{kind=link}
- 「不良率が5%から3%に下がった」けど、本当に改善したのか自信が持てない
- 「比率の検定」と「平均の検定」の違いがよくわからない
- 母比率の検定と「母不適合数(欠点数)」の検定、どっちを使うか迷う
- QC検定で「pバー」「nの中身」「ポアソン分布」が出てきて混乱する
- 母比率の検定の考え方と、検定統計量Zの計算手順(例題つき)
- 1つの母比率/2つの母比率の差/区間推定の使い分けと計算
- 「不良率」と「欠点数」の違い=母比率と母不適合数の使い分け
- ポアソン分布を使う母不適合数の検定・差・区間推定の全手順
- サンプルが少ないときの「正確な信頼区間(F分布)」と1級の連続修正
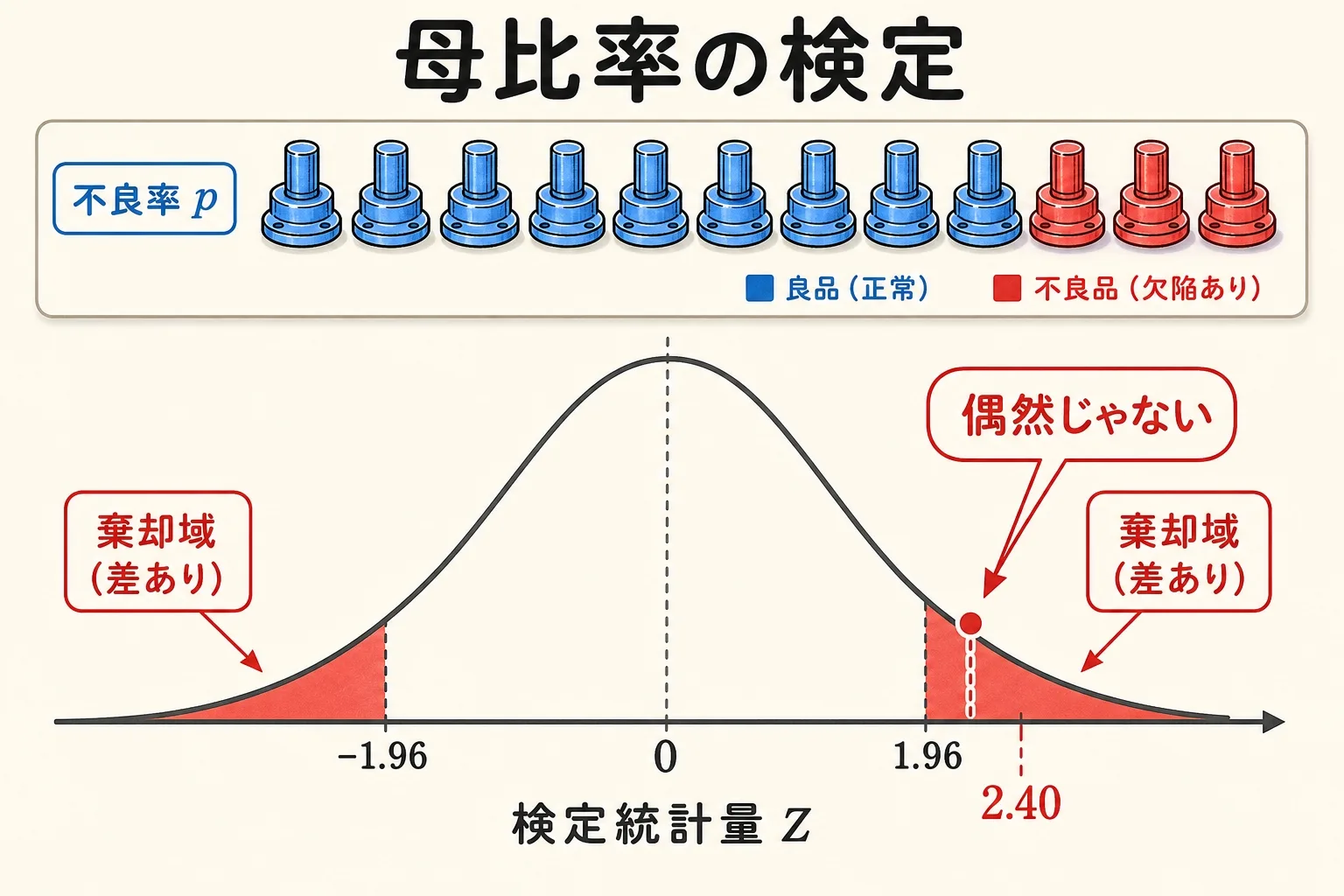
母比率の検定とは、不良率や合格率などの「割合」が、基準値から本当に変わったのか、それとも偶然のバラつきなのかを判定する手法です。
二項分布を正規分布で近似して、検定統計量Zを計算し、棄却域(両側検定なら±1.96の外側)に入るかを見るだけ。
「割合」を扱うか「個数(欠点数)」を扱うかで、母比率の検定とポアソン分布を使う母不適合数の検定に分かれます。この記事で両方まとめて理解できます。
目次
そもそも母比率の検定とは?「割合」を扱う検定
母比率の検定は、「割合(パーセント)」が変わったかを調べる検定です。たとえば次のような場面で使います。
・改善活動の前後で、不良率は本当に下がったか?
