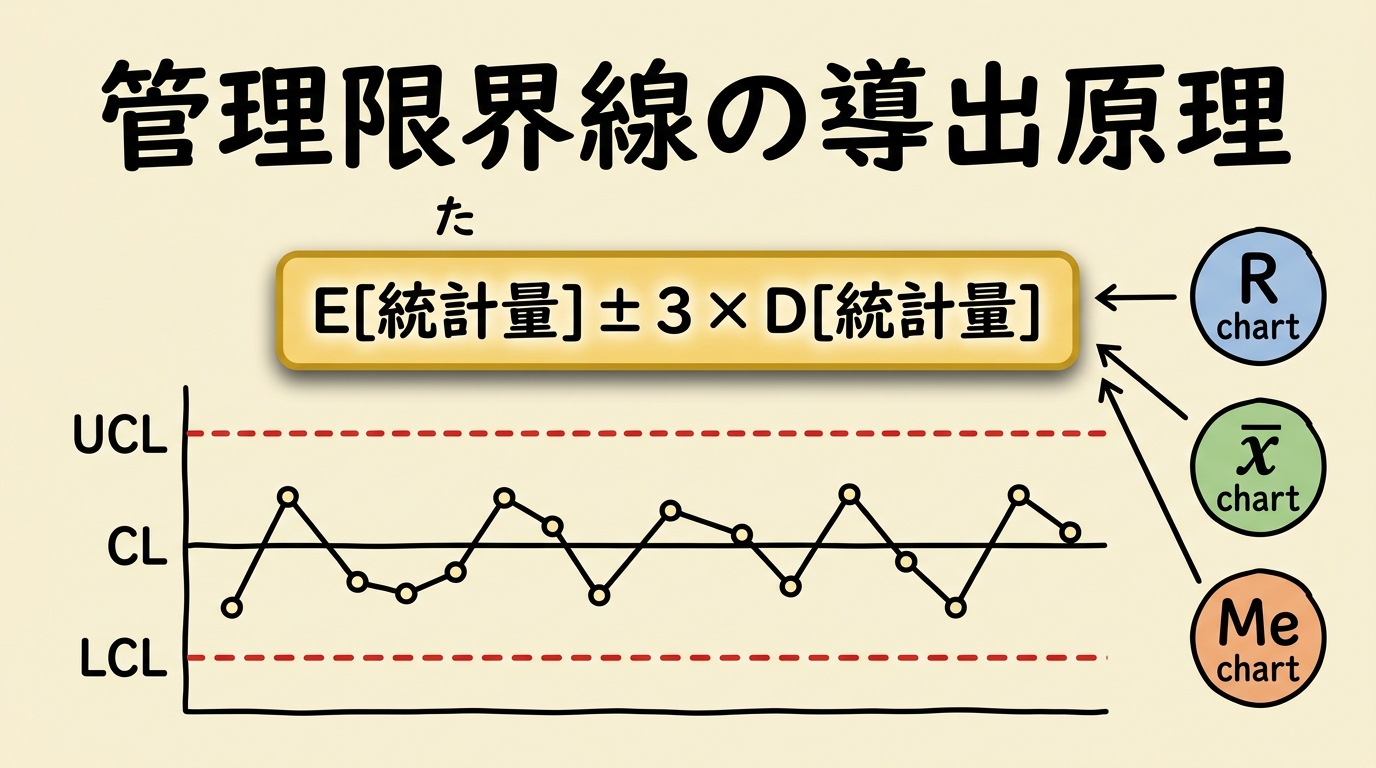
- 管理図のUCL・LCLの公式が管理図ごとに違いすぎて、覚えきれない…
- A₂やD₃、D₄などの係数が「なぜその値になるのか」がわからない
- QC検定の問題で「管理限界線の式を導け」と言われると手が止まる
- R管理図、X̄管理図、Me-R管理図…それぞれバラバラに暗記している
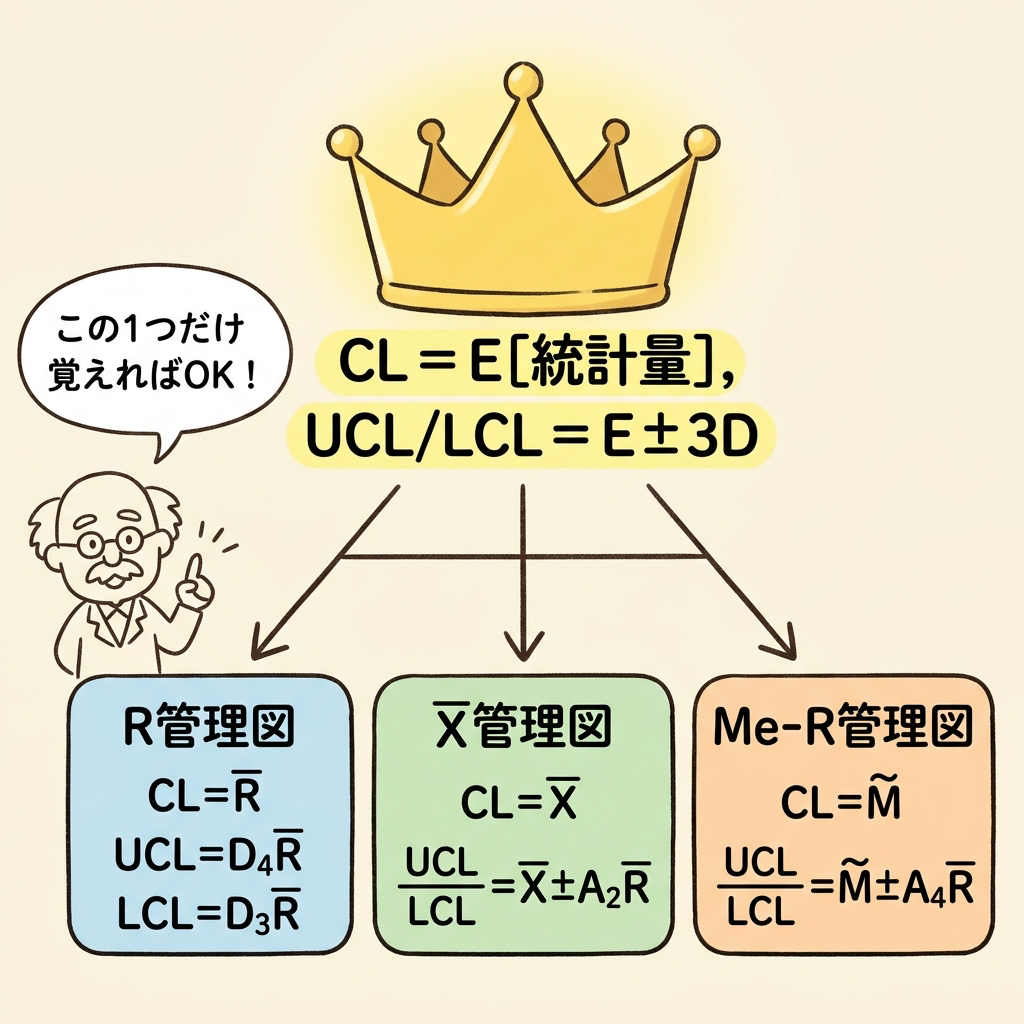
- すべての管理図に共通する「E ± 3D」というたった1つの統一公式
- d₂、d₃がどんな意味を持ち、なぜσの推定にR̄/d₂を使うのか
- R管理図・X̄管理図・Me-R管理図の管理限界線を、自力で導出する方法
- JIS係数表のA₂・D₃・D₄が「どこから来た数字なのか」の正体
すべての管理図の管理限界線は、「CL = E[統計量]」「UCL, LCL = E[統計量] ± 3 × D[統計量]」という1つのルールから導出できます。R管理図もX̄管理図もMe-R管理図も、「プロットする統計量の期待値と標準偏差は何か?」さえ押さえれば、自動的に管理限界線の公式が手に入ります。もう丸暗記は必要ありません。
管理図の勉強をしていると、R管理図にはD₃・D₄、X̄管理図にはA₂、Me-R管理図にはÃ₂…と、管理図ごとに異なる係数が次々と登場しますよね。
「こんなの全部覚えられない!」と思った方、安心してください。実は、これらの係数はすべて同じ1つの原理から生まれています。
その原理を理解すれば、どんな管理図の管理限界線でも自分で導出できるようになります。この記事では、その統一的な考え方を、比喩と図解を使って丁寧に解説していきます。
📖 【QC検定】管理図と工程能力指数の完全ロードマップ|学習順序と全体像 →
この記事は上記ロードマップの一部です。管理図の学習全体を俯瞰したい方はこちらからどうぞ。
目次
すべての管理図に共通する「たった1つのルール」
管理図の3本線をおさらい
