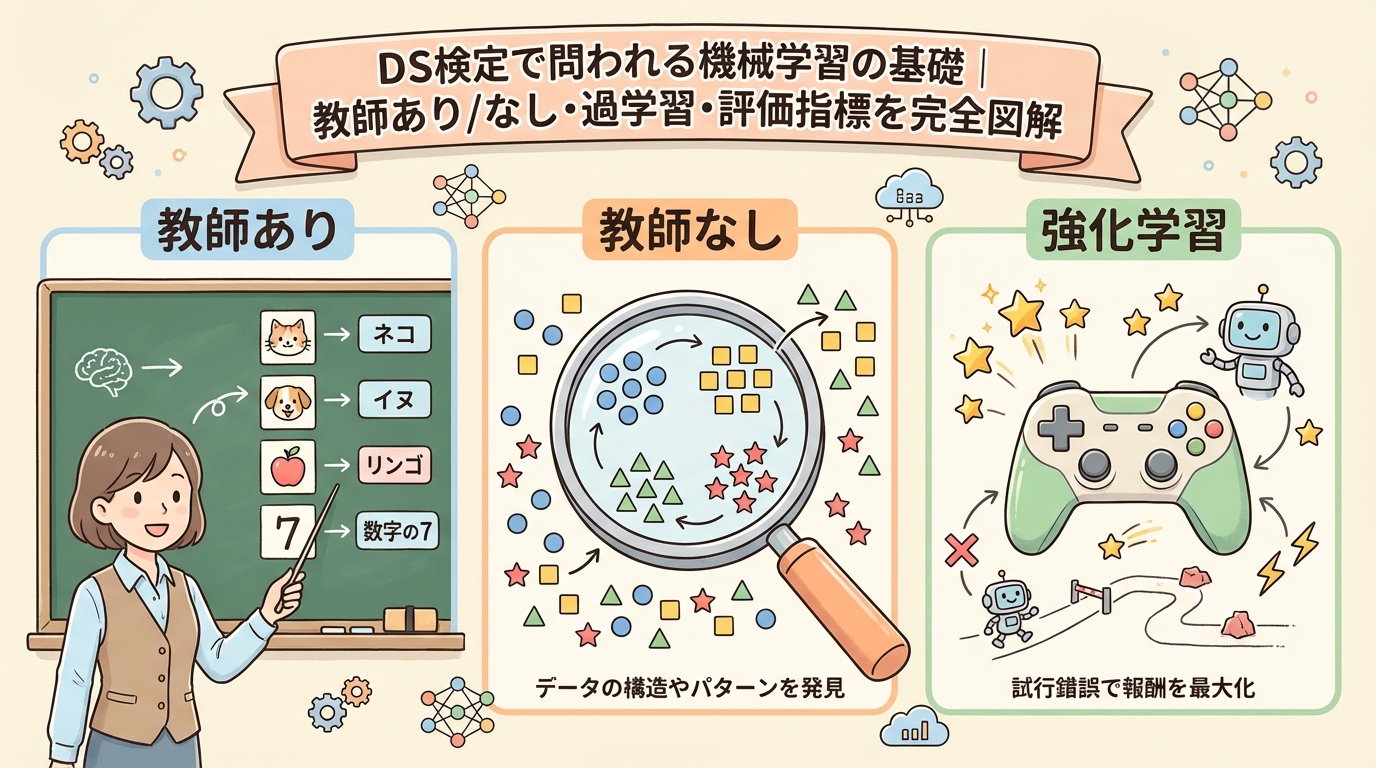
- 「教師あり学習」「教師なし学習」って、何が"教師"なの?
- 「過学習」がヤバいのは知ってるけど、なぜ起きるのか説明できない
- 「精度」「再現率」「F値」「AUC」…似たような指標が多すぎて混乱する
- DS検定の勉強を始めたけど、機械学習の範囲が広すぎてどこから手をつけるべきかわからない
- 機械学習の「3つの学習タイプ」と代表的アルゴリズム一覧
- 回帰と分類の違い(教師あり学習の2大タスク)
- 過学習がなぜ起きるのか&正則化でどう防ぐのか
- 混同行列・精度・再現率・適合率・F値・AUCの意味と使い分け
- DS検定で問われるポイントの整理
機械学習は、DS検定(データサイエンティスト検定)の最頻出テーマです。出題範囲が広く、用語も多いため「何から覚えればいいのかわからない」と感じる方が非常に多い分野でもあります。
しかし安心してください。機械学習の基礎は、身近なたとえ話でイメージをつかめば、一気に理解が進みます。この記事では、数式をほとんど使わずに「なぜそうなるのか」を徹底的に図解します。最後まで読めば、DS検定の機械学習パートに自信を持って臨めるようになります。
目次
- そもそも「機械学習」とは何か?
- 機械学習の「3つの学習タイプ」全体像
- 教師あり学習とは?|「答え付きの問題集」で学ぶ
- 教師あり学習の代表的アルゴリズム一覧
- 教師なし学習とは?|「答えなしで自力でグループ分け」する
- 強化学習とは?|「ゲームをプレイして上手くなる」AI
- 訓練データとテストデータ|なぜデータを「分ける」のか?
- 過学習(オーバーフィッティング)とは?
- 過学習を防ぐ5つの対策
- バイアスとバリアンスのトレードオフ
- 評価指標の基礎|混同行列(Confusion Matrix)を理解する
- 精度・適合率・再現率|3つの評価指標を完全理解
- F値(F1スコア)|適合率と再現率の「バランス指標」
- ROC曲線とAUC|モデルの「総合力」を1つの数値で表す
- 回帰の評価指標|MSE・RMSE・MAE・R²
- 評価指標の全体まとめ|分類と回帰の使い分けマップ
- DS検定で問われる機械学習の出題パターンまとめ
そもそも「機械学習」とは何か?
