
- マハラノビス距離の公式を見た瞬間、行列の記号が出てきて思考停止する
- 「共分散行列の逆行列」って何をしているのかイメージがわかない
- 普通の距離(ユークリッド距離)と何が違うのか、本質的に理解できていない
- 判別分析やMT法で「マハラノビス距離を使う」と言われても、なぜそれが必要なのかピンとこない
- マハラノビス距離が「何を解決する距離」なのか、身長と体重の例で直感的に理解
- ユークリッド距離の「3つの致命的な弱点」と、マハラノビス距離がそれをどう克服するか
- 公式 D² = (x − μ)ᵀΣ⁻¹(x − μ) の各パーツの意味を1つずつ分解して解説
- 判別分析での具体的な使い方
多変量解析や判別分析を学んでいると、突然現れる「マハラノビス距離」。公式を見た瞬間に「行列の逆行列? 転置? 無理……」と心が折れた人も多いのではないでしょうか。
でも、安心してください。マハラノビス距離がやっていることは、実はとてもシンプルです。
一言でいうと、「データのバラつき方と相関関係を考慮して、"本当の遠さ"を測る距離」です。
この記事では、数式をいきなり出すのではなく、まず「なぜ普通の距離ではダメなのか?」という問題から出発します。問題が理解できれば、マハラノビス距離の公式は「なるほど、だからこうするのか」と腑に落ちるはずです。
目次
普通の距離の「3つの致命的な弱点」
マハラノビス距離を理解する最短ルートは、まず「普通の距離(ユークリッド距離)」の弱点を知ることです。
ここでは、「身長」と「体重」の2つのデータで、ある人が集団の平均からどれだけ離れているかを考えてみましょう。日本人成人男性の平均が身長170cm・体重65kgだとします。
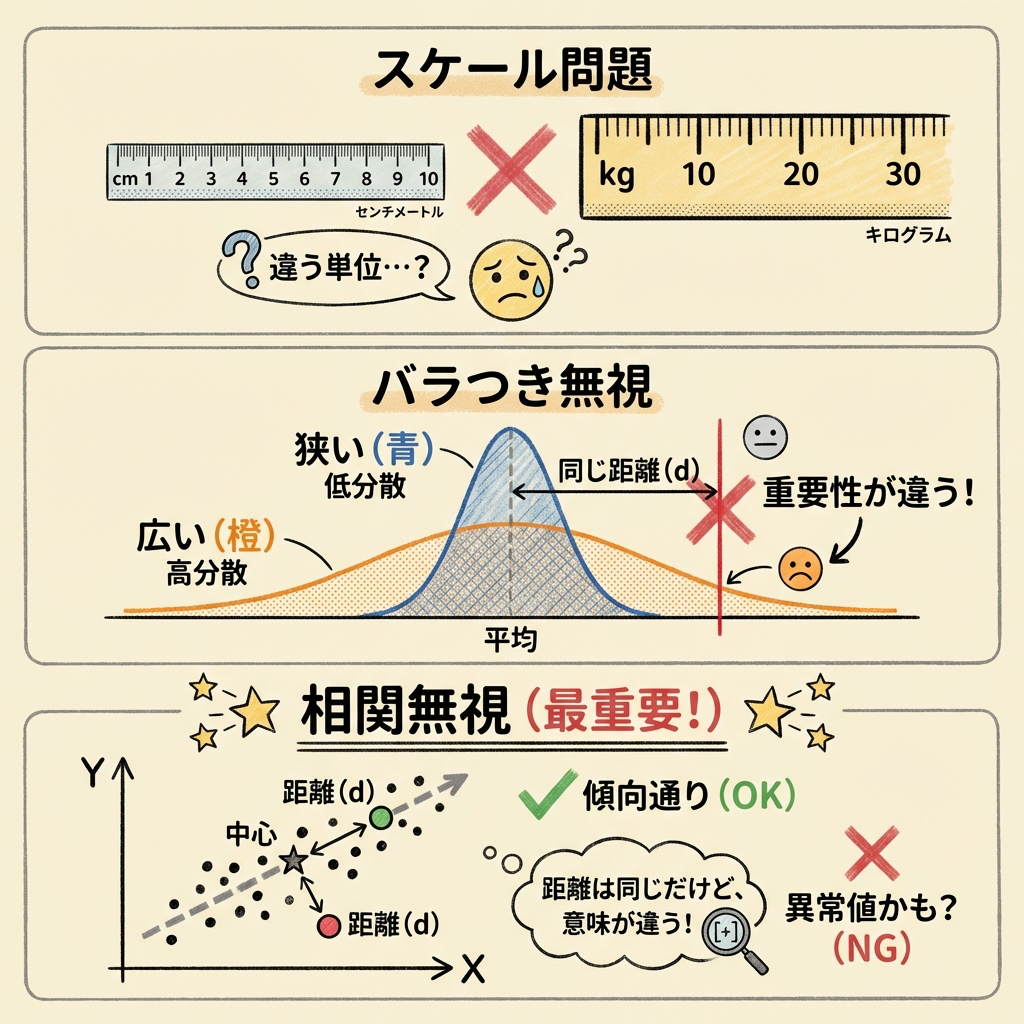
⚠️ 弱点①:スケール(単位)が違う問題
Aさんは身長180cm・体重65kg、Bさんは身長170cm・体重75kgとします。
ユークリッド距離を素朴に計算すると……
Bさんの距離 = √((170−170)² + (75−65)²) = √(100) = 10
同じ距離「10」になりました。しかし、身長の10cmと体重の10kgは同じ重みでしょうか? 身長の標準偏差が6cm、体重の標準偏差が10kgだとすると、身長10cmのズレは約1.67σ、体重10kgのズレは1.0σです。統計的にはAさんの方が「珍しい」のに、ユークリッド距離はそれを区別できません。