まず、管理図の基本構造を確認しましょう。管理図には3本の水平線があります。
| 線の名前 | 略称 | 役割 |
|---|---|---|
| 中心線 | CL | プロットする統計量の「平均的な値」(期待値) |
| 上側管理限界線 | UCL | CLから「標準偏差の3倍」だけ上に離れた位置 |
| 下側管理限界線 | LCL | CLから「標準偏差の3倍」だけ下に離れた位置 |
たとえば、あなたが毎朝体温を測って記録しているとします。中心線(CL)は「普段の平熱(例:36.5℃)」、管理限界線は「ここを超えたら異常と判断するライン」に相当します。平熱から大きく外れたら「風邪かも?」と気づけますよね。管理図はまさにこれと同じ発想です。
📐 統一公式:「E ± 3D」
管理図にプロットする統計量を「T」と呼ぶことにしましょう。R管理図ならT = R(範囲)、X̄管理図ならT = X̄(平均値)です。このとき、どんな管理図でも以下の公式が成り立ちます。
CL = E[T]
UCL = E[T] + 3 × D[T]
LCL = E[T] − 3 × D[T]
E[T]:統計量Tの期待値(平均)、D[T]:統計量Tの標準偏差
「3倍」という数字は「3σ法」と呼ばれ、正規分布において中心から±3σの範囲にデータの99.73%が収まることに由来します。つまり、管理限界線を超える確率はわずか0.27%(約1000回に3回)です。この「めったに起きないことが起きた=工程に異常がある」というロジックが管理図の判定原理です。
この「E ± 3D」さえ覚えていれば、あとは「プロットする統計量の期待値E[T]と標準偏差D[T]は何か?」を当てはめるだけです。R管理図でもX̄管理図でもMe-R管理図でも、やることは同じです。
【準備知識】範囲Rの統計的性質とσの推定
範囲Rの「平均的な大きさ」と「バラつき」
管理図の導出に入る前に、もう1つだけ準備があります。それは範囲Rの統計的な性質です。
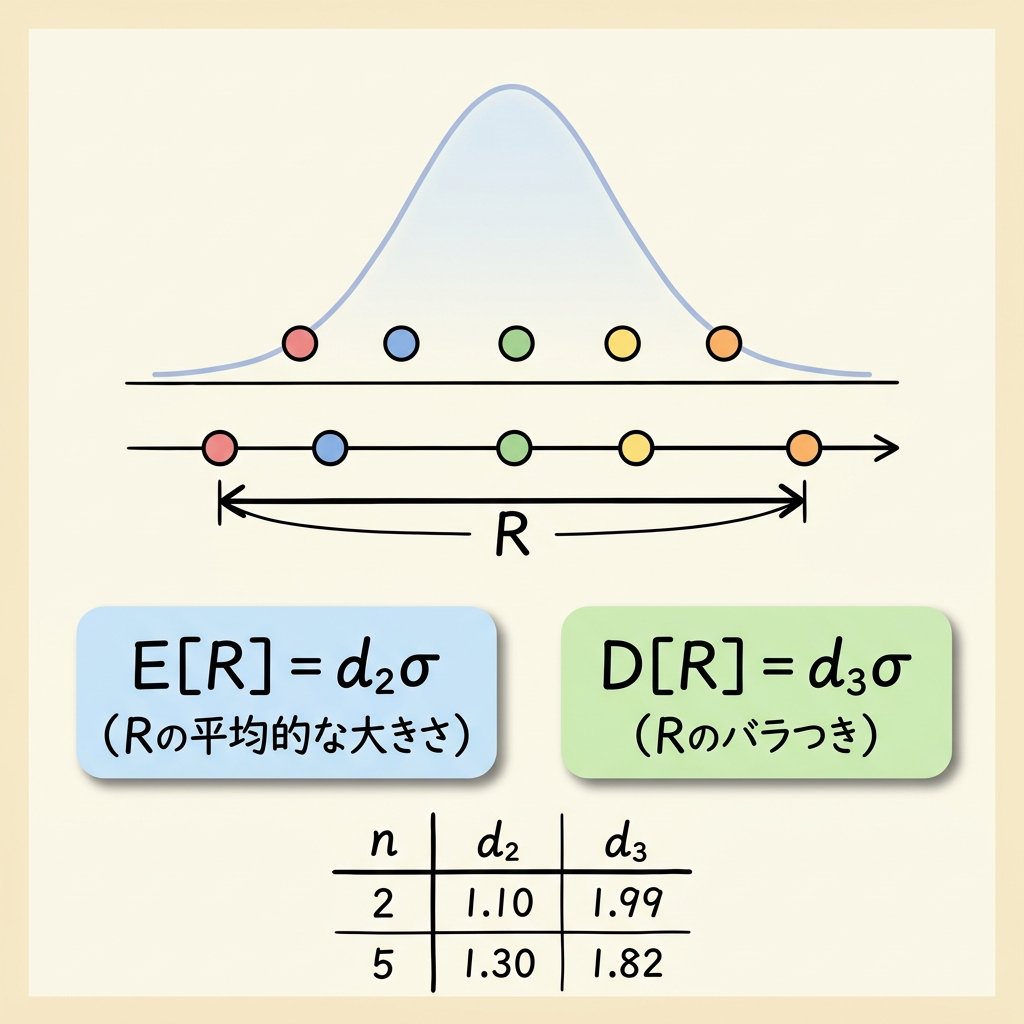