機械学習とは、データからパターンやルールを自動的に学習し、未知のデータに対して予測や判断を行う技術です。人間がルールを一つひとつプログラムするのではなく、大量のデータを渡して「自分でルールを見つけなさい」とコンピュータに任せるアプローチです。
従来のプログラミングは「レシピ本を見て作る料理」です。醤油大さじ2、みりん大さじ1…と人間がルールを書きます。
一方、機械学習は「100回食べた経験から、自分で味付けの法則を見つける」やり方です。甘いと好評だったデータ、しょっぱすぎて不評だったデータ…大量の「経験データ」を与えると、コンピュータが「砂糖はこのくらい、塩はこのくらいが最適」というルールを自分で導き出します。
従来のプログラミング
人間がルールを書く
→ コンピュータが実行
「IF 気温 > 30℃ THEN エアコンON」
機械学習
データを渡す
→ コンピュータがルールを発見
「過去1万件のデータから最適な基準を学ぶ」
この「データからルールを見つける方法」には大きく3つのタイプがあります。次のセクションから、それぞれを詳しく見ていきましょう。


機械学習の「3つの学習タイプ」全体像
機械学習のアルゴリズムは、データの与え方(正解を教えるかどうか)によって3つに分類されます。DS検定では「この手法はどのタイプに属するか?」という問い方が頻出なので、まずは全体像を押さえましょう。
| 学習タイプ | 正解ラベル | たとえ話 | 代表的な用途 |
|---|---|---|---|
| 教師あり学習 | あり ✅ | 答え付きの問題集で勉強する | 売上予測、メール分類(スパム判定) |
| 教師なし学習 | なし ❌ | 答えなしで「似た者同士」を自力でグループ分け | 顧客セグメント、異常検知 |
| 強化学習 | なし(報酬あり)🏆 | ゲームをプレイして「高スコア」を目指す | ロボット制御、囲碁AI、自動運転 |
DS検定では「教師あり学習」と「教師なし学習」が圧倒的に出題されます。強化学習は「概念を知っている」レベルで十分です。この記事でも教師あり・教師なしを中心に解説します。

教師あり学習とは?|「答え付きの問題集」で学ぶ
教師あり学習(Supervised Learning)は、「入力データ」と「正解ラベル(答え)」のペアを大量に与えて、入力から正解を予測するルールを学ばせる方法です。
英単語帳には「apple → りんご」「dog → 犬」と、問題と答えがセットになっています。何百回も繰り返し勉強すると、見たことのない単語でも「この綴りのパターンはこういう意味だろう」と推測できるようになる。これが教師あり学習です。
「教師」とは、正解ラベルのことです。先生が「これが正解だよ」と教えてくれるから「教師あり」なのです。
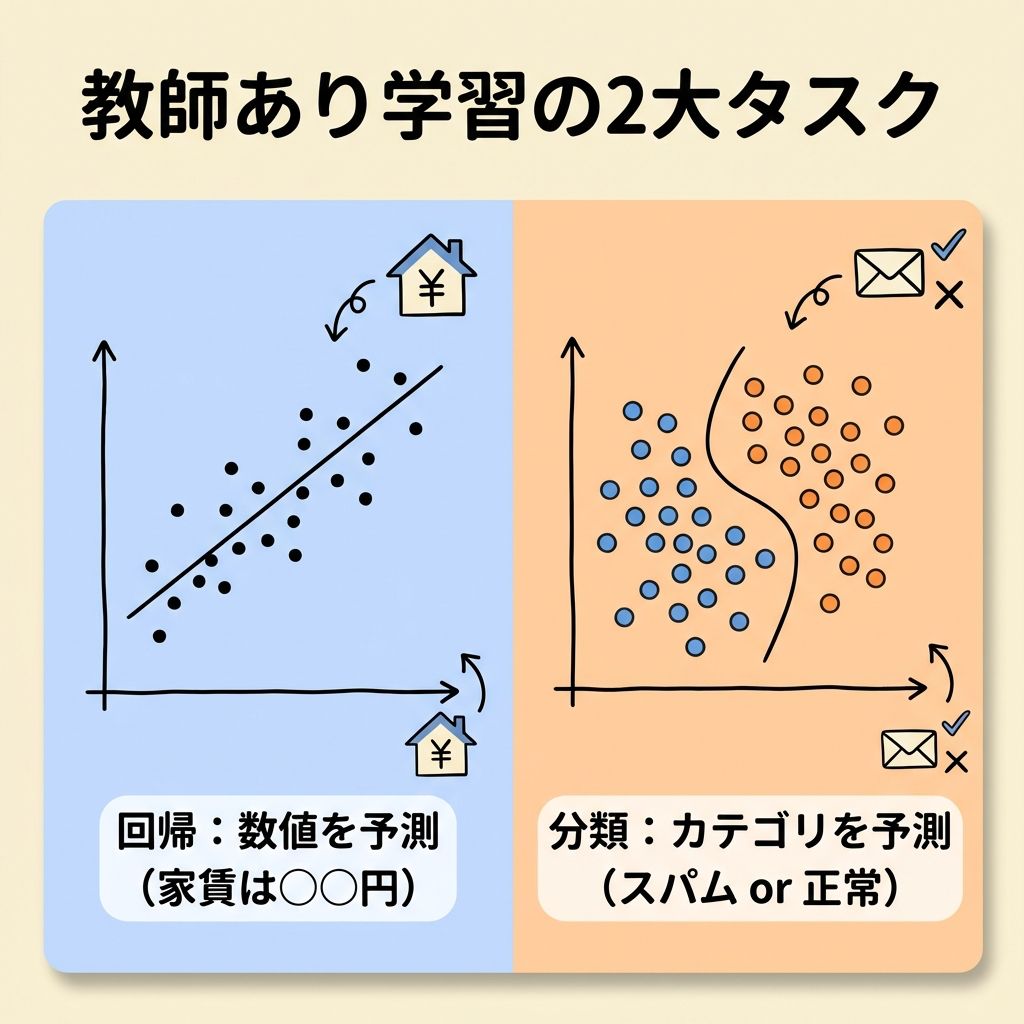
教師あり学習には、大きく2つのタスクがあります。「回帰」と「分類」です。
回帰(Regression):数値を予測する
回帰は、連続的な数値を予測するタスクです。「明日の気温は何度?」「この家の価格はいくら?」のように、答えが数字になるものが回帰です。
