{kind=link}
- 「帰無仮説」「P値」「有意水準」…言葉が多すぎて頭が真っ白になる
- そもそも「検定」が何のためにあるのか、イメージできない
- QC検定や統計検定の勉強で、最初の関門でつまずいている
- 「第1種の過誤」「第2種の過誤」がどっちがどっちかわからない
- 仮説検定が「何をするための道具なのか」が一言でわかる
- 帰無仮説・対立仮説・P値・有意水準を「味噌汁」と「裁判」で理解できる
- 2種類の判定ミス(過誤)の覚え方がわかる
- 「点推定」と「区間推定」の違いがスッキリ整理できる
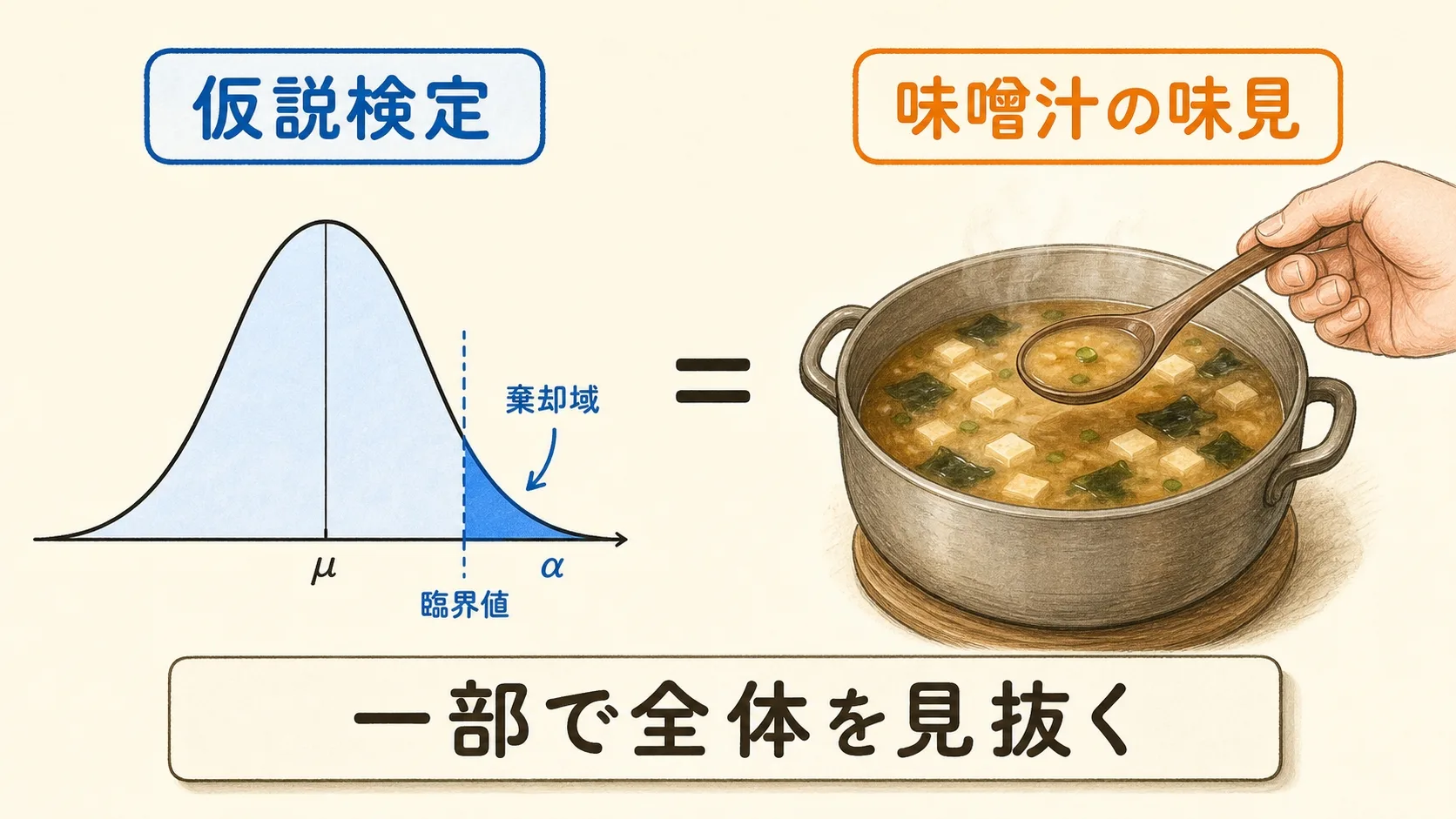
仮説検定とは、集めたデータの差が「本当の差」なのか「たまたまの偶然」なのかを、確率で判定する手続きです。
やることは1つだけ。まず「差はない(偶然だ)」という仮説をいったん立てます。そして、その仮説では説明できないほど珍しいデータが出たときに、初めて「差はある」と結論します。
むずかしそうに見えますが、考え方は料理の味見とまったく同じです。これから順番に解説していきます。
目次
そもそも仮説検定とは?「味噌汁の味見」で理解する
仮説検定という言葉だけ聞くと、すごく難しそうに感じますよね。でも、わからなくて当然です。学校でも、ここを直感的に教えてくれることはほとんどありません。
実は、あなたは毎日「仮説検定」をしています。それが料理の味見です。
鍋いっぱいの味噌汁の味を確かめるとき、あなたは鍋ぜんぶを飲み干しますか?
