- 偏回帰係数の符号がプラスのはずなのに、マイナスになっている…
- 標準誤差が異常に大きくて、有意にならない…
- 変数を1つ追加しただけで、他の係数が大きく変わってしまう…
- 多重共線性とは何か、なぜ問題なのか
- VIF(分散拡大係数)の意味と計算方法
- 多重共線性を検出したときの対処法
「重回帰分析をやってみたけど、結果がおかしい…」
そんな経験はありませんか?
たとえば、「広告費が増えると売上が増える」はずなのに、偏回帰係数がマイナスになっている。あるいは、明らかに重要な変数なのに、t検定で「有意でない」と判定されてしまう。
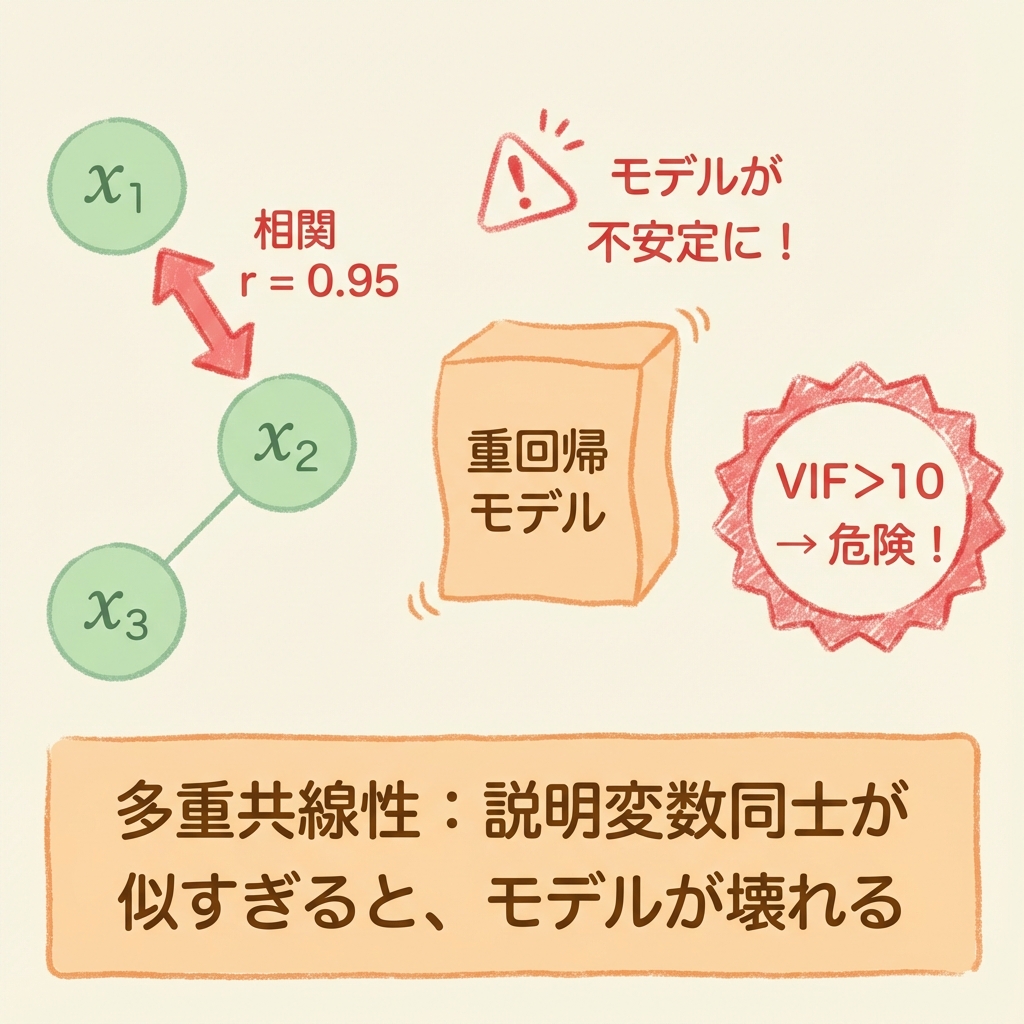
その原因、もしかすると「多重共線性」かもしれません。
多重共線性とは、説明変数同士が強く相関している状態のこと。これが起きると、重回帰分析の結果が不安定になり、正しい解釈ができなくなってしまいます。
この記事では、多重共線性の仕組みから検出方法(VIF)、対処法まで、図解でわかりやすく解説します。
多重共線性とは?