入力:部屋の広さ(㎡)、駅からの距離(分)、築年数
出力(予測値):家賃 85,000円(連続値)
分類(Classification):カテゴリを予測する
分類は、どのカテゴリに属するかを予測するタスクです。「このメールはスパムか、正常か?」「この画像は犬か、猫か?」のように、答えがラベル(カテゴリ名)になるものが分類です。
入力:メールの件名、本文のキーワード、送信元
出力(予測ラベル):スパム or 正常(カテゴリ)
回帰(Regression)
答えが数値
例:気温、売上、株価、家賃
分類(Classification)
答えがカテゴリ
例:スパム/正常、犬/猫、合格/不合格
「以下のうち、回帰タスクに該当するものはどれか?」のように、具体的な課題を見て回帰か分類かを判断させる問題が出ます。「答えが数値なら回帰、カテゴリなら分類」と覚えておけばOKです。

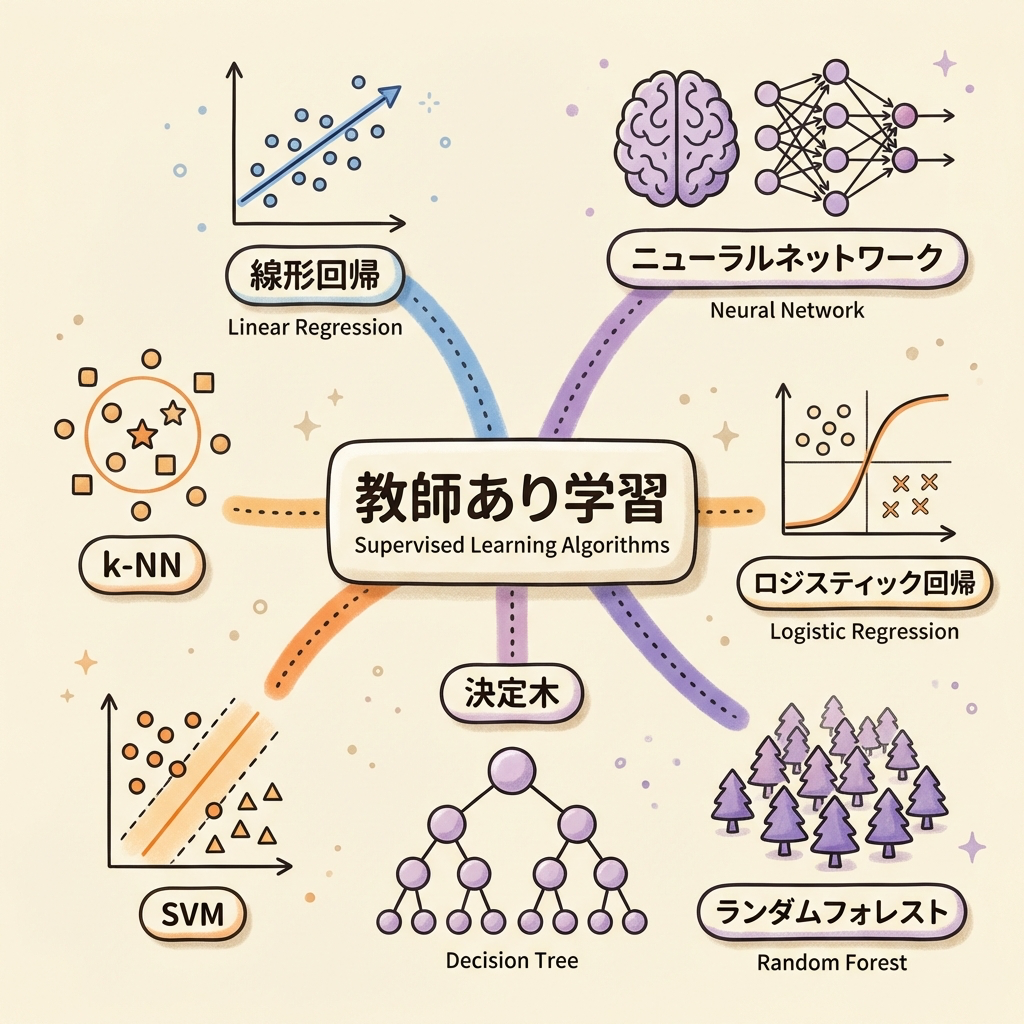
教師あり学習の代表的アルゴリズム一覧
DS検定では、「このアルゴリズムは回帰か?分類か?」「どんな特徴があるか?」が問われます。すべてを深く理解する必要はありませんが、名前・タスクの種類・ひとこと特徴は押さえておきましょう。
| アルゴリズム名 | 回帰 | 分類 | ひとこと特徴(たとえ話) |
|---|---|---|---|
| 線形回帰 | ✅ | − | データに「まっすぐな線」を引いて予測する最もシンプルな手法 |
| ロジスティック回帰 | − | ✅ | 名前に「回帰」とあるが分類の手法。確率で0/1を判定する |
| 決定木 | ✅ | ✅ | 「はい/いいえ」の質問を繰り返して答えにたどり着く「アキネイター」方式 |
| ランダムフォレスト | ✅ | ✅ | 決定木を大量に作り、多数決で答えを決める「集合知」方式 |
| 勾配ブースティング (XGBoost, LightGBMなど) |
✅ | ✅ | 弱い木を順番に育て、前の木の「間違い」を次の木が修正する「リレー」方式 |
| サポートベクターマシン (SVM) |
✅ | ✅ | 2つのグループの間にできるだけ幅の広い境界線を引く手法 |
| k-NN(k近傍法) | ✅ | ✅ | 「近くにいる仲間」を見て多数決で判定する「類は友を呼ぶ」方式 |
| ニューラルネットワーク (ディープラーニング) |
✅ | ✅ | 人間の脳の神経回路を模倣。画像認識・自然言語処理で圧倒的な性能 |
| ナイーブベイズ | − | ✅ | ベイズの定理を使って「この特徴ならAの確率が高い」と判定。スパムフィルタで有名 |
名前に「回帰」とあるため回帰タスクと勘違いしやすいですが、ロジスティック回帰は分類のアルゴリズムです。DS検定ではこの点がひっかけで出題されることがあるので注意してください。
教師なし学習とは?|「答えなしで自力でグループ分け」する
教師なし学習(Unsupervised Learning)は、正解ラベルが存在しないデータから、データの構造やパターンを発見する方法です。