飲みませんよね。スプーン1杯だけすくって味見し、「この鍋全体は、ちょっと味が濃いな」と判断するはずです。
これこそが仮説検定の正体です。一部(スプーン1杯)を調べて、全体(鍋ぜんぶ)を推測しているのです。
なぜ「全部」ではなく「一部」で判断するのか
製造業の現場を考えてみましょう。工場で1日に10万個のネジを作るとき、全部の長さを測って検査するのは現実的ではありません。時間もコストもかかりすぎますし、製品を壊さないと測れない検査(破壊検査)なら、全部測ったら売る商品がなくなってしまいます。
そこで、一部(サンプル)だけを取り出して調べ、全体(母集団)がどうなっているかを判断する。これが統計学の基本姿勢であり、仮説検定の出発点です。
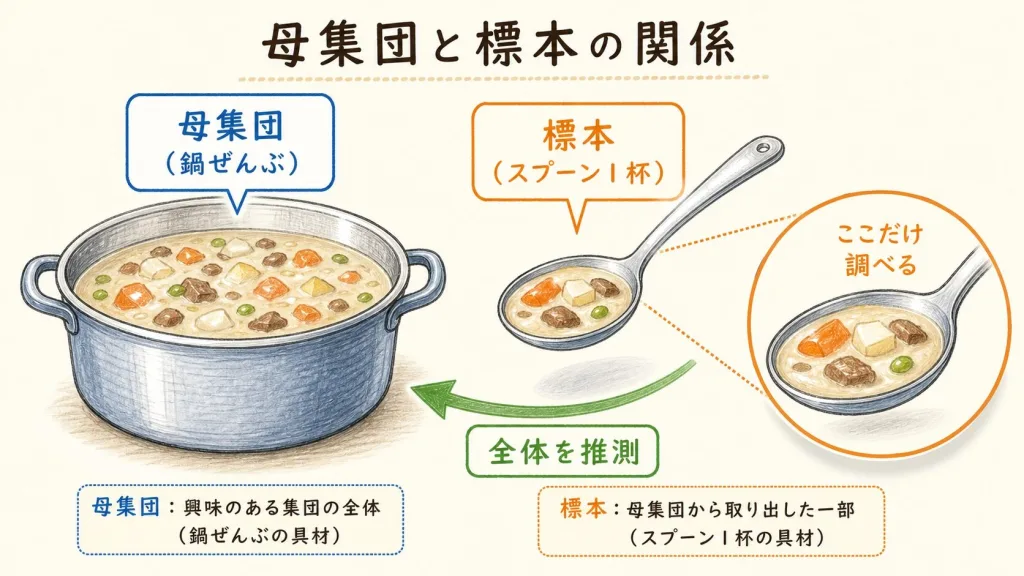