・テレビの視聴率は前回と変わったか?
・新しい教え方で、テストの合格率は上がったか?
どれも「全体に占める割合」を問題にしています。これが母比率(p)です。
「母比率」と「標本比率」の違い
混乱しやすいのが2つの「比率」です。ここだけ押さえれば大丈夫です。
母比率 p
本当に知りたい全体の割合。普通は直接わからない。
例:工場全製品の本当の不良率
標本比率 p̂(ピーハット)
実際に調べた一部の割合。手元で計算できる。
例:抜き取った100個中の不良5個=5%
母比率の検定は、二項分布を正規分布で近似して計算します。この近似が成り立つには、目安として「np ≧ 5 かつ n(1−p) ≧ 5」(テキストによっては10)が必要です。
サンプルが少なすぎるとこの近似が崩れるので、その場合は後半で解説する正確な方法(F分布)を使います。
1つの母比率の検定|「不良率は基準より下がった?」を確かめる
まずは基本形。「ある1つの比率が、決まった基準値(p₀)と違うか」を調べる検定です。これは「母比率が既知の値と等しいか」を見るので、Z検定(標準正規分布)を使います。
分母の「√( p₀(1−p₀)/n )」は標本比率がどれくらいバラつくか(標準誤差)を表します。やることは単純で、「実際の比率と基準の差」を「ありえるバラつき」で割っているだけです。差がバラつきに対して大きければZが大きくなり、「偶然じゃない」と判断します。
1つの母比率の検定では、「帰無仮説が正しい(=母比率は p₀ である)」と仮定して計算します。だから分母のバラつきも基準値 p₀ で計算するのが正解です。ここを p̂ で計算してしまうミスが非常に多いので注意してください。
例題:不良率5%→3%は「改善した」と言えるか
従来の不良率は5%(p₀=0.05)でした。改善活動の後、400個を検査したところ不良は12個(標本比率 p̂=0.03)でした。本当に改善したと言えるでしょうか。有意水準5%で検定します。
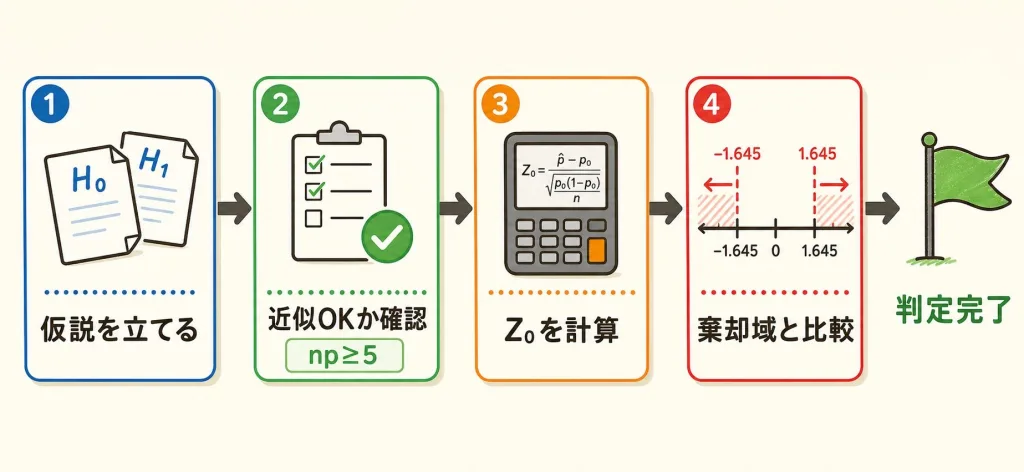
仮説を立てる
帰無仮説 H₀:p = 0.05(変わらない)/ 対立仮説 H₁:p < 0.05(下がった=片側検定)
近似の前提を確認
np₀=400×0.05=20 ≧ 5、n(1−p₀)=400×0.95=380 ≧ 5。正規近似OK。
検定統計量Z₀を計算
分子:p̂ − p₀ = 0.03 − 0.05 = −0.02