あなたが転校初日に全校集会に出たとします。名簿もないし、誰が何年何組かも知りません。
でも、会場をよく見ると「この辺りの子たちは背が高くて制服のリボンが赤い」「あっちのグループは小柄で青いリボン」と、自然にグループが見えてくる。誰にも教えてもらわなくても、データ(見た目の特徴)だけでグループの構造を発見する。これが教師なし学習です。
教師なし学習の代表的タスク
| タスク名 | やること | 代表的手法 | 活用例 |
|---|---|---|---|
| クラスタリング | 似たデータをグループに分ける | k-means法 階層的クラスタリング DBSCAN |
顧客セグメント分析 似た購買パターンの発見 |
| 次元削減 | 多くの特徴量を少数に要約する | 主成分分析(PCA) t-SNE |
データの可視化 前処理(ノイズ除去) |
| アソシエーション分析 | 「AとBは一緒に買われやすい」などの関連ルールを発見 | Aprioriアルゴリズム | ECサイトの「この商品を買った人はこちらも」 |
k-means法のイメージ|最もメジャーなクラスタリング
k-means法は、データをk個のグループ(クラスタ)に分ける手法です。以下のステップを繰り返します。
適当な場所にk個の「中心点」を置く(最初はランダム)
各データを最も近い中心点のグループに割り当てる
各グループの平均位置に中心点を移動する
STEP 2〜3を中心点が動かなくなるまで繰り返す
町に3つのピザ屋を出したいとします。最初は適当な場所に置きます。次に、各住民が「一番近いピザ屋」に行くとして、お客さんの平均位置にピザ屋を移動させます。これを繰り返すと、3つのピザ屋が町中のお客さんを効率よくカバーできる場所に落ち着きます。これがk-means法のイメージです。

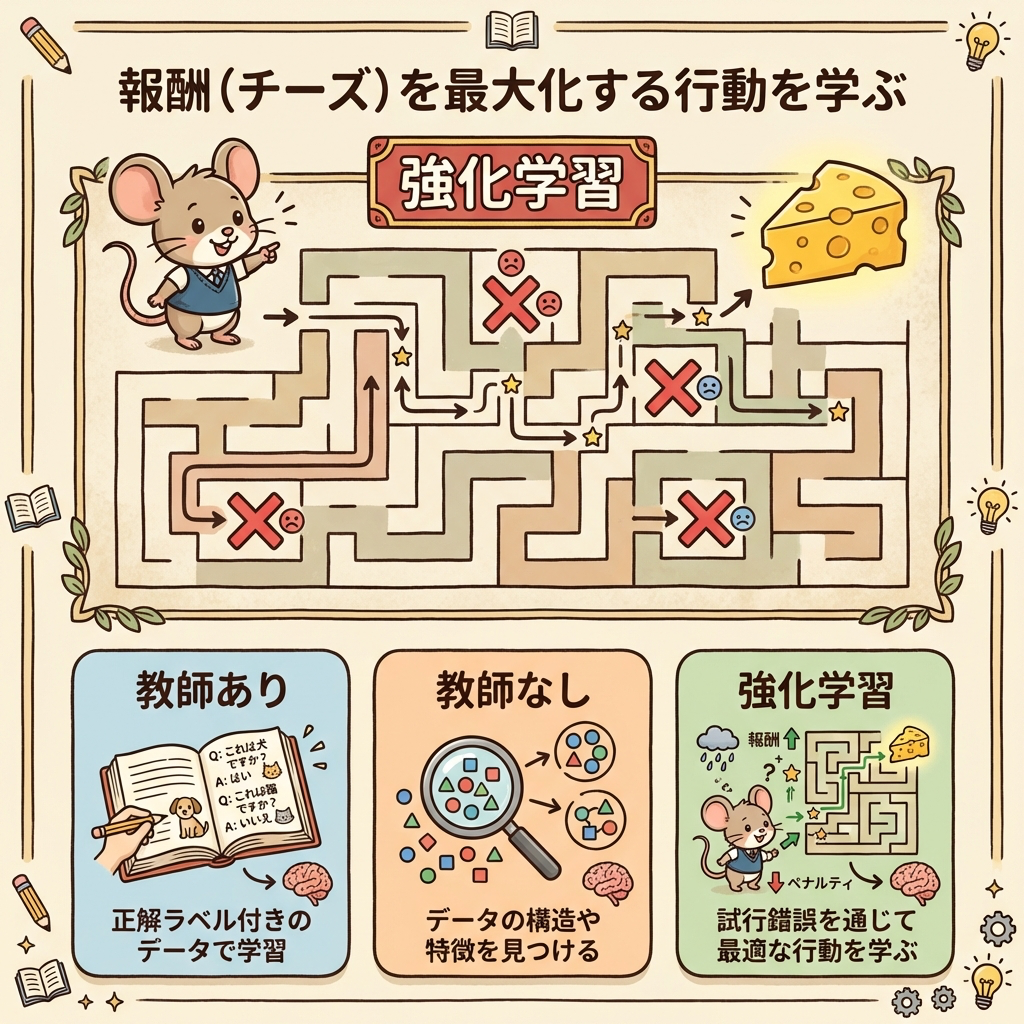
強化学習とは?|「ゲームをプレイして上手くなる」AI
強化学習(Reinforcement Learning)は、「行動」→「報酬(or ペナルティ)」のフィードバックを繰り返しながら、最も報酬が大きくなる行動パターンを学ぶ方法です。
ネズミが迷路に入ります。ゴールにたどり着くとチーズ(報酬)がもらえ、行き止まりに入ると時間を浪費します(ペナルティ)。何百回もトライするうちに、ネズミは「右→左→まっすぐ」が最短ルートだと学びます。
正解の道順を最初から教えてもらうのではなく、試行錯誤の結果(報酬)から学ぶのが強化学習の特徴です。
代表的な応用例としては、囲碁AI「AlphaGo」、ロボットの歩行制御、自動運転の意思決定などがあります。DS検定では「強化学習は報酬を最大化するために学習する」という概念を知っていれば十分です。
3つの学習タイプを1枚で整理
教師あり学習
正解あり
→ 予測(回帰・分類)
英単語帳で勉強
教師なし学習
正解なし
→ 構造発見(クラスタリング・次元削減)
知らない学校で自力グループ分け
強化学習
報酬あり
→ 最適行動の学習
迷路を何百回もやり直すネズミ

訓練データとテストデータ|なぜデータを「分ける」のか?