「cm」と「kg」というものさしの目盛りの大きさが違うのに、同じ数値として足し算してしまっている。これは「メートル」と「マイル」を混ぜて足しているようなものです。
⚠️ 弱点②:バラつきの大小を無視する問題
弱点①の延長ですが、もう少し掘り下げます。
たとえば「社員の年齢」と「月収」でデータを扱うとします。年齢は20〜60歳(範囲40、σ ≈ 10歳)、月収は20万〜80万円(範囲60万、σ ≈ 15万円)だとしましょう。
この場合、「年齢が平均から20歳離れている(2σ)」のと「月収が平均から20万円離れている(1.3σ)」では、年齢の方がはるかに「異常」です。しかし、ユークリッド距離ではどちらも「20の差」として同じ扱いです。
これは「そのデータにおけるバラつきの大きさ」を無視していることが原因です。
⚠️ 弱点③:変数間の相関を無視する問題 ── これが最大の問題
ここが最も重要で、マハラノビス距離が生まれた最大の理由です。
身長と体重には正の相関がありますよね。背が高い人は体重も重い傾向がある。つまり「身長180cm・体重80kg」は「大柄な人」として珍しくありません。
しかし、「身長180cm・体重40kg」はどうでしょう? 身長の割に極端に軽い。これは明らかに「異常値」です。
Cさん:身長180cm・体重80kg
「大柄だけど普通」
身長と体重のバランスが相関に沿っている
→ 統計的には「近い」
Dさん:身長180cm・体重40kg
「背が高いのに極端に軽い」
身長と体重のバランスが崩れている
→ 統計的には「遠い(異常)」
ところが、ユークリッド距離(標準化しても)では、CさんとDさんが平均から同じくらいの距離と判定されてしまうことがあります。「身長と体重が連動する」という相関の情報を無視しているからです。
① スケール(単位)が違う → 数値が大きい変数に引っ張られる
② バラつきの大小を無視 → 珍しさの度合いが反映されない
③ 相関を無視 → 「ありえない組み合わせ」を見逃す
マハラノビス距離は、この3つすべてを一度に解決します。
マハラノビス距離とは? ── 「楕円の形」を考慮した距離