分母:√( 0.05×0.95 / 400 ) = √( 0.0475 / 400 ) = √0.00011875 ≒ 0.010897
Z₀ = −0.02 ÷ 0.010897 ≒ −1.835
判定する(片側5%)
片側検定の棄却域は Z < −1.645。
Z₀=−1.835 < −1.645 なので棄却 →「不良率は有意に下がった(改善した)」と言える。
・両側検定 5%:|Z₀| > 1.96 で棄却
・片側検定 5%:Z₀ が ±1.645 の外側で棄却
・両側検定 1%:|Z₀| > 2.576 で棄却
「改善したか(下がったか)」のように方向が決まっているときは片側検定を使います。
2つの母比率の差の検定|A工場とB工場の不良率を比べる
次は「2つのグループの比率に差があるか」を調べる検定です。A工場とB工場の不良率、男女の購入率、機械Aと機械Bの合格率など、QC検定で頻出のパターンです。
差の検定では「2つの母比率は等しい(差がない)」と仮定します。仮定どおり等しいなら、バラつきの計算には2つのデータを合算した共通の比率 p̄を使うのが筋です。
p̄ は「全体の不良個数 ÷ 全体の検査個数」で求めます。これを忘れると計算が合いません。
例題:2つのラインの不良率に差はあるか
ラインA:300個中 不良18個(p̂₁=0.06)/ ラインB:200個中 不良6個(p̂₂=0.03)。差はあるか、有意水準5%(両側)で検定します。
仮説:H₀:p₁=p₂(差なし)/ H₁:p₁≠p₂(差あり・両側)
プール比率 p̄ を計算
p̄ = (18 + 6) / (300 + 200) = 24 / 500 = 0.048
分母(標準誤差)を計算
p̄(1−p̄) = 0.048 × 0.952 = 0.045696
(1/n₁ + 1/n₂) = (1/300 + 1/200) = 0.003333 + 0.005 = 0.008333
分母 = √(0.045696 × 0.008333) = √0.00038080 ≒ 0.019514
Z₀を計算して判定
Z₀ = (0.06 − 0.03) ÷ 0.019514 = 0.03 ÷ 0.019514 ≒ 1.537
両側5%の棄却域は |Z₀| > 1.96。1.537 < 1.96 なので棄却できない →「2つのラインの不良率に差があるとは言えない」。
【QC検定1級向け】連続修正(Yatesの補正)