機械学習では、手元のデータを「訓練データ(学習用)」と「テストデータ(評価用)」に分けて使います。これは過学習(後述)を防ぐための最も基本的な考え方です。
受験勉強で、過去問を100年分持っているとします。この100年分すべてを暗記して「完璧!」と思っても、本番の試験で初見の問題が出たら解けません。
だから賢い受験生は、過去問のうち80年分で勉強し、残り20年分は「模擬試験」として取っておく。模試で良い点が取れれば、本番でも通用する実力がついたと判断できます。
機械学習でも同じです。データの80%で学習し(訓練データ)、残り20%で「本当に実力があるか」を確認する(テストデータ)のです。
交差検証(クロスバリデーション)という発展テクニック
データを1回だけ分割すると、「たまたま分け方が良かった(悪かった)」だけの可能性があります。そこで使われるのがk分割交差検証(k-fold Cross Validation)です。
データをk個に分割し、「1個をテスト、残りk-1個を訓練」の組み合わせをk回繰り返す方法です。k回の評価結果を平均することで、偏りのない安定した評価が得られます。
データを5つに分割(A, B, C, D, E)
1回目:テスト=A、訓練=BCDE
2回目:テスト=B、訓練=ACDE
3回目:テスト=C、訓練=ABDE
4回目:テスト=D、訓練=ABCE
5回目:テスト=E、訓練=ABCD
→ 5回の評価スコアの平均を最終スコアとする
「交差検証の目的は何か?」「k分割交差検証でk=5のとき、何回学習を行うか?」といった基本問題が頻出です。答えは「汎化性能の安定した評価」「k回(=5回)」です。

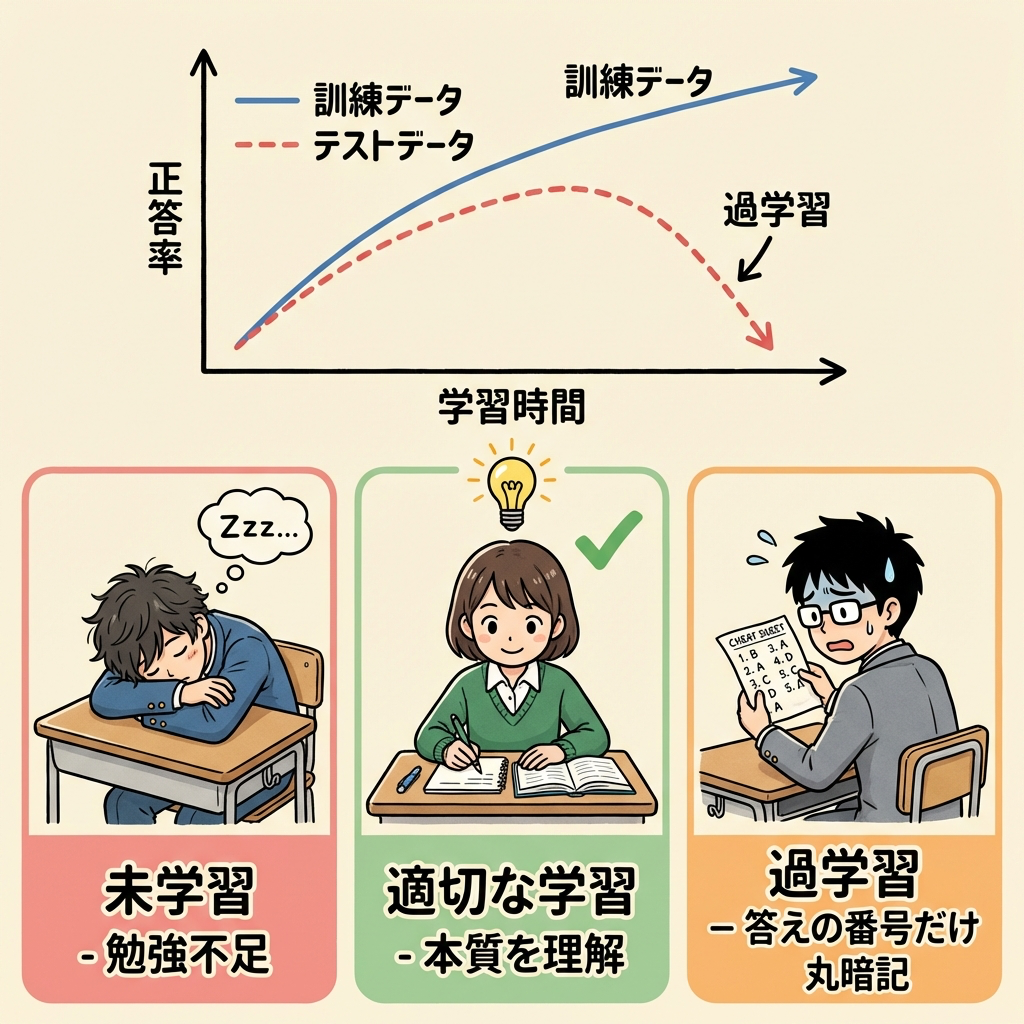
過学習(オーバーフィッティング)とは?