・母集団:本当に知りたい全体(鍋ぜんぶ/ネジ10万個)
・標本(サンプル):実際に調べる一部(スプーン1杯/抜き取った100個)
この2つだけ、まず頭に入れておけば大丈夫です。
仮説検定の主役「帰無仮説」と「対立仮説」
仮説検定では、必ず2つの仮説を立てます。名前が難しいですが、中身は単純です。
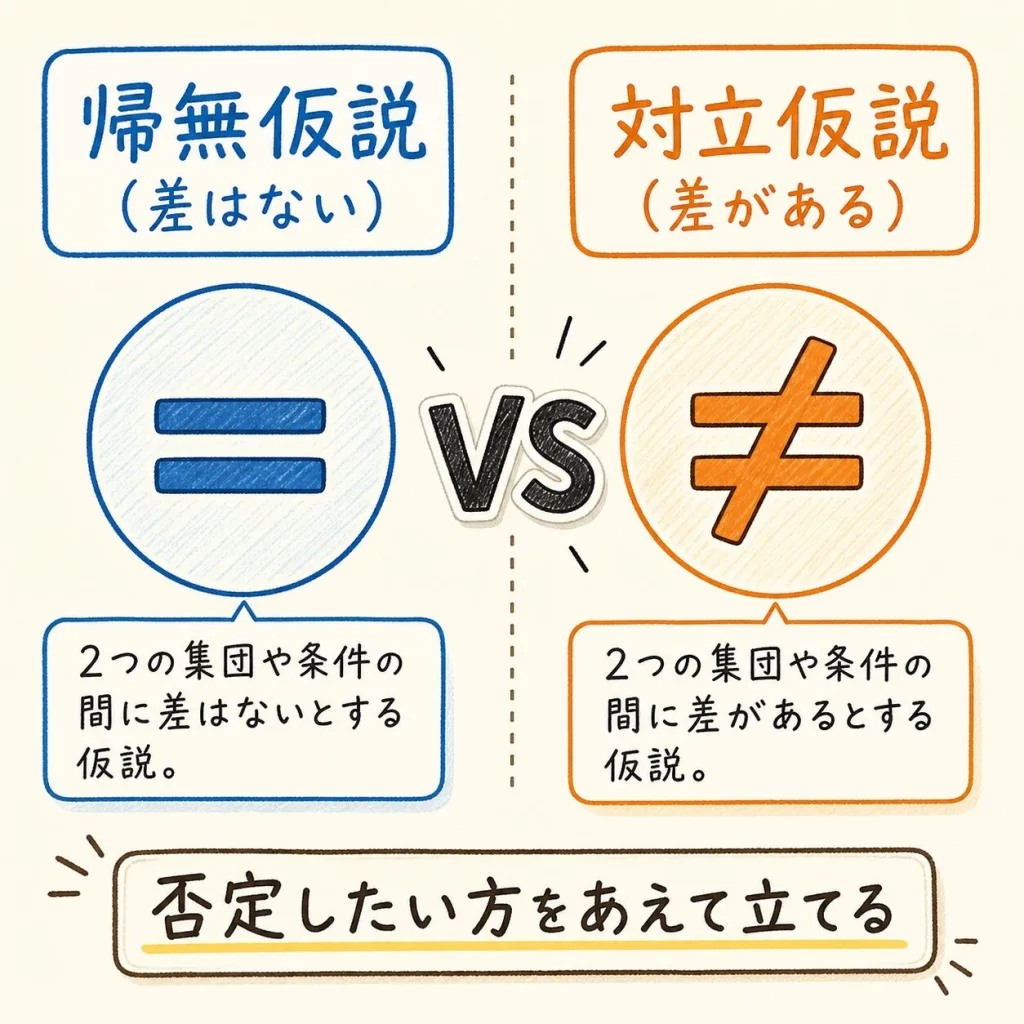
帰無仮説(H₀)
「差はない」「変わらない」という仮説。本当は否定したい主張。
- 例:新薬は効かない
- 例:機械Aと機械Bに差はない
対立仮説(H₁)
「差がある」という仮説。本当は主張したいこと。
- 例:新薬は効く
- 例:機械Aと機械Bに差がある
なぜ「否定したい方(帰無仮説)」をわざわざ立てるのか?