🎯 一言でいうと
データのバラつき(分散)と変数間の関係(共分散・相関)を考慮して、ある点が集団の中心からどれだけ「統計的に離れているか」を測る距離。
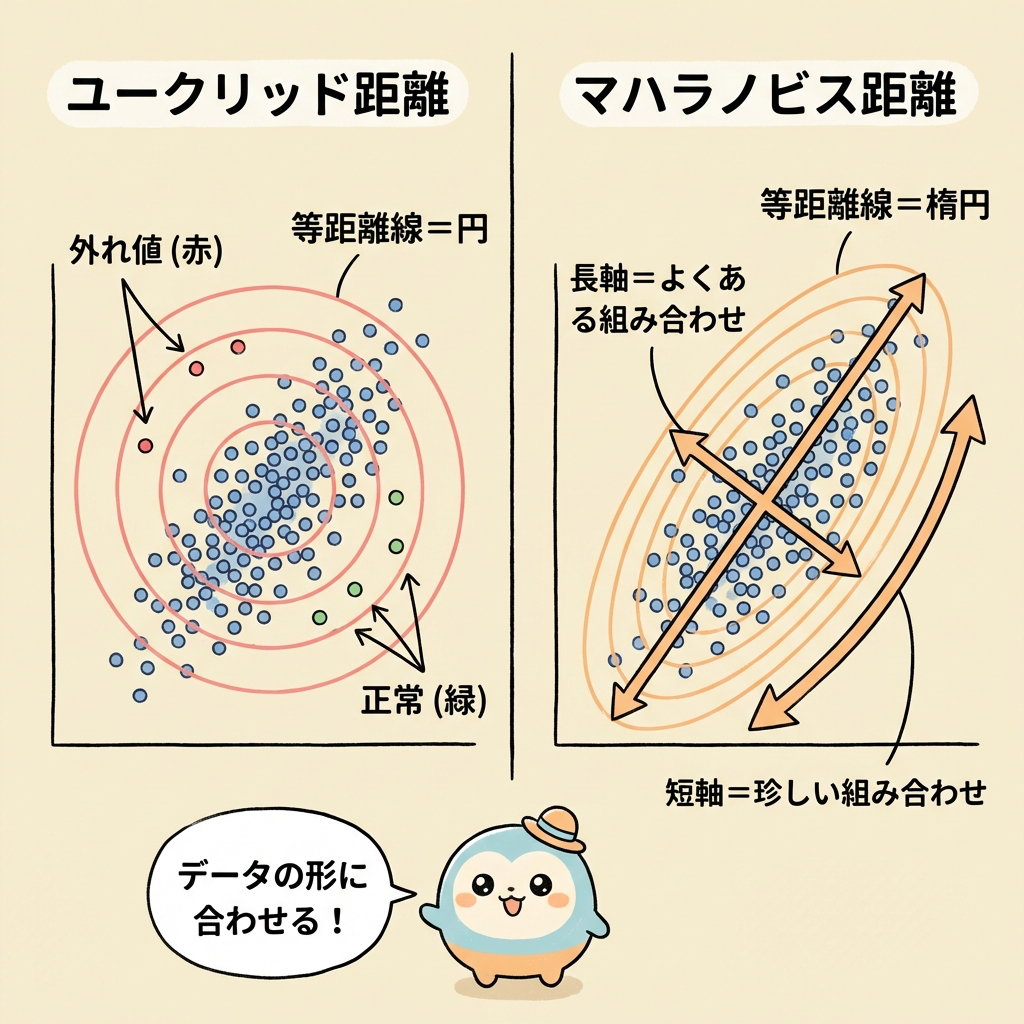
⭕ 「円」と「楕円」の違いでイメージする
ここがマハラノビス距離を理解する核心部分です。
身長と体重の散布図を思い浮かべてください。データの点は、平均を中心にバラついています。しかし、身長と体重には相関があるため、データは円形ではなく斜めに傾いた楕円形に散らばっています。
ユークリッド距離の「等距離線」
円
すべての方向に同じ距離感。
データの散らばり方を無視している。
マハラノビス距離の「等距離線」
楕円
データの散らばり方に沿った形。
相関の方向も考慮している。
ユークリッド距離で「平均から同じ距離」の点を結ぶと円になります。しかし、データの散らばりは楕円なので、円の上にある点でも「楕円の内側(普通の範囲)」の点と「楕円の外側(異常値)」の点が混在してしまいます。
マハラノビス距離で「平均から同じ距離」の点を結ぶとデータの散らばりに沿った楕円になります。楕円の長軸方向(身長と体重が連動して増える方向)に離れても距離は小さく、楕円の短軸方向(身長が高いのに体重が軽い=珍しい方向)に離れると距離が大きくなります。
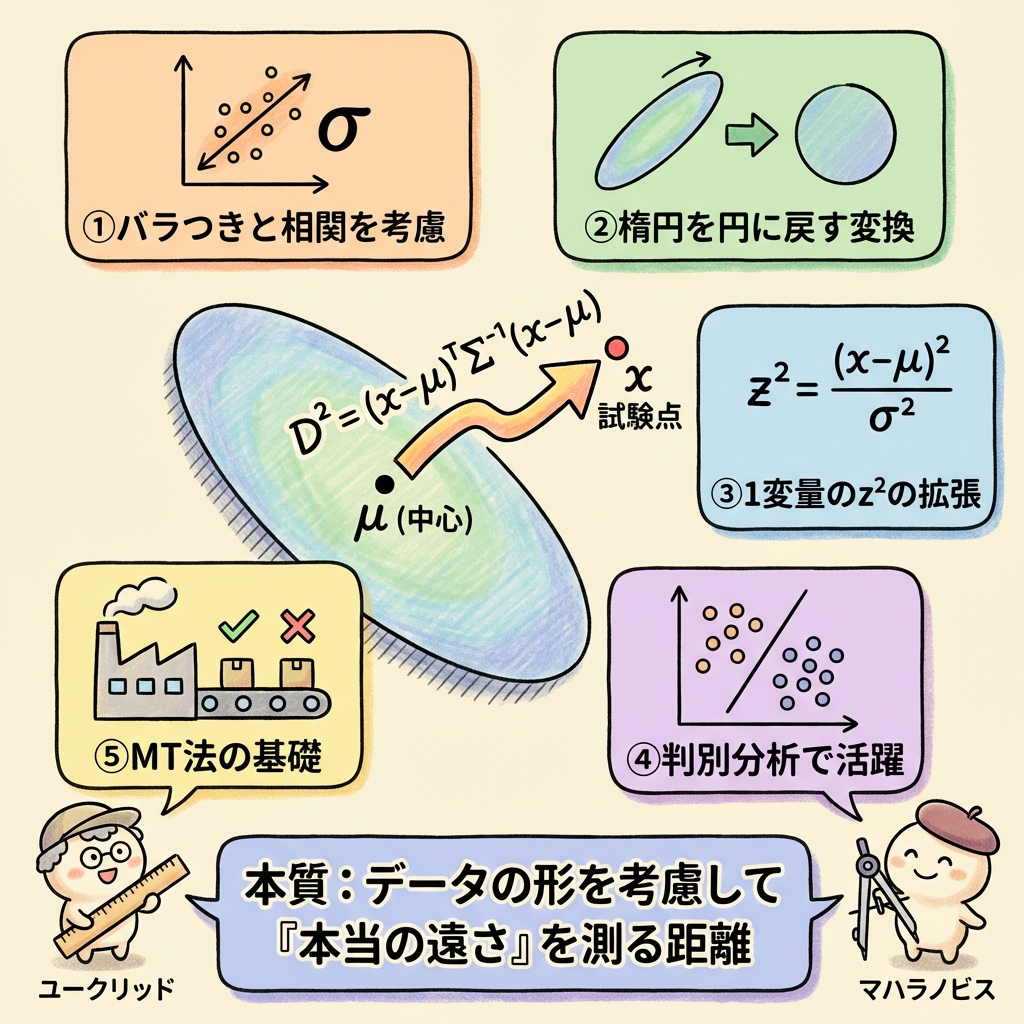
マハラノビス距離は、「データの楕円をいったん円に変換してから距離を測る」のと同じことをしています。歪んだ地図をまっすぐに直してから距離を測るイメージです。この「楕円 → 円」の変換を数式で行うのが、共分散行列の逆行列 Σ⁻¹ です。
公式を1つずつ分解する ── 怖くない行列の読み方
📐 まずは1変量(変数が1つ)から
いきなり行列の公式を見ると怖いので、まず変数が1つだけの場合を確認しましょう。
見覚えがありませんか? これは「標準化した値の2乗」です。つまり z² です。「平均から何σ離れているか」を測っているだけ。
たとえば、あるクラスのテストの平均が60点、標準偏差が10点のとき、90点を取った人のマハラノビス距離は……
D = 3(平均から3σ離れている)
1変量なら簡単ですよね。これを変数が2つ以上に拡張したものが、マハラノビス距離の一般式です。