過学習とは、モデルが訓練データに「過剰に適合」してしまい、未知のデータに対する予測精度が悪くなる現象です。機械学習で最も重要な概念の一つであり、DS検定でも確実に出題されます。
ある受験生が過去問の答えの番号だけを丸暗記しました。「2024年の問1は③、問2は①…」。過去問テストは満点です。しかし、本番の試験では問題が変わるので惨敗します。
この受験生は「過去問の"ノイズ"(たまたまの出題パターン)」まで覚えてしまい、「本質的な理解」ができていなかったのです。
過学習とは、まさにこの「丸暗記」状態です。訓練データ上では優秀なのに、初見のテストデータではボロボロになります。
過学習と未学習(アンダーフィッティング)の比較
過学習の反対が未学習(アンダーフィッティング)です。モデルが単純すぎてデータのパターンすら捉えられていない状態です。
未学習(アンダーフィッティング)
モデルが単純すぎる
訓練データもテストデータも精度が低い
例え:教科書を1ページも読まず受験
ちょうどよい学習(適合)
モデルの複雑さが適切
訓練もテストも高精度
例え:本質を理解して応用が利く
過学習(オーバーフィッティング)
モデルが複雑すぎる
訓練データだけ高精度、テストは低精度
例え:答えの番号だけ丸暗記
過学習が起きる主な原因
| 原因 | 説明 |
|---|---|
| モデルが複雑すぎる | パラメータ数が多すぎると、ノイズまで「覚えて」しまう |
| 訓練データが少なすぎる | データが少ないと偏りをそのまま学習する |
| 学習回数(エポック)が多すぎる | 同じデータで学習しすぎると丸暗記状態になる |
| 特徴量が多すぎる | 不要な情報まで入れると、無関係なパターンを拾ってしまう |

過学習を防ぐ5つの対策
過学習を防ぐ方法はいくつかありますが、DS検定で問われる代表的な対策を5つ紹介します。
① 正則化(Regularization)|最重要の対策
正則化とは、モデルのパラメータ(重み)が大きくなりすぎるのにペナルティを課す手法です。モデルが複雑になろうとするのを「待った!」とブレーキをかけるイメージです。
旅行に荷物を無制限に持っていけると、「念のため」でスーツケース5個になります(過学習)。でも「LCCの荷物7kgまで」と制限があると、本当に必要なものだけを厳選する。正則化はこの「荷物制限」です。モデルに「重みの合計が大きくなるとペナルティをかけるよ」と伝えることで、本当に重要なパラメータだけを残します。
| 手法名 | 別名 | 特徴 |
|---|---|---|
| L1正則化 | Lasso回帰 | 重みの絶対値の合計にペナルティ。不要な特徴量の重みを完全にゼロにする(スパース化) |
| L2正則化 | Ridge回帰 | 重みの二乗の合計にペナルティ。すべての重みをまんべんなく小さくする |