ここが初心者がいちばん「なぜ?」と感じるポイントです。普通なら「新薬は効く!」を直接証明したいですよね。でも、統計学はあえて逆(効かない)を立てて、それを崩しにいくのです。
理由は「ない」を証明するのは簡単でも、「ある」を直接証明するのは難しいからです。たとえば「この箱にリンゴが1つもない」は中を全部見れば証明できますが、「世界のどこかに金塊がある」を直接証明するのは大変です。
「差はない(帰無仮説)」と仮定したうえで、「もし差がないなら、こんな珍しいデータは出ないはずだ」という矛盾を突きつける。
矛盾が起きたら「やっぱり差はないという仮定がおかしかった」=「差がある」と結論する。
数学の「背理法」とまったく同じロジックです。
判定の流れを「裁判」で理解する|帰無仮説の棄却とは
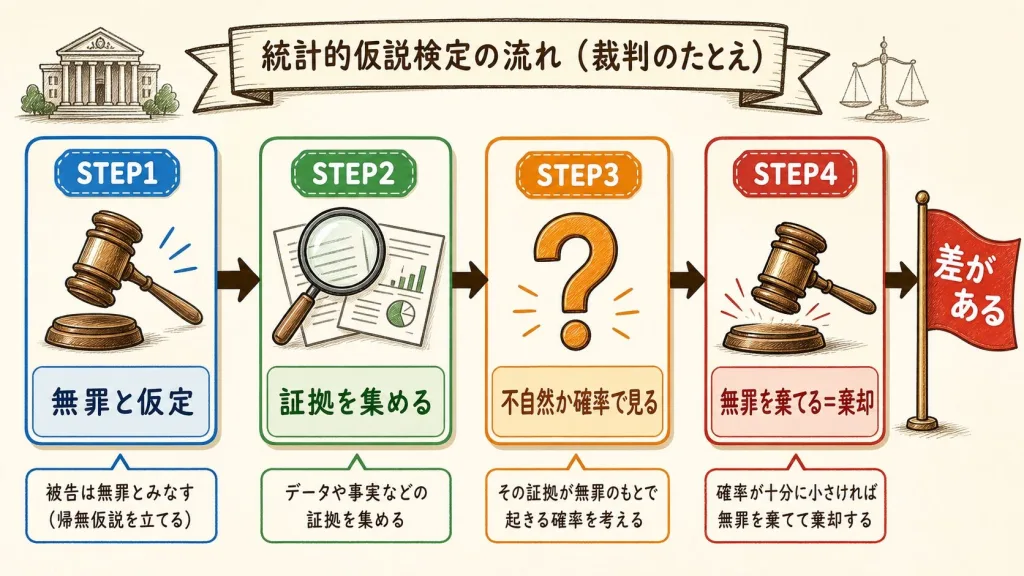
仮説検定の判定の流れは、刑事裁判にそっくりです。日本の裁判は「推定無罪」、つまり「証拠が出るまでは無罪(シロ)と扱う」のが大原則ですよね。検定もまったく同じ姿勢で進みます。
まず「無罪」と仮定する(帰無仮説を立てる)
裁判では被告を「無罪」と仮定。検定では「差はない」と仮定する。
証拠(データ)を集める
裁判では物証や証言。検定では実験・測定で得たデータを集める。
「無罪なら、こんな証拠が出るのは不自然か?」を確率で考える
もし無罪(差がない)なのに、あまりにも不自然な証拠が出たら…?