正規分布N(μ, σ²)から大きさnの標本を取り出したとき、範囲R(=最大値 − 最小値)の期待値と標準偏差は、次のように表されます。
E[R] = d₂σ (Rの期待値)
D[R] = d₃σ (Rの標準偏差)
d₂、d₃はいずれも群の大きさnによって決まる定数
直感的に言うと、d₂は「Rは平均してσの何倍くらいの大きさになるか」を示す係数、d₃は「Rのバラつき自体がσの何倍くらいか」を示す係数です。
たとえば、5人グループ(n=5)でテストを受けたとき、最高点と最低点の差(=範囲R)は、バラつきσに対して平均的にd₂倍の大きさになります。グループの人数(n)が変われば、当然この倍率も変わります。以下にd₂、d₃の代表的な値を示します。
| 群の大きさ n | d₂ | d₃ |
|---|---|---|
| 2 | 1.128 | 0.853 |
| 3 | 1.693 | 0.888 |
| 4 | 2.059 | 0.880 |
| 5 | 2.326 | 0.864 |
| 6 | 2.534 | 0.848 |
σの推定方法:なぜR̄/d₂を使うのか?
管理限界線を引くにはσ(母標準偏差)が必要です。しかし実務ではσの真の値はわかりません。そこで、手持ちのデータから推定する必要があります。
ここで活躍するのが、先ほどの E[R] = d₂σ という式です。この式の両辺をd₂で割ると、次のようになります。
σ̂ = R̄ / d₂
R̄:k個の群それぞれの範囲Rの平均値
考え方はシンプルです。E[R] = d₂σ は「範囲の平均はσのd₂倍になる」という意味ですから、逆にR̄をd₂で割ればσの推定値が得られるわけです。
同様に、μ(母平均)の推定値には、すべてのデータの総平均 X̿(X̄の平均)を使います。
① 管理限界線の統一公式は「E[T] ± 3 × D[T]」
② 範囲Rの性質は E[R]=d₂σ、D[R]=d₃σ
③ σの推定には σ̂ = R̄/d₂ を使う
この3つの武器が揃えば、いよいよ各管理図の管理限界線を導出できます。

