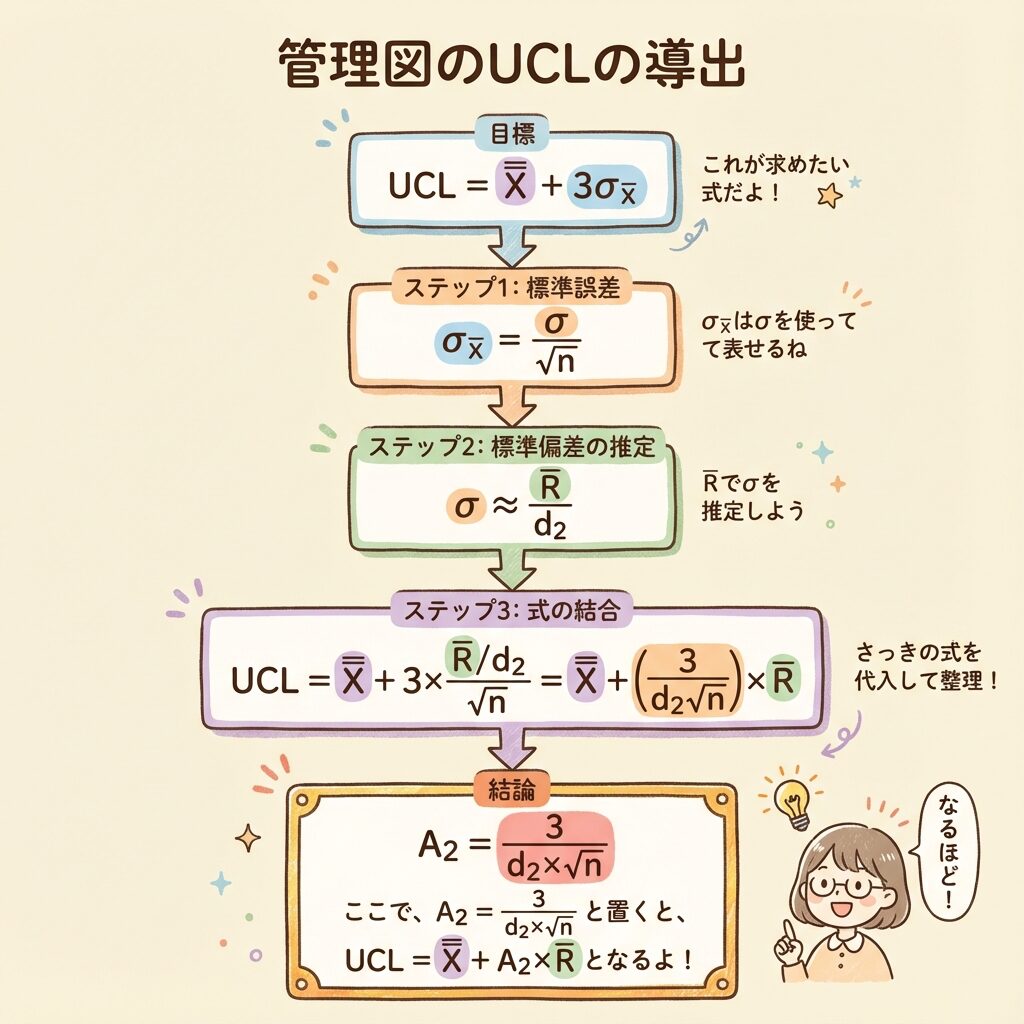

Step 3:A2の導出(X̄管理図の係数)
ここからが本題です。A2がどのように導出されるかを、ステップバイステップで見ていきましょう。
🎯 ゴール:X̄管理図のUCLを求めたい
X̄管理図では、「群ごとの平均値X̄」を打点します。この平均値のバラつきを監視したいので、管理限界線は「X̄のバラつき」に対して±3σの位置に引きます。
UCL = X̿ + 3σX̄
σX̄:平均値X̄の標準偏差(標準誤差)
📝 導出ステップ
Step 3-1:平均値の標準偏差(標準誤差)
統計学の基本定理より、n個のサンプルの平均値の標準偏差は、元のデータの標準偏差をσとすると:
Step 3-2:σをR̄/d2で置き換える
σがわからないので、σ ≈ R̄/d2 で推定します。
Step 3-3:UCLの式に代入
これをUCL = X̿ + 3σX̄に代入すると:
UCL = X̿ + 3 × R̄
d2 × √n
= X̿ + 3
d2 × √n × R̄
Step 3-4:A2の定義
ここで、赤字の部分をA2と定義します。
これで UCL = X̿ + A2 × R̄ という簡潔な式になる!