不自然すぎたら「無罪を捨てる」=帰無仮説を棄却
「無罪とは考えられない=有罪」。検定では「差はないとは考えられない=差がある」と結論する。
証拠が足りなければ「無罪のまま」=棄却できない
「クロとは言い切れない」状態。検定では「差があるとは言えない」となる。
「棄却」と「採択」の意味
| 用語 | 意味 | 裁判でいうと |
|---|---|---|
| 棄却 | 帰無仮説を捨てる=「差がある」と結論 | 有罪判決 |
| 棄却できない | 帰無仮説を捨てられない=「差があるとは言えない」 | 無罪(証拠不十分) |
裁判で「無罪」になっても、それは「本当に何もしていない」という証明ではなく「クロと断定する証拠が足りなかった」だけです。
検定も同じで、「棄却できない」=「本当に差がゼロ」という証明ではありません。「差があるとは言い切れなかった」だけ。だから検定では「採択する」ではなく「棄却できない」と慎重に表現します。
「珍しさ」をどう測る?P値と有意水準
さて、STEP 3で「無罪なら、こんなデータが出るのは不自然か?」を確率で考えると言いました。この「不自然さ(珍しさ)」を数値で表したものがP値です。
P値 = 「帰無仮説が正しいと仮定したとき、いま手元にあるデータ(以上に極端なもの)が出る確率」
やることは単純です。P値が小さいほど「偶然では説明できない=珍しい」ということ。珍しすぎたら「そもそも仮定(差がない)がおかしかった」と判断します。
どこまで珍しければ「クロ」とするか=有意水準
では、P値が何%以下なら「珍しすぎる=棄却」とするのか。その合格ライン(判定基準)が有意水準(α)です。
有意水準は5%(0.05)を使うのが一般的です。これは「20回に1回しか起きないような珍しいことが起きたなら、それは偶然ではなく差があったと判断する」という意味です。
・P値 < 有意水準(0.05) → 珍しすぎる → 帰無仮説を棄却(差がある)
・P値 ≧ 有意水準(0.05) → ありえる範囲 → 帰無仮説を棄却できない(差があるとは言えない)
| 用語 | ひとことで言うと |
|---|---|
| P値 | 実際に出た「珍しさ」の数値(テストの点数) |
| 有意水準(α) | 事前に決めた合格ライン(普通は5%) |
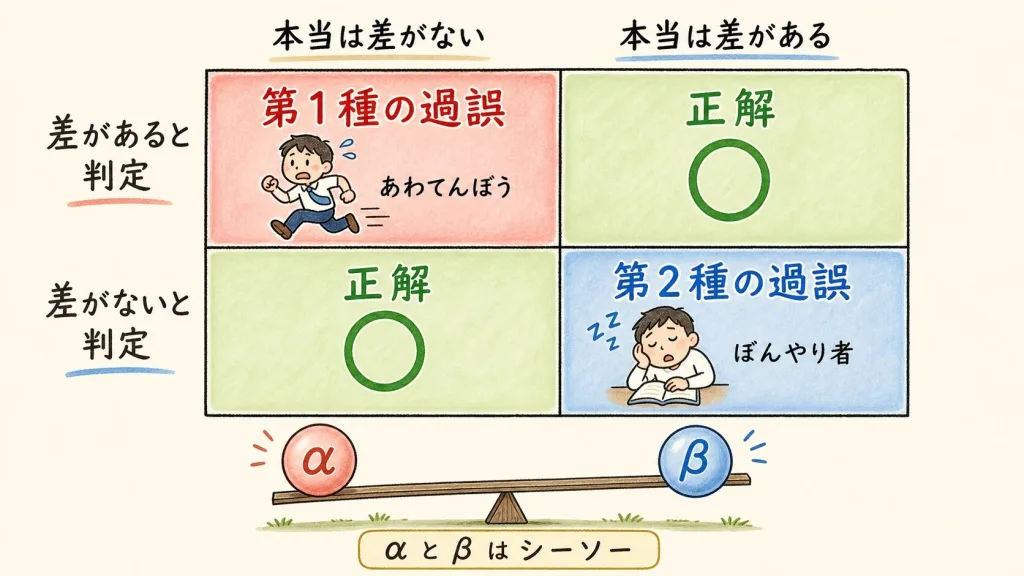
2つの判定ミス|第1種の過誤と第2種の過誤
検定はサンプル(一部)で全体を判断するので、必ず間違える可能性があります。その間違いには2種類あり、これがQC検定でも頻出の「第1種の過誤」と「第2種の過誤」です。
名前で覚えようとすると混乱します。「あわてんぼう」と「ぼんやり者」のキャラで覚えるのが一番ラクです。