R管理図の管理限界線を導出する
まずは一番わかりやすいR管理図(範囲の管理図)から始めましょう。R管理図にプロットする統計量は「各群の範囲R」です。
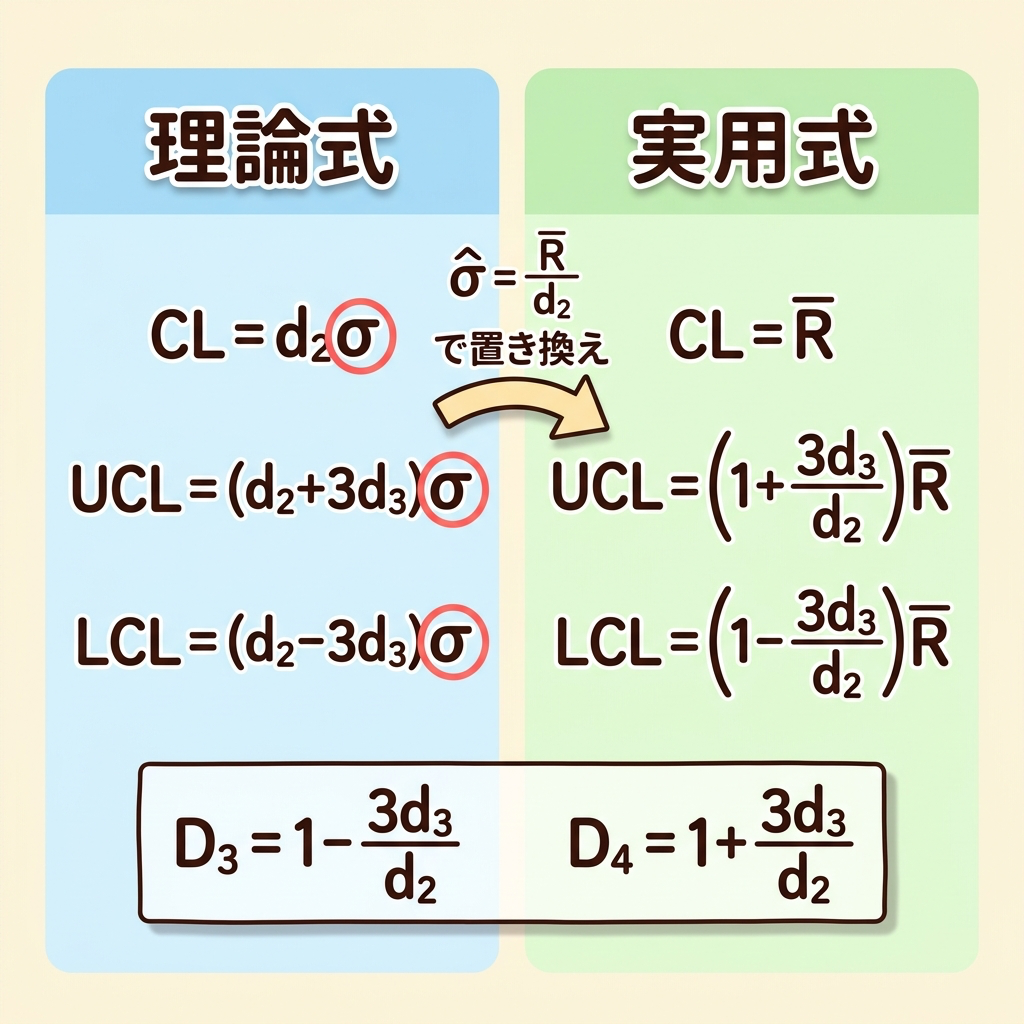
ステップ1:理論式を立てる(σが既知の場合)
統一公式「E ± 3D」に、Rの統計的性質(E[R]=d₂σ、D[R]=d₃σ)を代入します。
CL = E[R] = d₂σ
UCL = E[R] + 3×D[R] = d₂σ + 3d₃σ = (d₂ + 3d₃) σ
LCL = E[R] − 3×D[R] = d₂σ − 3d₃σ = (d₂ − 3d₃) σ
※ UCLとLCLをまとめて書くと:UCL, LCL = (d₂ ± 3d₃) σ
ここまでは「σがわかっている」という前提です。しかし、実際にはσの真の値はわかりません。そこで次のステップで、σを推定値に置き換えます。
ステップ2:実用式に変換する(σ̂ = R̄/d₂ で置き換え)
理論式のσを、推定値 σ̂ = R̄/d₂ で置き換えます。
CL = d₂ × (R̄/d₂) = R̄
UCL, LCL = (d₂ ± 3d₃) × (R̄/d₂) = (1 ± 3d₃/d₂) R̄
つまり、R管理図の中心線はR̄(範囲の平均)そのもので、管理限界線はR̄に(1 ± 3d₃/d₂)という係数をかけた値になります。
💡 JIS係数D₃・D₄の正体
JISの管理図係数表に載っているD₃とD₄は、実はここで導出した係数そのものです。
D₃ = 1 − 3d₃/d₂
D₄ = 1 + 3d₃/d₂
UCL = D₄R̄、LCL = D₃R̄ と書けます
たとえばn=5の場合、d₂=2.326、d₃=0.864なので、D₄ = 1 + 3×0.864/2.326 = 1 + 1.114 ≒ 2.114 となります。JIS係数表のD₄の値と一致していますね。