🧮 実際に計算してみる(n=5の場合)
n=5のとき、d2 = 2.326 です。これを代入すると:
A2 = 3 ÷ (2.326 × √5)
= 3 ÷ (2.326 × 2.236)
= 3 ÷ 5.201
= 0.577
係数表のA2 = 0.577と一致しました!係数は魔法の数字ではなく、ちゃんと計算で導出できるのです。
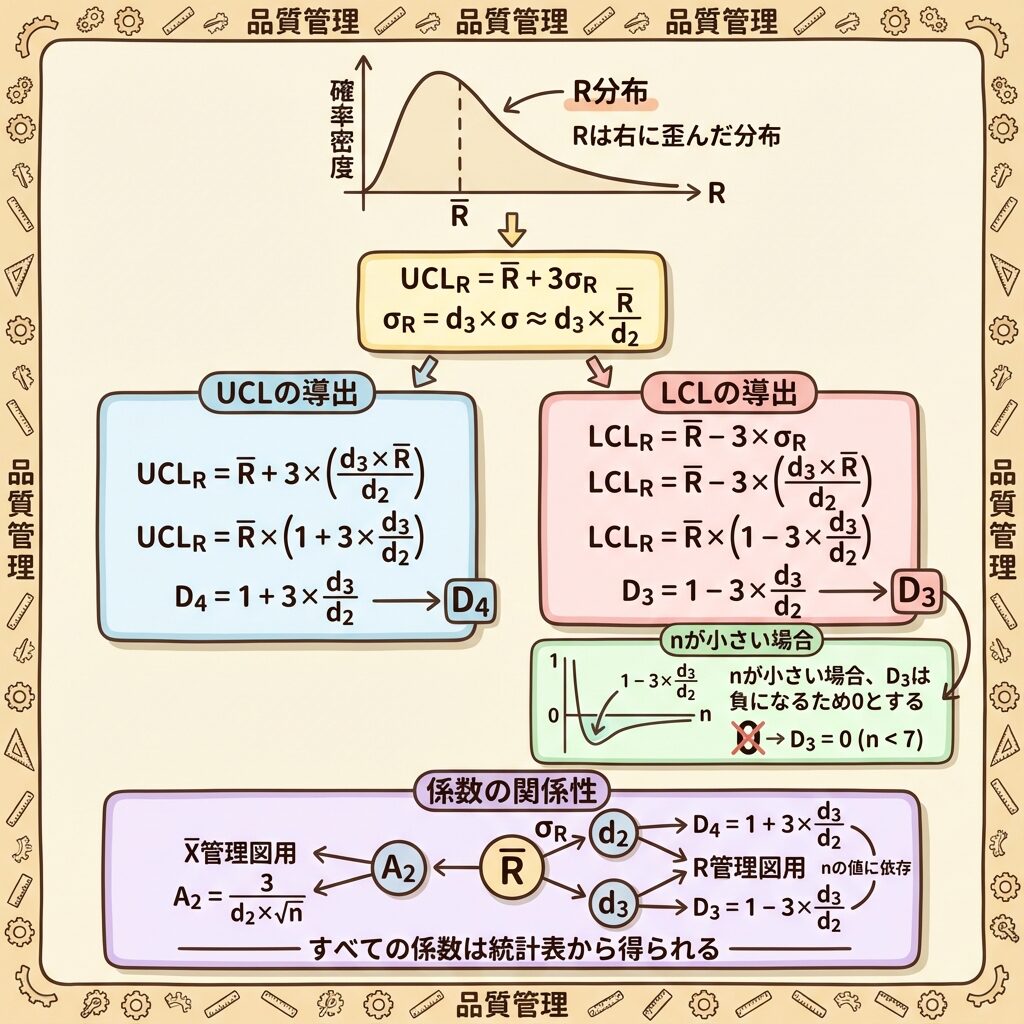
Step 4:D3・D4の導出(R管理図の係数)
R管理図の係数D3・D4も、同じ考え方で導出できます。ただし、範囲Rの分布は正規分布ではないため、少し複雑になります。
🎯 ゴール:R管理図のUCL・LCLを求めたい
UCL = R̄ + 3σR
LCL = R̄ − 3σR
σR:範囲Rの標準偏差
📝 導出ステップ
Step 4-1:範囲Rの標準偏差
範囲Rの標準偏差σRは、元のデータの標準偏差σと係数d3を使って表せます。
d3も係数表に載っている値で、nによって決まります。
Step 4-2:σをR̄/d2で置き換える
Step 4-3:UCL・LCLの式に代入
UCL = R̄ + 3 × (d3/d2) × R̄
= R̄ × (1 + 3 × d3/d2)
= D4 × R̄
LCL = R̄ − 3 × (d3/d2) × R̄
= R̄ × (1 − 3 × d3/d2)
= D3 × R̄
Step 4-4:D3・D4の定義
D4 = 1 + 3 × (d3/d2)
D3 = 1 − 3 × (d3/d2)
🤔 なぜD3は「-」になることがある?
D3 = 1 − 3×(d3/d2) の計算で、3×(d3/d2) が1を超えると、D3がマイナスになります。
しかし、範囲Rは「最大値−最小値」なので、必ず0以上です。マイナスのLCLは意味がありません。
n≦6のとき、計算上D3がマイナスになるため、LCLは設けない(または0とする)と定められています。
これは係数表で「-」と表記されています。
まとめ:係数の導出を図解で整理
- 管理図の本質は「±3σ」で管理限界を引くこと
- σがわからないので、範囲Rから推定する(σ̂ = R̄/d2)
- A2 = 3/(d2×√n):X̄のバラつきを3σで表すための係数
- D4 = 1 + 3×(d3/d2):R管理図の上限係数
- D3 = 1 − 3×(d3/d2):R管理図の下限係数(マイナスなら「-」)
係数は「魔法の数字」ではなく、「3σ計算をR̄で代用するための変換値」です。この原理を理解しておくと、公式の丸暗記から卒業でき、応用問題にも対応できるようになります。
📚 次に読むべき記事
A2・D3・D4以外の係数の意味を詳しく解説します
3σの統計的根拠と第一種過誤との関係を解説します
全管理図の公式を1記事にまとめたチートシートです