第1種の過誤(あわてんぼう)
本当は差がないのに「差がある!」と早とちりするミス
- 確率は α(有意水準と同じ)
- 裁判でいうと「無実の人を有罪にする」(冤罪)
- 効かない薬を「効く」と判定
第2種の過誤(ぼんやり者)
本当は差があるのに「差がない」と見逃すミス
- 確率は β(ベータ)
- 裁判でいうと「真犯人を無罪にする」(見逃し)
- 効く薬を「効かない」と判定
4パターンを表で完全整理
| 本当は「差がない」 | 本当は「差がある」 | |
|---|---|---|
| 「差がある」と判定 | ❌ 第1種の過誤(α) あわてんぼう |
⭕ 正解 (検出力 1−β) |
| 「差がない」と判定 | ⭕ 正解 | ❌ 第2種の過誤(β) ぼんやり者 |
「冤罪を絶対に出すまい」と判定を慎重にすると(αを小さくすると)、今度は真犯人を見逃しやすくなります(βが大きくなる)。
この2つはシーソーの関係(トレードオフ)。だからこそ「どちらのミスが致命的か」を考えて有意水準を決めます。たとえば人命に関わる薬の検査なら、見逃し(第2種)を絶対に避けたい、といった具合です。
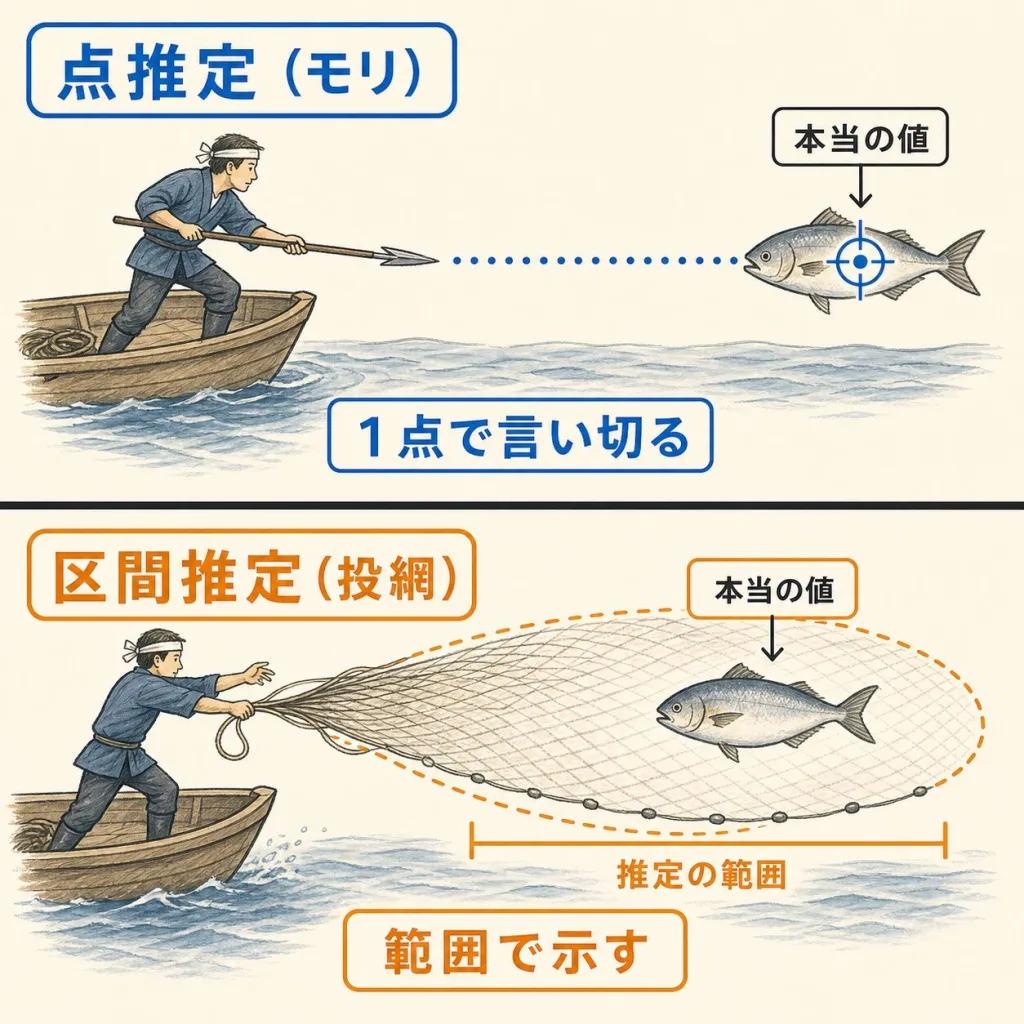
検定の相棒「点推定」と「区間推定」の違い
検定が「差があるか/ないか」を判定する道具なら、推定は「で、その値はいくつなの?」を予測する道具です。検定とセットで必ず出てくるので、ここで整理しておきましょう。
推定には2種類あります。イメージは魚を獲る「モリ」と「投網(とあみ)」です。
点推定(モリ)
「答えはズバリ◯◯です」と1点で言い切る予測。
- 例:平均は「50.2g」です
- シンプルだが、ピンポイントで当てるのは難しい
区間推定(投網)
「答えは◯◯〜◯◯の範囲に入っています」と幅で示す予測。
- 例:平均は「49.8〜50.6g」の間です
- 幅があるぶん、外しにくい(信頼できる)
「95%信頼区間」の正しい読み方
区間推定でよく出る「95%信頼区間」。これは「同じ調査を100回くり返したら、そのうち95回は、計算した区間の中に本当の値が入る」という意味です。「95%の確率で正解が入っている」とざっくり理解しておけば、実務では十分です。
投網が大きいほど魚は獲りやすいですが、「だいたいこの辺」としか言えません。
区間推定も同じで、区間の幅が広いほど「外さない」が、情報としては曖昧。データ数(サンプル)を増やすと、この幅は狭くなり、予測が鋭くなります。
| 比較 | 点推定 | 区間推定 |
|---|---|---|
| 答え方 | 1つの値で断定 | 範囲(幅)で示す |
| 当てやすさ | 外しやすい | 外しにくい |
| 情報の濃さ | 具体的(ピンポイント) | 幅のぶん曖昧 |