説明変数同士が「似すぎている」状態
多重共線性(Multicollinearity)とは、説明変数同士が強く相関している状態のことです。
たとえば、売上を予測するモデルで「広告費」と「マーケティング費」を両方入れたとします。
でも、よく考えてみてください。広告費とマーケティング費って、ほとんど同じものですよね。広告費が多い月はマーケティング費も多いし、少ない月は両方少ない。
このように、2つの変数が「似すぎている」と、重回帰分析はうまく機能しなくなります。
説明変数の間に強い線形関係(相関)があること。
極端な場合、ある変数が他の変数の線形結合で完全に表せる状態。
「双子」で考えるとわかりやすい
多重共線性のイメージを、双子の例で考えてみましょう。
あなたは「チームの売上」を予測したいと思っています。チームには太郎さんと次郎さんがいます。
ところが、太郎さんと次郎さんは一卵性双生児で、行動パターンがまったく同じ。太郎さんが頑張る日は次郎さんも頑張るし、太郎さんがサボる日は次郎さんもサボる。
この状態で、「売上への貢献は太郎さんのおかげ?次郎さんのおかげ?」と聞かれたら、答えられますか?
…答えられませんよね。2人の行動が似すぎていて、どちらの効果か区別できないからです。
多重共線性がない状態:チームメンバーがそれぞれ個性的 → 誰の貢献か区別できる
多重共線性がある状態:チームメンバーが双子ばかり → 誰の貢献か区別できない
説明変数が「似すぎている」と、それぞれの効果を分離できなくなるのです。


多重共線性があると何が起こる?
問題①:偏回帰係数が不安定になる
多重共線性があると、偏回帰係数がサンプルごとに大きく変動します。
たとえば、あるサンプルで計算すると b₁ = 5.0 だったのに、別のサンプルでは b₁ = −2.0 になる、ということが起こります。
これは、x₁とx₂が似すぎているため、「x₁の効果」と「x₂の効果」の配分がサンプルによってコロコロ変わってしまうからです。
本当の効果:「広告費 +5、マーケティング費 +3」(合計 +8)
多重共線性があると…
・サンプルA:「広告費 +10、マーケティング費 −2」(合計 +8)
・サンプルB:「広告費 −1、マーケティング費 +9」(合計 +8)
合計は同じでも、配分がバラバラになってしまう。
問題②:標準誤差が大きくなる
偏回帰係数が不安定ということは、標準誤差が大きくなるということです。
標準誤差が大きくなると、t値(= 係数 ÷ 標準誤差)が小さくなります。
その結果、本当は効いている変数なのに「有意でない」と判定されてしまうことがあります。
| 状態 | 標準誤差 | t値 | 判定 |
|---|---|---|---|
| 多重共線性なし | 小さい | 大きい | 有意になりやすい |
| 多重共線性あり | 大きい | 小さい | 有意にならない |
問題③:符号が逆転することがある
最も厄介なのが、偏回帰係数の符号が理論と逆になることです。
「広告費を増やすと売上が増える」のが常識なのに、偏回帰係数がマイナスになっている…。これは多重共線性の典型的な症状です。
なぜこんなことが起こるのでしょうか?
偏回帰係数は「他の変数を固定したときの効果」を表します。でも、x₁とx₂が強く相関していると、「x₁だけ変えてx₂を固定する」という状況が現実にはほとんど存在しないのです。