1級では精度を上げるため、連続修正(continuity correction)を加えることがあります。割合は本来「飛び飛び(離散)」の値なのに、なめらかな正規分布で近似するズレを補うものです。
分子を小さくする補正なので、Zの値も小さくなり、「差あり」と判定されにくく(保守的に)なります。サンプルが大きいと補正の影響はほぼ無視できます。2級では基本的に補正なしで覚えてOKです。

母比率の区間推定|内閣支持率の「±3%」はこう計算する
検定が「差があるか」を判定する道具なら、推定は「本当の比率はどのあたりの範囲にあるか」を予測する道具です。テレビの視聴率や内閣支持率の「誤差±3%」も、この区間推定で計算されています。
検定では基準値 p₀ で分母を計算しましたが、推定では「真の値がわからないので、手元の p̂ で代用」します。ここが検定と推定の計算上の大きな違いです。
例題:支持率の信頼区間を求める
600人に調査して、支持が240人(p̂=0.40)。95%信頼区間を求めます。
標準誤差を計算
√( 0.40×0.60 / 600 ) = √( 0.24 / 600 ) = √0.0004 = 0.02
誤差の幅を計算
1.96 × 0.02 = 0.0392 ≒ ±3.9%(これが「±約4%」の正体)
区間を出す
0.40 ± 0.039 = 0.361 〜 0.439(約36.1%〜43.9%)
サンプルが少ないとき|正確な信頼区間(F分布)
これまでの式は正規近似が前提でした。しかしサンプルが少ない/不良が0個に近いときは近似が崩れ、区間がマイナスになるなど不自然になります。そこで使うのがF分布を使った正確な信頼区間(クロッパー・ピアソン法)です。
二項分布とF分布には数学的な関係があり、これを利用すると近似に頼らず厳密な区間が出せます。手計算は複雑なので、QC検定ではF表を読んで当てはめる形で出題されます。
「nが小さい・xが極端なら正規近似ではなくF分布の正確法」と覚えておけば十分です。サンプルが大きければ、正確法と正規近似の結果はほぼ一致します。
「不良率」と「欠点数」は別物|母不適合数(欠点数)とは
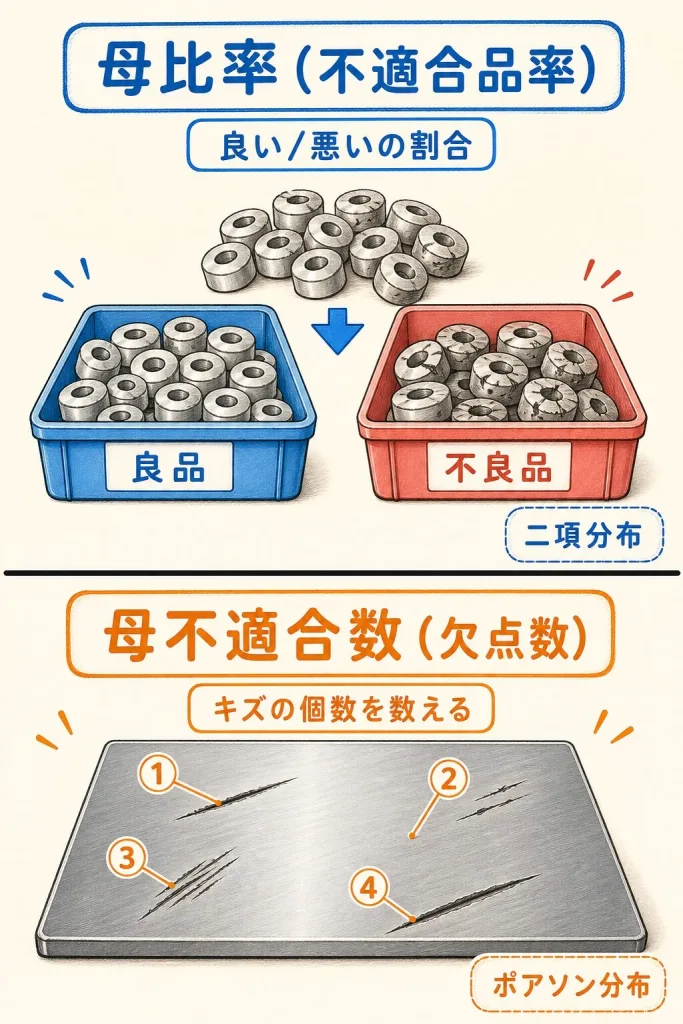
ここからが多くの人がつまずく分かれ道です。「不良率(母比率)」と「欠点数(母不適合数)」は、扱う分布も計算式も違います。まず違いをはっきりさせましょう。
母比率(不適合品率)
製品を「良品/不良品」に分け、不良品の割合を見る。
1個に欠陥が何個あっても「不良品1個」。