nが小さい(n≤6程度)とき、D₃ = 1 − 3d₃/d₂ がマイナスになることがあります。範囲Rは定義上マイナスにならないので、その場合はLCLは存在しない(下側管理限界線を引かない)と解釈します。JIS係数表でD₃が「−」や「0」になっているのはこのためです。
X̄管理図の管理限界線を導出する
次はX̄管理図(平均値の管理図)です。X̄管理図にプロットする統計量は「各群の平均値X̄」です。ここでも「E ± 3D」の統一公式に当てはめるだけです。
標本平均X̄の期待値と標準偏差
正規分布N(μ, σ²)から大きさnの標本を取り出したとき、その平均値X̄は次の性質を持ちます。
E[X̄] = μ
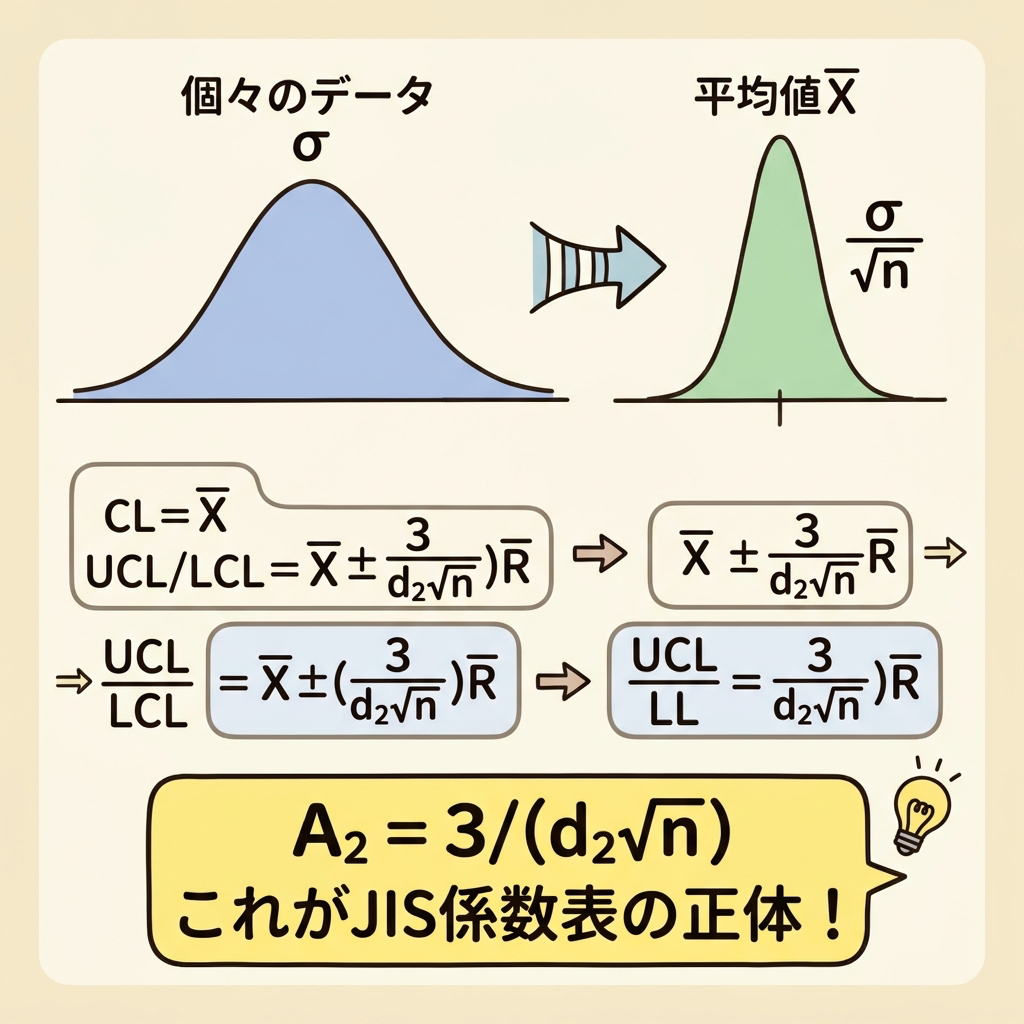
D[X̄] = σ / √n
D[X̄]は「標準誤差」とも呼ばれます
「平均値のバラつきは、元のデータのバラつきの1/√n倍になる」というのは統計学の最重要公式の1つです。データを多く集めれば(nが大きければ)、平均値はどんどん安定していきます。
イメージとしては、1人の体温は日によって結構変わりますが、「クラス30人の平均体温」は日によってそれほど変わらないですよね。人数(n)が増えるほど、平均は安定する。それを数式で表したのがD[X̄] = σ/√nです。
ステップ1:理論式を立てる
統一公式にX̄の性質を代入します。
CL = E[X̄] = μ
UCL, LCL = μ ± 3 × D[X̄] = μ ± 3 × (σ/√n) = μ ± (3/√n) σ
ステップ2:実用式に変換する
μの推定値としてX̿(各群のX̄の平均=総平均)を、σの推定値としてR̄/d₂を使って置き換えます。
CL = X̿(総平均)
UCL, LCL = X̿ ± (3/√n) × (R̄/d₂) = X̿ ± {3/(d₂√n)} R̄
💡 JIS係数A₂の正体
JISの管理図係数表に載っているA₂は、いま導出した係数そのものです。
A₂ = 3 / (d₂√n)
UCL = X̿ + A₂R̄、LCL = X̿ − A₂R̄ と書けます