| Elastic Net | − | L1とL2のハイブリッド |
「L1正則化(Lasso)は特徴量選択の効果がある」「L2正則化(Ridge)は重みを小さくするが、ゼロにはしない」。この違いは頻出です。
覚え方:L1 = 「1つずつ削除」(ゼロにする)、L2 = 「均等にならす」(小さくする)
② 早期終了(Early Stopping)
学習を進めると、ある時点から訓練データの精度は上がり続けるのに、テストデータの精度は下がり始めるポイントが来ます。このタイミングで学習を打ち切るのが早期終了です。
パスタの茹で時間が7分のとき、6分だと硬すぎ(未学習)、7分でちょうどいい(適合)、10分だとドロドロ(過学習)。ちょうどいいタイミングで火を止めるのが早期終了です。
③ ドロップアウト(Dropout)
主にニューラルネットワークで使われる手法です。学習中にランダムにニューロン(計算ユニット)を無効化することで、特定のニューロンに依存しない「頑健な」モデルを作ります。
サッカーの練習で、毎回エースストライカーだけにパスを出すと、エースが怪我したときにチームが崩壊します。練習中にランダムに選手を「お休み」させれば、全員がバランスよく上手くなる。ドロップアウトはこの考え方です。
④ データを増やす
最もシンプルかつ効果的な対策です。訓練データの量が多いほど、ノイズに引きずられにくくなります。画像の場合は、反転・回転・拡大縮小でデータを水増しするデータ拡張(Data Augmentation)も有効です。
⑤ 特徴量選択・次元削減
不要な特徴量(列)を減らすことも過学習対策になります。特徴量が多すぎると、無関係なパターンを拾いやすくなるためです。主成分分析(PCA)などの次元削減手法が使われます。

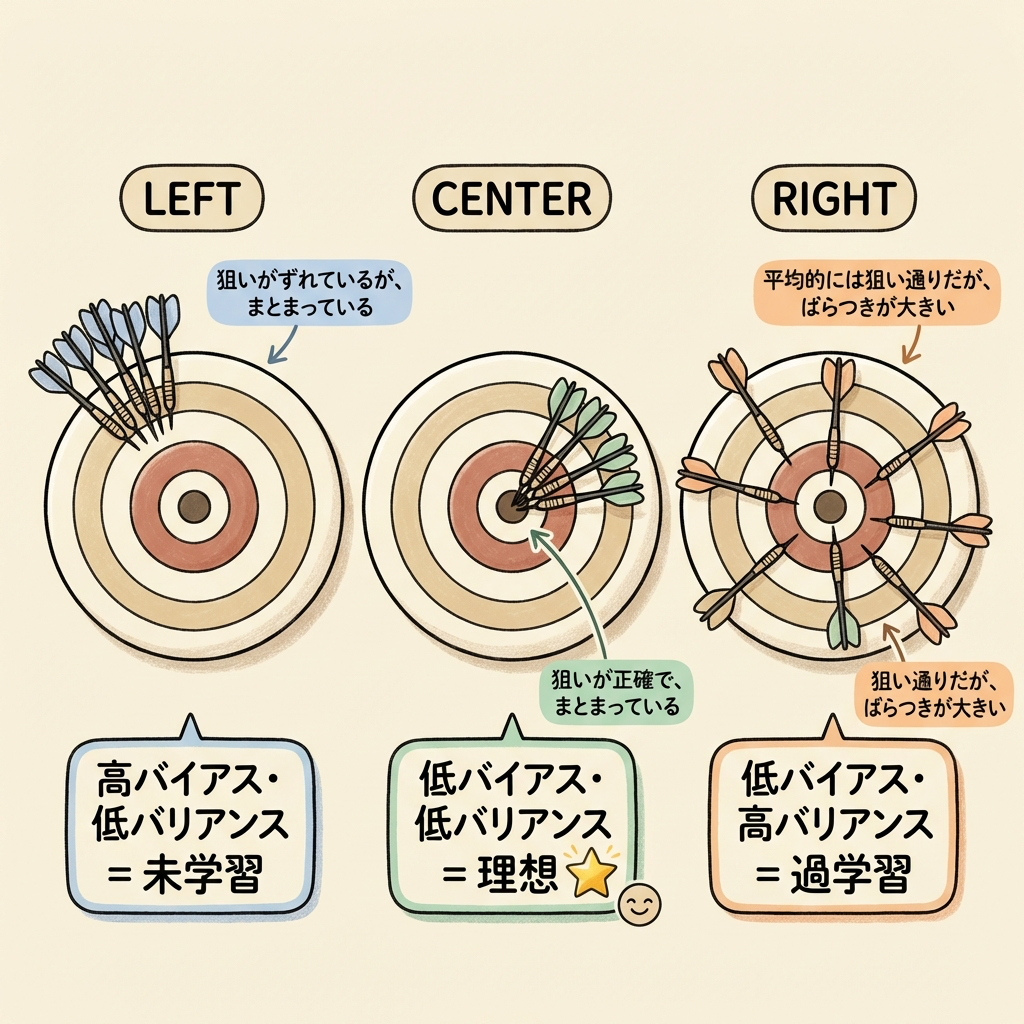
バイアスとバリアンスのトレードオフ
過学習と未学習の関係を理論的に説明するのが「バイアス-バリアンス・トレードオフ」です。DS検定で概念を問われることがあるので、イメージだけ押さえておきましょう。
ダーツの的に何回も投げるとします。
バイアス(偏り):的の中心からどれだけ「ズレ」ているか。常に左上に飛ぶ人はバイアスが大きい。
バリアンス(散らばり):投げるたびにどれだけ「バラつく」か。毎回あちこちに飛ぶ人はバリアンスが大きい。
高バイアス・低バリアンス
毎回同じ場所にまとまるが
中心からズレている
= 未学習(単純すぎるモデル)
低バイアス・低バリアンス
毎回中心付近に
まとまっている
= 理想的なモデル
低バイアス・高バリアンス
平均すると中心だが
毎回バラバラ
= 過学習(複雑すぎるモデル)
バイアスを下げようとモデルを複雑にするとバリアンスが上がり、バリアンスを下げようとモデルを単純にするとバイアスが上がります。この「あちらを立てればこちらが立たず」の関係がトレードオフです。最適なモデルは、両者のバランスが取れたポイントにあります。
