
{kind=link}
- 点推定と区間推定の違いがイメージでわかる
- なぜビジネスでは「幅を持たせた予測」が重要なのか理解できる
- 95%信頼区間の意味がスッキリわかる
- 実務での正しい報告の仕方が身につく
データ分析の結果を上司やクライアントに報告するとき、あなたはどちらの言い方をしていますか?
「来月の売上予測は、
ズバリ 1,000万円 です!」
「来月の売上予測は、
950万〜1,050万円の間 です」
前者はカッコよく聞こえますが、外れるリスクが高いです。
後者は少し弱気に見えますが、情報の信頼性は高いです。
統計学の世界では、前者を「点推定」、後者を「区間推定」と呼びます。
今日は、この2つの推定方法の違いを、「モリで魚を突く」か「網で魚を掬う」かという例えでスッキリ理解しましょう。
目次
点推定:カッコいいけれど「嘘つき」になりやすい
点推定(Point Estimation)とは、母集団の値を「たった一つの数値(点)」で言い当てることです。
点推定の例
- 「全国の平均身長は 170.5cm だ」
- 「この部品の寿命は 5,000時間 だ」
- 「来月の売上は 1,000万円 だ」
「モリで魚を突く」イメージ
点推定は、「大海原にいる魚を、一本のモリで突き刺そうとする行為」に似ています。
手元のデータ(標本)から計算した平均値を、
そのまま「真の値」だと言い張ること。
真の値が「50.00001」だったとしても、
予想が「50」なら、数学的には「ハズレ(誤差あり)」になってしまいます。
ピンポイントで当てる確率は、実質ゼロに近いのです。
「平均は50です!」と言い切ることは、分かりやすい反面、「誤差を無視している」という点で、統計学的には少し不誠実(乱暴)な態度と言えます。

区間推定:曖昧だけど「誠実」なアプローチ
一方、区間推定(Interval Estimation)は、母集団の値が含まれるであろう「範囲」を提示します。
区間推定の例
- 「全国の平均身長は 169cm 〜 172cm の間 でしょう」
- 「この部品の寿命は 4,800時間 〜 5,200時間 の間 でしょう」
- 「来月の売上は 950万 〜 1,050万円 の間 でしょう」
「網で魚を掬う」イメージ
区間推定は、「魚がいそうな場所に、広めの網(あみ)を投げる行為」です。
モリで一点を突くよりも、
網でガバッと掬ったほうが、
魚(真の値)を捕まえられる確率は圧倒的に高いですよね。
統計学では、この「網の広さ」のことを「信頼区間(Confidence Interval)」と呼びます。
95%信頼区間とは?
もっともよく使われるのが「95%信頼区間」です。
「95%の確率で当たる大きさの網」を使って推定すること。
「平均値は 48〜52 の間です(信頼係数95%)」と言うことは、
「5%くらいは外すリスクがあるけど、
95%くらいの確率でこの範囲に真実があるよ」
という、リスクを開示した誠実な報告なのです。

点推定と区間推定を比較しよう
ここまでの内容を表にまとめます。
比較表
| 点推定 | 区間推定 | |
|---|---|---|
| イメージ | 🎯 モリで突く | 🥅 網で掬う |
| 予想の仕方 | 「ズバリ50です!」 | 「48〜52の間です」 |
| メリット | 分かりやすい 言い切りがカッコいい |
外れにくい リスクが見える |
| デメリット | 外れる確率が高い 誤差が見えない |
曖昧に見える インパクトが弱い |
| 使う場面 | ざっくり知りたい時 速報値 |
ビジネス判断 論文・報告書 |
ビジネスや研究では、一点張りで外すリスクを避けるために、
幅を持たせた「区間推定」がよく使われます。
「ズバリ〇〇です!」と言い切るのは気持ちいいですが、
外れた時のダメージも大きいですよね。