A₂は「3」「d₂」「√n」という3つのパーツから構成されています。「3」は3σ法から、「d₂」はσの推定から、「√n」は標準誤差から来ています。すべてに理由があるのです。
① X̄の性質(E[X̄]=μ、D[X̄]=σ/√n)を「E±3D」に代入 → 理論式
② μ→X̿、σ→R̄/d₂ で置き換え → 実用式
R管理図とまったく同じ手順です。やっていることは「代入して整理」するだけ。

{kind=link}
Me-R管理図の管理限界線を導出する
最後にMe-R管理図(メディアン管理図)を導出します。Me-R管理図にプロットする統計量は「各群のメディアン(中央値)X̃」です。X̄(平均値)の代わりにメディアンを使うパターンですね。
メディアンX̃の期待値と標準偏差
正規分布N(μ, σ²)から大きさnの標本を取り出したとき、メディアンX̃の性質は次の通りです。
E[X̃] = μ
D[X̃] = m₃ × (1/√n) × σ
m₃はnによって決まる定数で、n ≥ 3のとき m₃ > 1
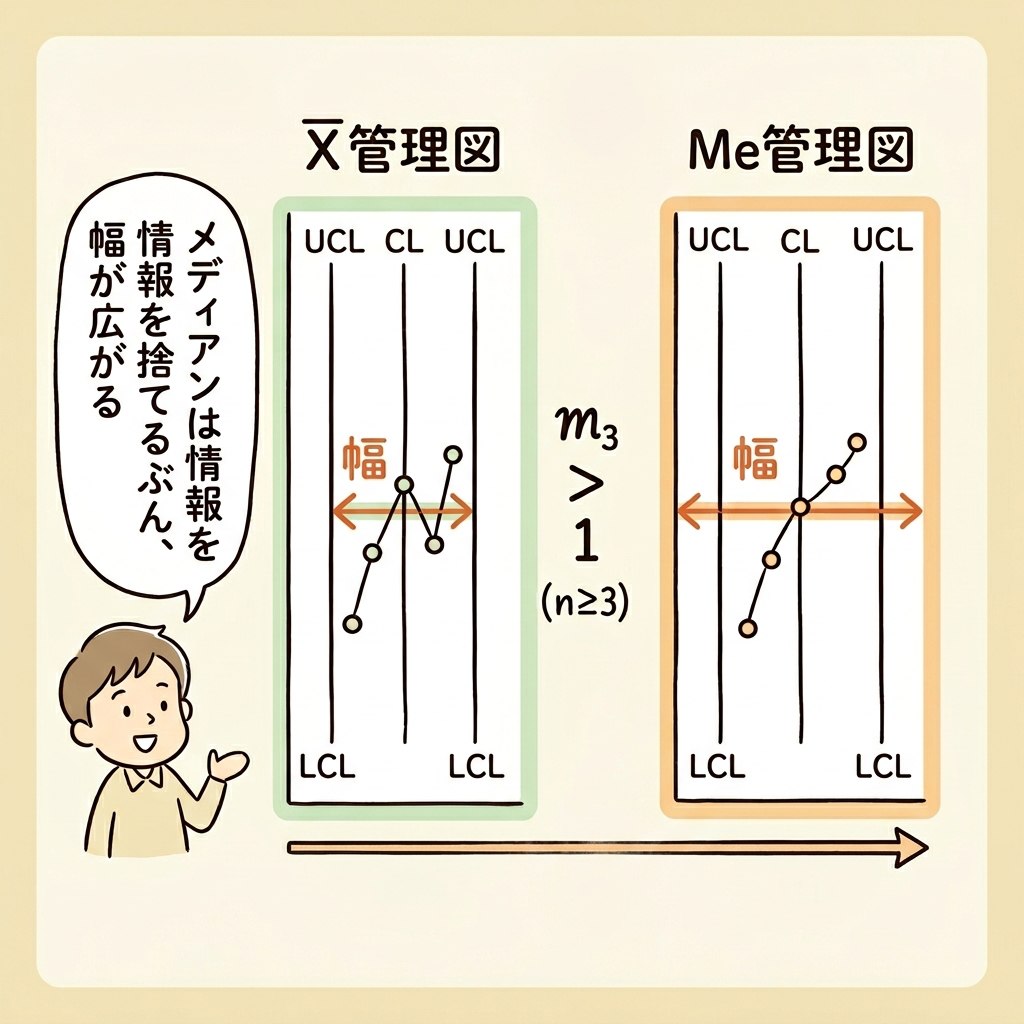
X̄管理図と比べてみましょう。X̄の標準偏差はσ/√nでした。メディアンの標準偏差はm₃ × σ/√n です。つまり、m₃倍だけ「バラつきが大きい」ということです。
なぜメディアンの方がバラつくのでしょうか?直感的に説明すると、平均値はすべてのデータの情報を使って計算しますが、メディアンは「真ん中の1つ(または2つ)」しか見ません。情報を捨てている分、推定精度が下がり、バラつきが大きくなるのです。
Me管理図の管理限界線
同じ「E±3D」の手順で、理論式を立てて実用式に変換します。
CL = E[X̃] = μ
UCL, LCL = μ ± 3 × m₃ × (σ/√n) = μ ± (3m₃/√n) σ
実用式への変換も同じで、μ→X̿(またはメディアンの平均)、σ→R̄/d₂ で置き換えればOKです。管理限界線の係数は 3m₃/(d₂√n) となり、JISではこれをÃ₂と呼びます。