従う分布:二項分布 → 正規近似
母不適合数(欠点数)
製品にあるキズ・欠点の「個数」を数える。
1個の製品にキズが3個なら「3」と数える。
従う分布:ポアソン分布 → 正規近似
・「割合(%)」で表すなら → 母比率(例:不良率3%)
・「個数」で表すなら → 母不適合数(例:鋼板1枚あたりキズ4個、布100mあたり織キズ7個)
「1製品に複数のキズがありうる」のが欠点数の特徴です。
なぜポアソン分布なのか
欠点数は「めったに起きないことが、広い面積や長さの中で何回起きるか」を数えるデータです。これはポアソン分布の得意分野です。ポアソン分布には「平均(λ)=分散(λ)」という大きな特徴があり、これが検定式の根っこになります。
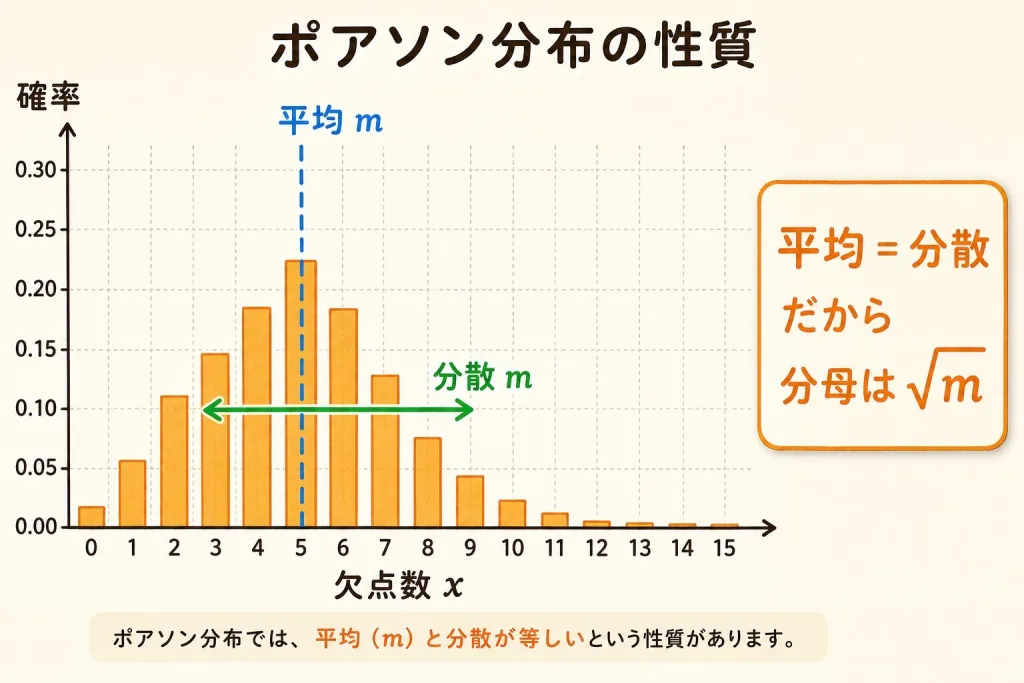
母不適合数の検定|「キズが増えてない?」を確かめる
1つの母不適合数の検定は、「観測された欠点数が、基準の欠点数(m₀)から変わったか」を見ます。ポアソン分布は「平均=分散」なので、バラつき(標準偏差)は√m₀で表せます。これが式に効いてきます。
母比率の検定の分母は √(p₀(1−p₀)/n) と複雑でしたが、母不適合数はポアソン分布の「平均=分散」のおかげで分母が √m₀ だけとスッキリします。これがポアソンを使う最大のメリットです。
例題:鋼板のキズは基準より増えたか
従来、鋼板1枚あたりのキズは平均9個(m₀=9)でした。最近の1枚を調べるとキズが16個(x=16)。増えたと言えるか、有意水準5%(両側)で検定します。
仮説:H₀:m=9(変わらない)/ H₁:m≠9(両側)
分母を計算:√m₀ = √9 = 3
Z₀を計算:Z₀ = (16 − 9) ÷ 3 = 7 ÷ 3 ≒ 2.333
判定:両側5%の棄却域 |Z₀| > 1.96。2.333 > 1.96 なので棄却 →「キズの数は有意に変化した(増えた)」と言える。
母不適合数の差の検定|生産量(面積)が違う2ラインを比べる
2つのラインの欠点数を比べるとき、難しいのは「調べた量(面積・長さ・枚数)が違う」ことです。10枚で20個と、5枚で15個では、単純に20と15を比べても意味がありません。そこで「単位あたりの欠点数」に直して比べます。
よく見ると、母比率の差の検定の式から「(1−p̄)」が消えただけの形です。ポアソン分布では「平均=分散」なので、母比率にあった (1−p) の項が不要になるためです。差の検定はプール値を使うという考え方は共通です。