実務で「幅」を持たせる重要性
なぜ、エンジニアやデータサイエンティストは区間推定を好むのでしょうか?
それは、「最悪のケース」を想定できるからです。
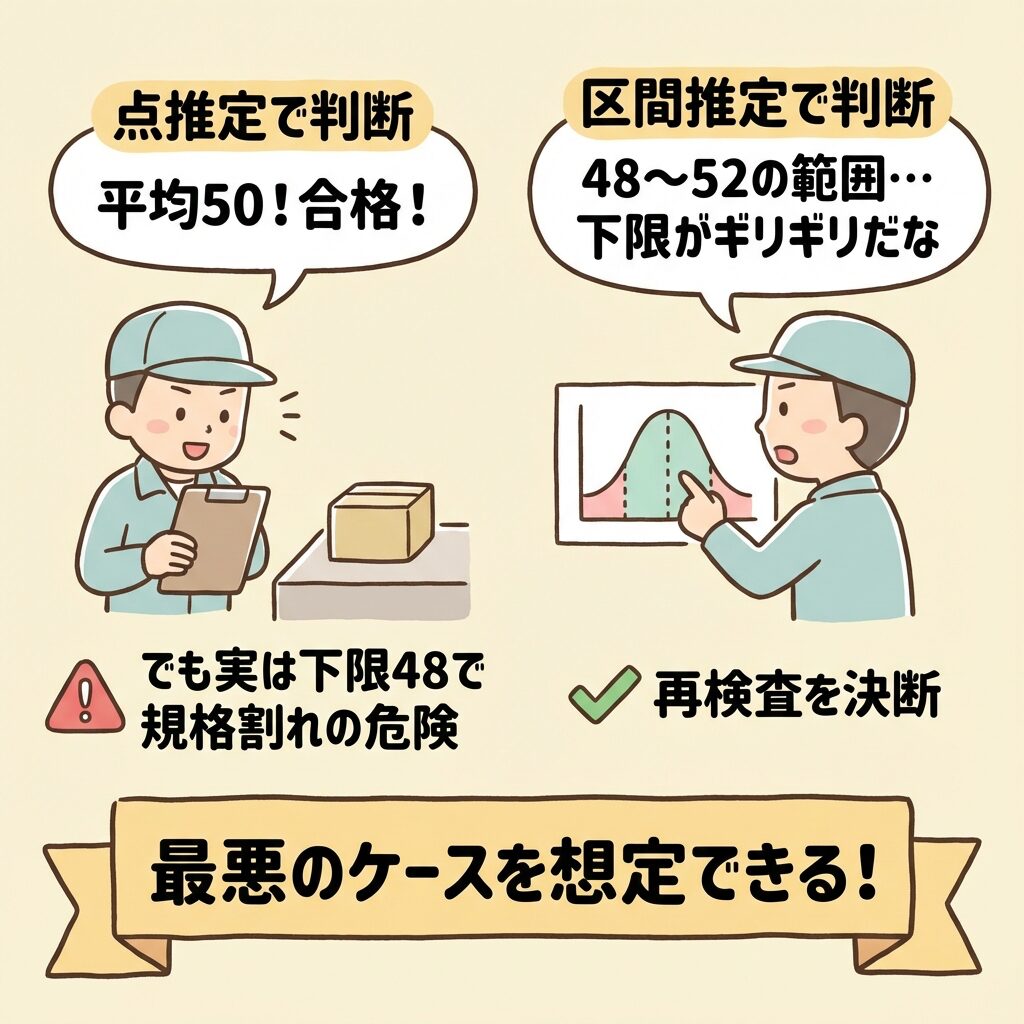
具体例:製品の強度検査
ある製品の強度が「規格:49以上」必要だとします。
判断:「お、規格(49)より上だな。ヨシ、合格!」
実はデータのバラつきが大きくて、真の平均が48である可能性が隠れているかもしれない。
(95%信頼区間)」
判断:「ん? 下限が 48 になる可能性があるのか。それだと規格(49)を割るリスクがあるな。再検査しよう」
最悪のケースが見えるので、リスク管理ができる!
幅(区間)を見ることで、ギリギリの判定やリスク管理ができるようになります。
これが「推測統計」の威力です。
実務での正しい報告の仕方
ここまで理解したら、実務での報告の仕方も変わってきます。
NG例とOK例を比較しよう
「平均は50です!
これで大丈夫です!」
「平均は50.5ですが、
誤差を含めると48.2〜52.8の範囲になりそうです」
ビジネスの現場では「結論ファーストでズバリ言え!」と求められることも多いですが、
データのプロとしては、
「ズバリ50ですが、誤差を含めると48〜52の範囲になりそうです」
と、必ず「幅」を添える癖をつけましょう。
その「幅」の中にこそ、
エンジニアとしての誠実さと、統計学的な正しさが詰まっているのです。
まとめ|「言い切る勇気」より「幅を持たせる知性」を
🎯 モリで魚を突く
分かりやすいが、外れるリスクが見えない
🥅 網で魚を掬う
少し曖昧だが、リスクが見える化される
ビジネス判断・論文・報告書では区間推定が基本。
「幅」を添えることで、誠実さと正しさを両立。
次に学ぶべきこと
検定・推定の基礎概念はこれで完璧です!
次は、実際に「どの検定を使えばいいのか?」を学びましょう。
t検定、F検定、カイ二乗検定…種類が多くて迷いますよね。
でも、3つの質問に答えるだけで、使うべき検定が一発でわかるフローチャートがあります。
💪 ここまで読んでくださった方へ
「点推定」と「区間推定」の違い、
「モリ」と「網」のイメージで覚えられましたね!
これで検定・推定の基礎概念は完璧です。
次は具体的な検定手法を学んで、
実務で使えるスキルを身につけましょう!