📐 多変量の公式 ── 各パーツの意味
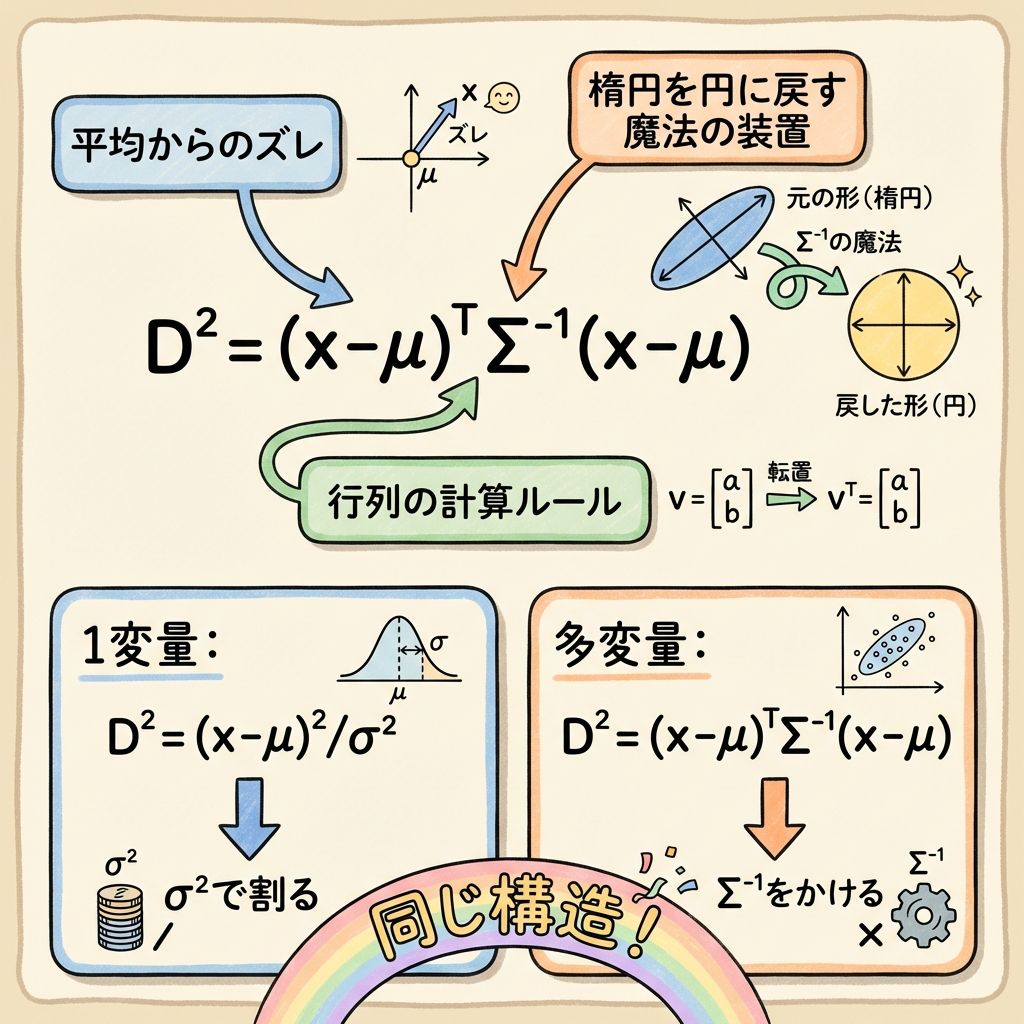
この公式には4つのパーツがあります。1つずつ意味を見ていきましょう。
| 記号 | 名前 | 意味(身長・体重の例) |
|---|---|---|
| x | 判定したいデータ | 例:(180, 40) = 「身長180cm、体重40kg」の人 |
| μ | 集団の平均ベクトル | 例:(170, 65) = 「平均身長170cm、平均体重65kg」 |
| (x − μ) | 平均からのズレ | 例:(10, −25) = 「身長+10cm、体重−25kg」 |
| Σ⁻¹ | 共分散行列の逆行列 ⭐ 最重要パーツ |
バラつきの大小と相関の影響を同時に補正する装置。1変量の「σ² で割る」操作を多変量に一般化したもの。 |
🔑 Σ⁻¹(共分散行列の逆行列)は何をしているのか?
ここが最も「わからない」と言われるポイントなので、丁寧に説明します。
共分散行列 Σ は、データの散らばり方を1つの行列にまとめたものです。2変量の場合はこうなります。
| σ₁²(身長の分散) | σ₁₂(身長と体重の共分散) |
| σ₁₂(身長と体重の共分散) | σ₂²(体重の分散) |
対角線に各変数の分散(バラつきの大きさ)、それ以外に共分散(変数間の関係の強さ)が入っています。
この逆行列 Σ⁻¹ を距離の計算に挟むことで、次の2つのことが同時に行われます。
(ものさしを揃える)
(楕円を円に戻す)
正しく測れる
1変量で「σ² で割る」ことで標準化していたのが、多変量では「Σ⁻¹ をかける」ことに拡張された── それだけのことなのです。
1変量:D² = (x − μ) × 1/σ² × (x − μ) ← σ² で割る
多変量:D² = (x − μ)T × Σ⁻¹ × (x − μ) ← 共分散行列の逆行列をかける
構造はまったく同じです。1変量の「σ² で割る」が、多変量では「Σ⁻¹ をかける」に変わっただけ。
【計算例】身長と体重で実際に計算してみる
公式を眺めるだけでなく、実際に手を動かしてみましょう。数値は簡単にしてあります。
📋 データの設定
| 項目 | 値 |