例題:2つのラインの単位あたり欠点数に差はあるか
ラインA:10枚で欠点 50個(û₁=5.0)/ ラインB:8枚で欠点 24個(û₂=3.0)。差はあるか、有意水準5%(両側)で検定します(n は「枚数」とします)。
プール ū を計算:ū = (50 + 24) / (10 + 8) = 74 / 18 ≒ 4.111
分母を計算
(1/n₁ + 1/n₂) = (1/10 + 1/8) = 0.1 + 0.125 = 0.225
分母 = √(4.111 × 0.225) = √0.92498 ≒ 0.9618
Z₀を計算して判定
Z₀ = (5.0 − 3.0) ÷ 0.9618 = 2.0 ÷ 0.9618 ≒ 2.079
|Z₀|=2.079 > 1.96 なので棄却 →「2ラインの単位あたり欠点数に差がある」と言える。
母不適合数の区間推定|本当の欠点数はどの範囲か
観測された欠点数から、「本当の母不適合数(m)はどの範囲にあるか」を推定します。サンプルが多ければ、母比率と同じく正規近似で簡単に出せます。
例題:欠点数25個から区間を求める
ある製品ロットで欠点が25個(x=25)観測されました。95%信頼区間は次のとおりです。
標準偏差を計算:√x = √25 = 5
誤差幅:1.96 × 5 = 9.8
区間:25 ± 9.8 = 15.2 〜 34.8
欠点数が少ない(目安で x < 5〜10)と正規近似がズレて、下限がマイナスになるなど不自然になります。このときはポアソン分布とカイ二乗分布の数学的な関係を使った正確な区間を求めます。
なぜカイ二乗かというと、ポアソン分布の確率の合計が、カイ二乗分布の確率で正確に表せるという関係があるためです。QC検定ではカイ二乗表(χ²表)の値を式に当てはめて求める形で出題されます。「欠点数が少ない=正規近似ではなくカイ二乗の正確法」と覚えておけば対応できます。
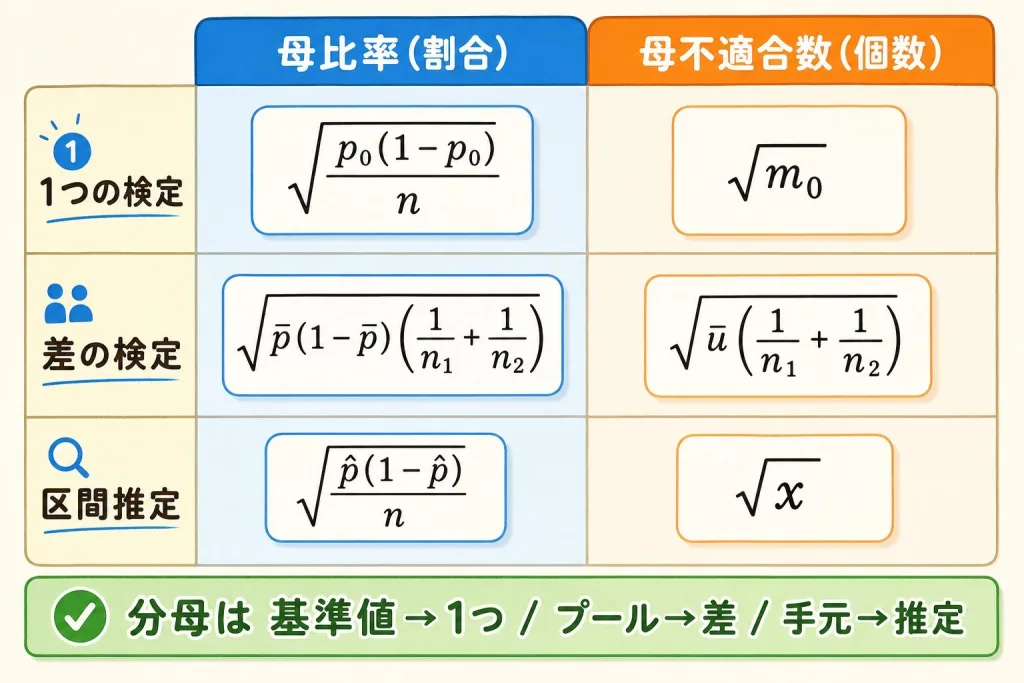
全パターン早見表|どの式をいつ使うか
ここまでの内容を一覧にまとめます。試験前はこの表を見返せば、どの式を使うか迷いません。
| 扱うもの | 場面 | 使う分布 | 分母(バラつき) |
|---|---|---|---|
| 母比率(割合) | 1つの検定 | 二項→正規 | √(p₀(1−p₀)/n) |
| 母比率(割合) | 差の検定 | 二項→正規 | √(p̄(1−p̄)(1/n₁+1/n₂)) |