🔑 X̄管理図 vs Me管理図:管理限界の幅を比較する
ここで大事な疑問が生まれます。「X̄管理図とMe管理図、どちらの管理限界の幅が広いのか?」です。
管理限界の幅(UCL − LCL)を比較してみましょう。σの推定に同じR̄/d₂を使う場合、幅を決めるのは「D[T]」の大きさだけです。
| 管理図 | 統計量Tの標準偏差 D[T] | 管理限界の幅(UCL−LCL) |
|---|---|---|
| X̄管理図 | σ / √n | 6σ̂ / √n |
| Me管理図 | m₃σ / √n | 6m₃σ̂ / √n |
n ≥ 3 のとき m₃ > 1 なので、Me管理図の方が幅が広くなります。つまり、
X̄管理図の幅 < Me管理図の幅
これはつまり、Me管理図はX̄管理図よりも「異常を見逃しやすい」ということを意味します。管理限界の幅が広い=データが限界を超えにくい=異常の検出力が低い、ということですね。
ではなぜMe管理図を使うことがあるのでしょうか?それは「メディアンは平均よりも計算が簡単」だからです。現場でデータを1つ1つ足し算して割り算する必要がなく、真ん中の値を丸で囲むだけで済みます。検出力と引き換えに、手軽さを取るわけです。
n = 2 の場合、データが2つしかないので中央値=平均値となり、m₃ = 1 です。このとき、X̄管理図とMe管理図の幅は等しくなります。m₃ > 1 が成り立つのは n ≥ 3 の場合のみです。
全管理図の導出を一覧表で整理
ここまでの内容を1つの表にまとめます。すべての管理図が「E ± 3D」の1公式から導出されていることを確認してください。
| 管理図 | 統計量T | E[T] | D[T] | 実用式 | JIS係数 | |
|---|---|---|---|---|---|---|
| CL | UCL, LCL | |||||
| R管理図 | R(範囲) | d₂σ | d₃σ | R̄ | (1±3d₃/d₂)R̄ | D₃, D₄ |