流れを実際の例で総まとめ|よくあるつまずき
ここまでの用語を、1つの例で一気に通してみましょう。「うちの新しい機械は、従来の機械より部品が軽く作れるはず」を検証する場面です。
仮説を立てる
帰無仮説:新旧の機械で重さに差はない/対立仮説:差がある
有意水準を決める
α=0.05(5%)と先に決めておく
データを取ってP値を計算する
新旧それぞれ部品を測定 → 計算の結果、P値=0.02 が出た
判定する
P値0.02 < α0.05 → 帰無仮説を棄却 →「重さに差がある(軽くなった)」と結論
このように、用語さえつながれば流れはとてもシンプルです。最後に、初心者がよくやる勘違いを2つ直しておきましょう。
❌ 間違い:P値が大きかったから「差はまったくない」と断言する
✅ 正しい:「差があるとは言い切れなかった」だけ。差がゼロだと証明できたわけではない(裁判の無罪と同じ)
❌ 間違い:「P値0.02だから、差がない確率は2%」
✅ 正しい:P値は「差がないと仮定したとき、このデータが出る確率」。仮説そのものの正しさの確率ではありません。ここは多くの人が混同するので要注意です。
よくある質問(FAQ)
A. 検定は「差があるか/ないか」をYES・NOで判定する道具、推定は「その値はいくつか」を予測する道具です。役割が違い、両方セットで使われます。
A. 「20回に1回の珍しさ」を基準にした慣習です。厳しくしたいときは1%、ゆるくてよいときは10%も使います。分野や目的で決めます。
A. はい、基本は「差がない・等しい・変わらない」です。否定したい主張をあえて立て、それを崩すのが検定の作法だからです。
A. 状況次第です。冤罪が怖い場面は第1種(α)を、見逃しが命取りの場面は第2種(β)を重視します。両方は同時に小さくできません。
まとめ:仮説検定はこの5つで完成
- 仮説検定=差が「偶然か本物か」を確率で判定する道具(味噌汁の味見)
- 帰無仮説(差はない)をあえて立て、崩れたら「差がある」と結論する
- P値が有意水準(5%)より小さければ「棄却」=差がある
- 第1種の過誤(あわてんぼう)と第2種の過誤(ぼんやり者)はシーソーの関係
- 点推定(モリ)と区間推定(投網)で「値そのもの」を予測する
考え方さえつかめば、t検定もカイ二乗検定も、すべて同じこの流れの応用です。次は「自分のデータにどの検定を使えばいいか」を学ぶと、一気に実戦的になります。
📚 次に読むべき記事
この分野を体系的にマスターする全体マップ。まず最初に押さえておきたい1本です。
考え方がわかったら、次は「自分のデータにどの検定を使うか」。実戦への第一歩です。
この記事で触れたP値と有意水準を、さらに深く・図解で掘り下げた隣接記事です。