|---|---|
| 集団の平均 μ | 身長 170cm、体重 65kg → μ = (170, 65) |
| 身長の分散 σ₁² | 36(標準偏差 6cm) |
| 体重の分散 σ₂² | 25(標準偏差 5kg) |
| 共分散 σ₁₂ | 18(相関係数 r = 18/(6×5) = 0.6) |
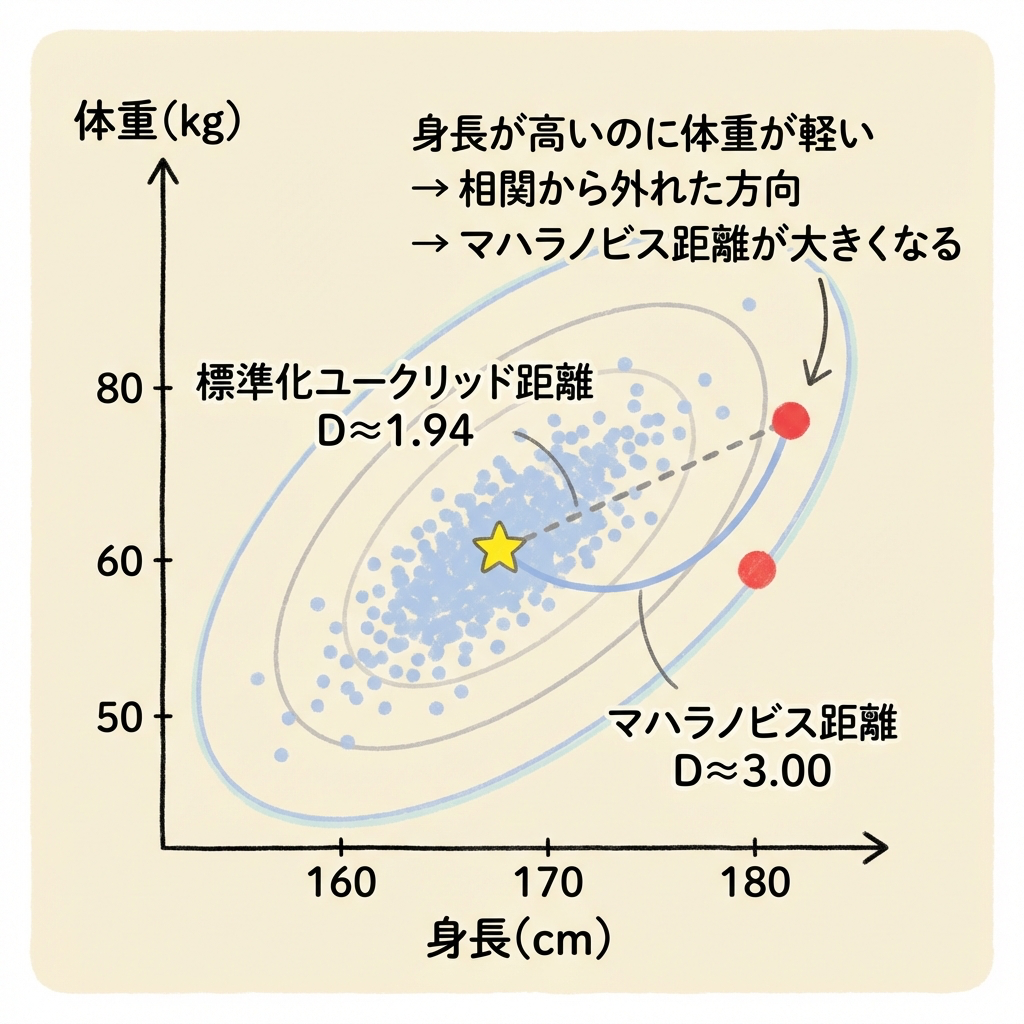
| 判定したい人 x | 身長 180cm、体重 60kg → x = (180, 60) |
この人は「身長が高い割に体重が軽い」── 相関から外れた方向にズレています。マハラノビス距離はこれを捉えるはずです。
STEP 1:平均からのズレを求める
身長は平均より+10cm、体重は平均より−5kg。
STEP 2:共分散行列の逆行列を求める
| 18 25 |
行列式 |Σ| = 36×25 − 18×18 = 900 − 324 = 576
逆行列 Σ⁻¹ = (1/576) × | 25 −18 |
| −18 36 |
STEP 3:マハラノビス距離を計算する
まず Σ⁻¹(x − μ) を計算:
(1/576) × | 25 −18 | × | 10 |
| −18 36 | | −5 |
= (1/576) × | 25×10 + (−18)×(−5) | = (1/576) × | 250 + 90 | = (1/576) × | 340 |
| (−18)×10 + 36×(−5) | | −180 − 180| | −360 |
次に (x − μ)T をかける:
D² = (10, −5) × (1/576) × (340, −360)
= (1/576) × (10×340 + (−5)×(−360))
= (1/576) × (3400 + 1800)
= (1/576) × 5200
= 9.03
D = √9.03 ≈ 3.0
マハラノビス距離 D ≈ 3.0
この人は集団の中心から約3σ離れている。正規分布を仮定すると上位0.3%に入る「かなり珍しい人」と判断できます。
🔍 ユークリッド距離と比較してみる
もしユークリッド距離(標準化あり)で計算すると……
D = √3.78 ≈ 1.94
| 距離の種類 | D² | D | 評価 |