| 母比率(割合) | 区間推定 | 正規/少数はF分布 | √(p̂(1−p̂)/n) |
| 母不適合数(個数) | 1つの検定 | ポアソン→正規 | √m₀ |
| 母不適合数(個数) | 差の検定 | ポアソン→正規 | √(ū(1/n₁+1/n₂)) |
| 母不適合数(個数) | 区間推定 | 正規/少数はχ²分布 | √x |
① 1つの検定の分母は基準値(p₀ や m₀)で計算
② 差の検定の分母はプール値(p̄ や ū)で計算
③ 区間推定の分母は手元の値(p̂ や x)で計算
この3パターンさえ押さえれば、母比率も母不適合数も同じ考え方で解けます。
よくある質問(FAQ)
A. 「割合(%)」なら母比率、「キズや欠点の個数」なら母不適合数です。1製品に複数の欠点がありうるなら欠点数(ポアソン分布)を使います。
A. 1つの検定は基準値p₀で、差の検定は2群をまとめたプール値p̄でバラつきを計算します。「差はない」と仮定する以上、共通の比率で揃えるのが正しいからです。
A. 正規近似が崩れるからです。少数のときは二項・ポアソン分布と数学的につながるF分布・カイ二乗分布で正確に求めます。
A. 主にQC検定1級です。離散データを連続分布で近似するズレを補います。サンプルが大きければ影響は小さく、2級では補正なしが基本です。
A. 「下がったか」「増えたか」など方向が決まっているなら片側、「変わったか(増減どちらでも)」なら両側を使います。
まとめ:母比率・母不適合数の検定はこれで完成
- 母比率=割合(不良率など)。二項分布を正規近似してZ検定する
- 母不適合数=欠点の個数。ポアソン分布(平均=分散)を使い、分母が√でシンプルになる
- 1つの検定=基準値、差の検定=プール値、区間推定=手元の値で分母を計算
- 判定は 両側5%で|Z|>1.96、片側5%で±1.645 が定番
- サンプルが少ないときは 母比率→F分布、母不適合数→カイ二乗分布の正確法
この6パターンと3つの共通ルールを押さえれば、QC検定の計数値の検定・推定はほぼ攻略できます。次は検定全体の選び方や、計数値以外の検定にも視野を広げていきましょう。
📚 次に読むべき記事
検定・推定の全体像を体系的に学べるマップ。まず最初に押さえたい1本です。
「結局どの検定を使えばいいか」を1枚のフローで解決。計数値の検定の位置づけがわかります。
母不適合数の検定の土台になる分布。「平均=分散」の意味を深掘りして理解できます。