存在しない状況を無理やり推定するので、結果が不自然になってしまいます。
- 偏回帰係数がサンプルごとに大きく変動する
- 標準誤差が大きく、有意にならない
- 偏回帰係数の符号が理論と逆になる
これらの症状が見られたら、多重共線性を疑いましょう。


VIF(分散拡大係数)で多重共線性を検出する
VIFとは?|「分散がどれだけ膨らんだか」を測る指標
多重共線性を検出する最もポピュラーな指標がVIF(Variance Inflation Factor:分散拡大係数)です。
VIFは、「他の説明変数との相関によって、偏回帰係数の分散がどれだけ膨らんだか」を表す指標です。
VIF = 1 → 他の変数と全く相関なし(理想的)
VIF = 5 → 分散が5倍に膨らんでいる
VIF = 10 → 分散が10倍に膨らんでいる(危険)
VIFが大きいほど、その変数は他の変数と強く相関しており、偏回帰係数の推定が不安定になっています。
VIFの計算式
VIFは、各説明変数について計算します。
Rⱼ²:xⱼを他のすべての説明変数で回帰したときの決定係数
ちょっとわかりにくいので、具体的に説明しますね。
たとえば、x₁のVIFを計算したいとします。このとき、次のような回帰分析を行います。
- x₁を目的変数、x₂とx₃を説明変数として回帰分析
- その回帰分析の決定係数R₁²を求める
- VIF₁ = 1 ÷ (1 − R₁²) を計算
つまり、「x₁が他の説明変数(x₂, x₃)でどれだけ説明できるか」を調べているのです。
もしx₁がx₂やx₃で完全に説明できる(R₁² = 1)なら、VIF = 1 ÷ 0 = ∞ となり、多重共線性は完全に発生しています。
VIFの判定基準
VIFの判定基準は、一般的に以下のように言われています。
| VIFの値 | 判定 | 対応 |
|---|---|---|
| VIF < 5 | 問題なし | そのまま分析を続けてOK |
| 5 ≦ VIF < 10 | 要注意 | 多重共線性の可能性あり。結果の解釈に注意 |
| VIF ≧ 10 | 深刻な問題 | 多重共線性あり。対処が必要 |
VIF < 5 → 安全
VIF ≧ 10 → 危険
まずはこの2つの基準だけ覚えておけばOKです。


{kind=link}
【計算例】VIFを実際に求めてみよう
問題設定:3つの説明変数があるモデル
売上(y)を「広告費(x₁)」「マーケティング費(x₂)」「店舗面積(x₃)」で予測するモデルを考えます。
各説明変数を目的変数として、他の変数で回帰分析した結果、以下の決定係数が得られました。
VIFの計算
広告費(x₁)のVIF
マーケティング費(x₂)のVIF
店舗面積(x₃)のVIF
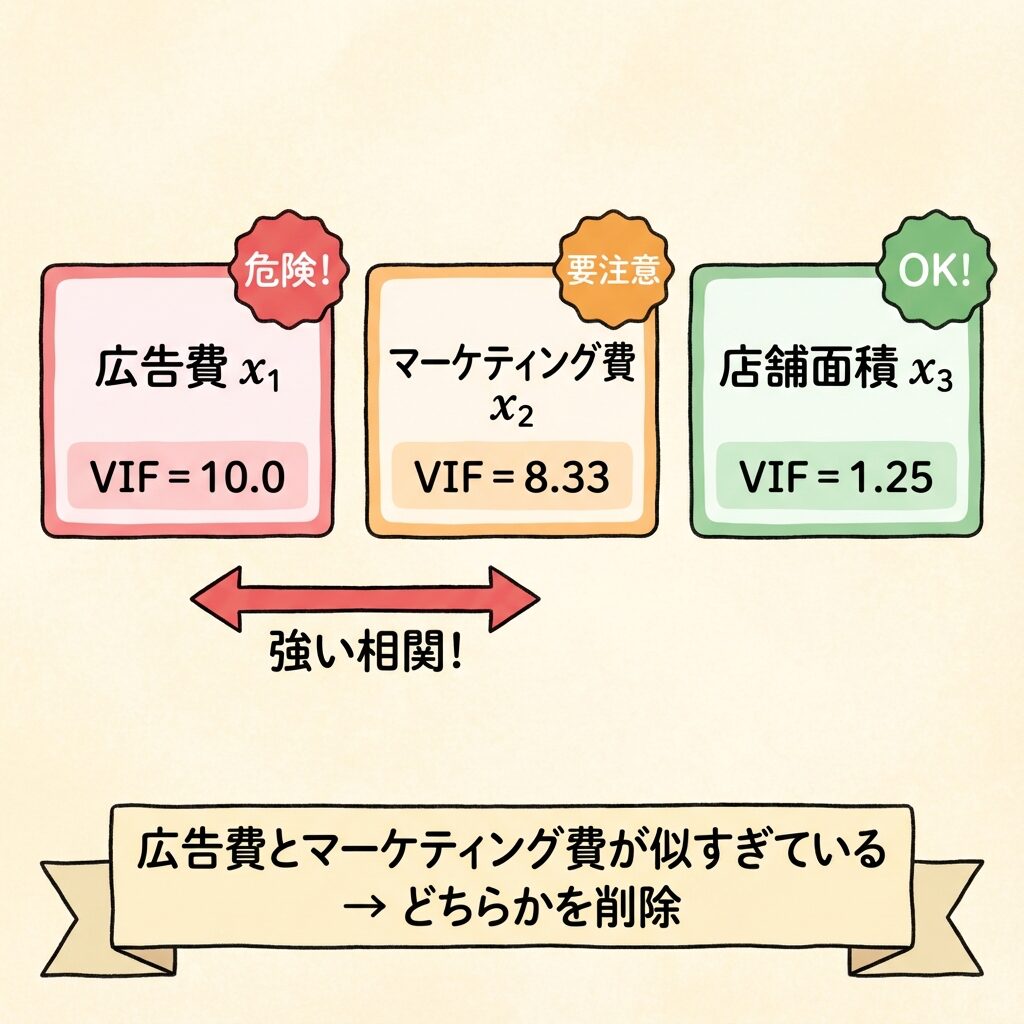
結果のまとめと判定
| 変数 | Rⱼ² | VIF | 判定 |
|---|---|---|---|
| 広告費 x₁ | 0.90 | 10.0 | 危険 🚨 |
| マーケティング費 x₂ | 0.88 | 8.33 | 要注意 ⚠️ |
| 店舗面積 x₃ | 0.20 | 1.25 | 問題なし ✓ |
広告費とマーケティング費の間に強い多重共線性が発生しています。
これは当然ですよね。広告費とマーケティング費は、概念的にほとんど同じものだからです。
このままでは、「広告費の効果」と「マーケティング費の効果」を正しく分離できません。対処が必要です。