|---|---|---|---|
| 標準化ユークリッド距離 | 3.78 | 1.94 | 約2σ → そこまで珍しくない? |
| マハラノビス距離 | 9.03 | 3.00 | 約3σ → かなり珍しい! |
マハラノビス距離の方が大きくなりました。これは「身長が高いのに体重が軽い」という、相関から外れた方向のズレをきちんと検出しているからです。標準化ユークリッド距離は相関を考慮しないため、この異常を過小評価してしまいます。
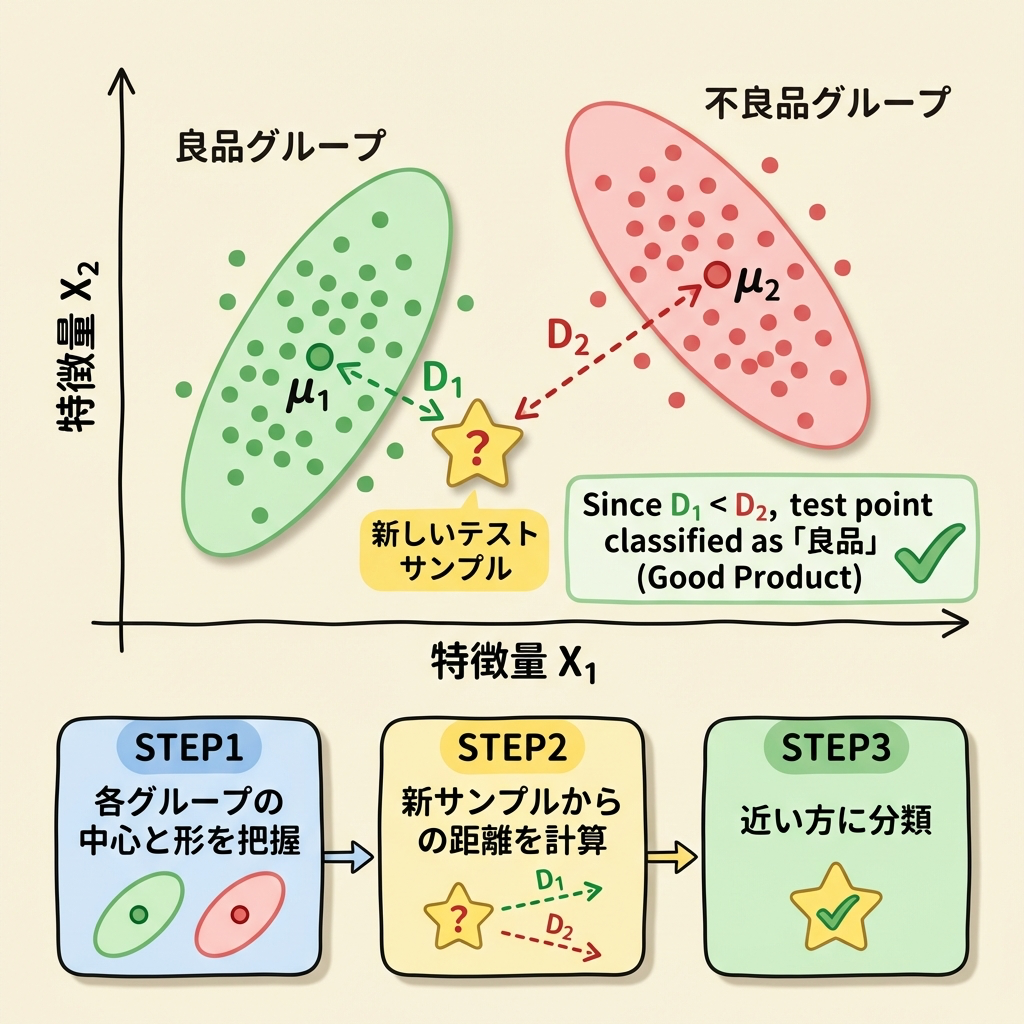
判別分析での使い方 ── 「どちらのグループに近いか」で分類する
マハラノビス距離は、判別分析で最も威力を発揮します。使い方はシンプルです。
🏭 たとえば「良品」と「不良品」の判別
工場で製品を検査する場面を考えましょう。過去のデータから「良品グループ」と「不良品グループ」の特徴(平均と共分散行列)がわかっています。
新しい製品が1つ流れてきたとき、それが「良品に近いか」「不良品に近いか」を判定したい。このとき、マハラノビス距離を使います。
各グループの「中心」と「散らばり方」を把握する
良品グループの平均ベクトル μ₁ と共分散行列 Σ₁
不良品グループの平均ベクトル μ₂ と共分散行列 Σ₂
を過去のデータから計算しておく。
新しいサンプルから各グループまでのマハラノビス距離を計算する
良品グループまでの距離:D₁² = (x − μ₁)T Σ₁⁻¹ (x − μ₁)
不良品グループまでの距離:D₂² = (x − μ₂)T Σ₂⁻¹ (x − μ₂)
距離が近い方のグループに分類する
D₁² < D₂² → 良品グループに分類
D₁² > D₂² → 不良品グループに分類
良品グループと不良品グループでは、データの散らばり方(分散の大きさ)や変数間の相関が異なることがほとんどです。ユークリッド距離ではこの違いを反映できないため、誤分類が増えます。マハラノビス距離を使えば、各グループの「データの形(楕円の形)」に合わせた距離が測れるので、より正確な判別が可能になります。
📊 MT法(マハラノビス・タグチ法)との関係
品質管理の分野で有名なMT法(マハラノビス・タグチ法)も、マハラノビス距離がベースです。