| X̄管理図 | X̄(平均値) | μ | σ/√n | X̿ | X̿±{3/(d₂√n)}R̄ | A₂ |
| Me管理図 | X̃(メディアン) | μ | m₃σ/√n | X̿ (or X̃̄) | X̿±{3m₃/(d₂√n)}R̄ | Ã₂ |
どの行を見ても、「実用式」は同じ手順で得られています。
① E[T]とD[T]を「E±3D」に代入して理論式を作る
② μ→X̿、σ→R̄/d₂ で置き換えて実用式に変換する
この2ステップを機械的に繰り返すだけです。管理図ごとに異なるのは「E[T]とD[T]が何か」だけ。
まとめ:丸暗記から「導出できる」へ
この記事で解説した内容をまとめます。
すべての管理図の管理限界線は「CL = E[T]」「UCL, LCL = E[T] ± 3D[T]」という1つの統一公式で導出できる
範囲Rの性質(E[R]=d₂σ、D[R]=d₃σ)と、σの推定式(σ̂=R̄/d₂)が管理図の土台
JIS係数のA₂、D₃、D₄はすべてこの導出過程から生まれた数字で、それぞれ明確な意味がある
Me管理図は m₃ > 1 のため、X̄管理図よりも管理限界の幅が広い(=検出力が低い)
管理図の公式は、丸暗記しようとすると種類が多くて大変です。でも「E±3D」という1つの原理さえ理解すれば、どんな管理図でも自力で公式を導けるようになります。QC検定の試験本番で公式を忘れても、この導出手順を知っていれば怖くありません。
❓ よくある質問(FAQ)
📚 次に読むべき記事
本記事で学んだ導出原理を、具体的な数値データで実践してみましょう。係数表を使った計算手順を例題で解説しています。
A₂やD₃・D₄の「値」がどのように計算されるのか、もう少し深掘りしたい方はこちらへ。
試験で出題される管理図の計算問題パターンを網羅的に整理。実戦練習に最適です。
📖 【QC検定】管理図と工程能力指数の完全ロードマップ|学習順序と全体像 →
この記事は上記ロードマップの一部です。管理図の学習全体を俯瞰したい方はこちらからどうぞ。