多重共線性への対処法
対処法①:変数を削除する(最もシンプル)
最もシンプルな対処法は、相関の高い変数のどちらかを削除することです。
先ほどの例なら、「広告費」と「マーケティング費」のどちらかを削除します。どちらを残すかは、以下の観点で判断します。
- 理論的に重要な方を残す
- 測定精度が高い方を残す
- データの欠損が少ない方を残す
迷ったら、VIFが高い方を削除するのが無難です。
VIFが高い = 他の変数で説明できる = なくても情報が失われにくい、ということだからです。
対処法②:変数を統合する
相関の高い変数を1つの変数に統合する方法もあります。
先ほどの例なら、「広告費」と「マーケティング費」を足して「プロモーション費」という1つの変数にします。
変更前:y = b₀ + b₁(広告費) + b₂(マーケティング費) + b₃(店舗面積)
変更後:y = b₀ + b₁(プロモーション費) + b₂(店舗面積)
※プロモーション費 = 広告費 + マーケティング費
この方法なら、情報を捨てずに多重共線性を解消できます。ただし、「広告費」と「マーケティング費」の個別の効果はわからなくなります。
対処法③:主成分分析を使う
より高度な方法として、主成分分析(PCA)を使う方法があります。
主成分分析は、相関のある変数から「相関のない新しい変数(主成分)」を作り出す手法です。この主成分を説明変数として使えば、多重共線性は発生しません。
ただし、主成分は元の変数の「合成」なので、解釈が難しくなるというデメリットがあります。
対処法④:サンプルサイズを増やす
サンプルサイズを増やすと、標準誤差が小さくなり、多重共線性の影響を軽減できます。
ただし、これは「根本的な解決」ではなく「影響を和らげる」だけです。VIFが非常に高い場合(10以上)は、サンプルを増やしても問題が残ることがあります。
対処法のまとめ
| 対処法 | メリット | デメリット |
|---|---|---|
| ①変数を削除 | シンプル、確実 | 情報が失われる |
| ②変数を統合 | 情報を保持できる | 個別の効果がわからない |
| ③主成分分析 | 多くの変数に対応可 | 解釈が難しくなる |
| ④サンプル増加 | 変数を変えなくてよい | 根本的解決ではない |
まずは①変数を削除を検討しましょう。
シンプルで効果が確実、解釈も容易です。
削除したくない理由がある場合のみ、②〜④を検討します。
多重共線性チェックの流れ
- 重回帰分析を実行する
- 各変数のVIFを計算する
- VIF ≧ 10 の変数があるか確認
- あれば対処法を実施
- 再度VIFを確認(すべて VIF < 5 になるまで繰り返す)
まとめ
この記事では、多重共線性とVIFについて解説しました。
- 多重共線性:説明変数同士が強く相関している状態
- 多重共線性があると、係数が不安定・符号逆転・有意にならない
- VIFで検出。VIF ≧ 10 なら多重共線性あり
- 対処法は変数削除が最もシンプルで確実
多重共線性は、重回帰分析の「落とし穴」です。分析前にVIFをチェックする習慣をつけましょう。
次は、「どの変数をモデルに入れるべきか」を決める変数選択の方法について学びましょう。
📚 次に読むべき記事
最適な変数の組み合わせを見つける方法
偏回帰係数の信頼区間を求める方法
重回帰分析の基礎から復習したい方へ