MT法では「正常な状態」のデータだけで基準空間(単位空間)を作り、新しいデータがその基準空間からどれだけ離れているかをマハラノビス距離で測定します。距離が大きければ「異常」と判定します。
判別分析が「2つのグループのどちらに近いか」を比較するのに対し、MT法は「正常グループからどれだけ離れているか」を1つの基準で判定する── アプローチは違いますが、距離の測り方はどちらもマハラノビス距離です。
ユークリッド距離 vs マハラノビス距離 ── 最終比較
| 比較項目 | ユークリッド距離 | マハラノビス距離 |
|---|---|---|
| スケールの違い | 🔴 考慮しない(単位が大きい変数に引っ張られる) | 🟢 分散で標準化される |
| バラつきの大小 | 🔴 考慮しない | 🟢 分散が大きい方向の距離を適切に縮小 |
| ⭐ 変数間の相関 | 🔴 考慮しない(最大の弱点) | 🟢 共分散行列の逆行列で相関を除去 |
| 等距離面の形 | 円(球) | 楕円(楕円体)── データの散らばりに沿った形 |
| 公式(多変量) | D² = Σ(xᵢ − μᵢ)² | D² = (x−μ)TΣ⁻¹(x−μ) |
| 計算コスト | 🟢 小さい(足し算だけ) | 🔴 大きい(逆行列の計算が必要) |
| 使いどころ | 変数間の相関がない場合。画像処理など。 | 変数間に相関がある場合。判別分析・異常検知・MT法など。 |
もし変数間の相関がゼロ(共分散 = 0)であれば、共分散行列は対角行列になり、マハラノビス距離は標準化ユークリッド距離と一致します。つまり、マハラノビス距離はユークリッド距離の「上位互換」と考えることができます。相関がない場合は自動的にユークリッド距離に戻るのです。
まとめ ── マハラノビス距離の本質
🔑 この記事のポイント
| 項目 | 内容 |
|---|---|
| マハラノビス距離とは | バラつき(分散)と相関(共分散)を考慮した「統計的な距離」 |
| なぜ必要か | ユークリッド距離はスケール・バラつき・相関の3つを無視するから |
| 幾何学的イメージ | 等距離面が「円」ではなく、データの散らばりに合わせた「楕円」になる |
| 公式の本質 | 1変量の「σ² で割る」を多変量に拡張 → 「Σ⁻¹ をかける」 |
| Σ⁻¹の役割 | ①分散で標準化 ②相関を除去 → 楕円を円に戻す変換 |
| 判別分析での使い方 | 各グループまでのマハラノビス距離を比較し、近い方に分類 |
マハラノビス距離は、一見すると行列演算が出てきて難しそうに見えます。しかし本質は「データの楕円の形を考慮して、本当の遠さを測る」というシンプルなアイデアです。
「身長180cmで体重40kgの人は異常値だ」── 私たちが直感的に感じるこの判断を、数式で正確に表現したものがマハラノビス距離なのです。
📚 次に読むべき記事
マハラノビス距離を使った判別分析の基本を、さらに詳しく解説しています。
判別分析・主成分分析・回帰分析……多変量解析の全体像を把握できます。
マハラノビス距離と深い関係がある主成分分析の全体像を視覚的に学べます。
マハラノビス距離の核心「共分散」の基礎を復習できます。
マハラノビス距離を使ったMT法の背景にあるタグチメソッドの全体像を学べます。
マハラノビス距離の「3σ離れている」の意味を正規分布から理解しましょう。
統計学全体の中でマハラノビス距離がどの位置にあるか、ロードマップで確認。
統計学のおすすめ書籍
統計学の「数式アレルギー」を治してくれた一冊
「Σ(シグマ)や ∫(インテグラル)を見ただけで眠くなる…」 そんな私を救ってくれたのが、小島寛之先生の『完全独習 統計学入門』です。
この本は、難しい記号を一切使いません。 「中学レベルの数学」と「日本語」だけで、検定や推定の本質を驚くほど分かりやすく解説してくれます。
「計算はソフトに任せるけど、統計の『こころ(意味)』だけはちゃんと理解したい」 そう願う学生やエンジニアにとって、これ以上の入門書はありません。

{kind=link}
【QC2級】「どこが出るか」がひと目で分かる!最短合格へのバイブル
私がQC検定2級に合格した際、使い倒したのがこの一冊です。
この本の最大の特徴は、「各単元の平均配点(何点分出るか)」が明記されていること。 「ここは出るから集中」「ここは出ないから流す」という戦略が立てやすく、最短ルートで合格ラインを突破できます。
解説が分かりやすいため、私はさらに上の「QC1級」を受験する際にも、基礎の確認用として辞書代わりに使っていました。 迷ったらまずはこれを選んでおけば間違いありません。