評価指標の基礎|混同行列(Confusion Matrix)を理解する
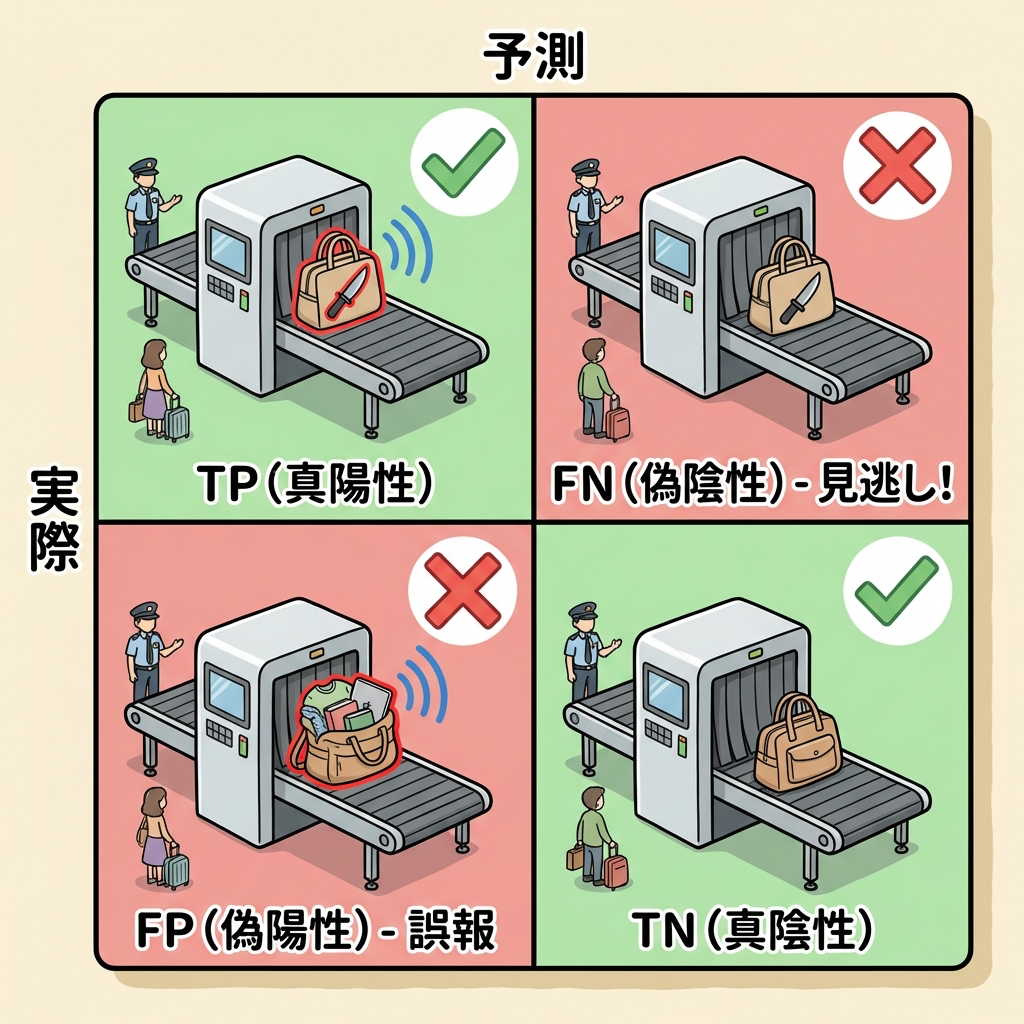
ここからは「分類モデル」の評価指標を解説します。すべての指標の出発点が混同行列です。まずはこの4つのマス目を完璧に理解しましょう。
空港の手荷物検査は「危険物かどうか」を判定するシステムです。検査結果は4パターンに分かれます。
① 本当に危険物を検査が「危険物」と判定 → 正しい!(TP)
② 安全な荷物を検査が「安全」と判定 → 正しい!(TN)
③ 安全な荷物を検査が「危険物」と判定 → 誤報(FP)
④ 本当に危険物を検査が「安全」と判定 → 見逃し!(FN)
③は「お客さんに迷惑をかける」程度ですが、④は「テロリストを通してしまう」最悪の事態です。どのミスが致命的かはシーンによって異なります。
混同行列の4つのマス目
| モデルの予測 | |||
|---|---|---|---|
| 陽性と予測 | 陰性と予測 | ||
| 実際の正解 | 実際に陽性 | TP (True Positive) 正しく陽性と判定 |
FN (False Negative) 陽性を見逃した |
| 実際に陰性 | FP (False Positive) 誤って陽性と判定 |
TN (True Negative) 正しく陰性と判定 |
|
1文字目(T or F):予測が合っていたか(True)、間違っていたか(False)
2文字目(P or N):モデルが何と「予測したか」(Positive / Negative)
例:FP(False Positive)= 予測は間違い(False)で、モデルは陽性と言った(Positive)= 「嘘の陽性」= 誤報
精度・適合率・再現率|3つの評価指標を完全理解
混同行列の4つのマス目から、いくつかの評価指標(メトリクス)を計算します。DS検定で特に重要な3つを紹介します。
① 正解率(Accuracy)|全体の中で正しく判定した割合
最もシンプルな指標で、「全体の中で正しく判定できたものの割合」です。しかし、データの偏り(不均衡データ)があると使い物にならないことがあります。
例えば、1000通のメールのうちスパムが10通しかない場合、全部「正常」と答えるだけで正解率99%になります。でもスパムは1通も検出できていません。
このように「陽性が極端に少ない」データでは、正解率は無意味になります。そこで登場するのが適合率と再現率です。
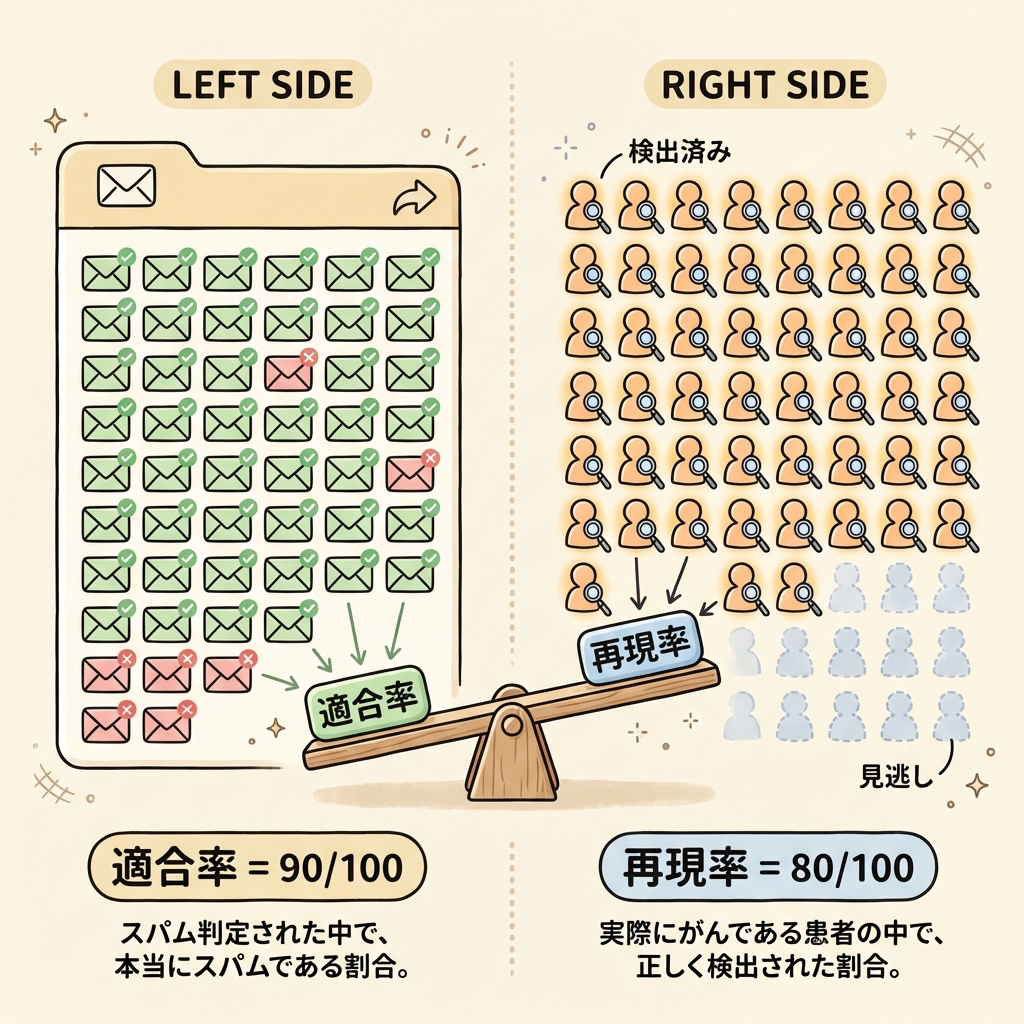
② 適合率(Precision)|「陽性と言ったもの」の中で本当に陽性だった割合
あなたのメールアプリが「これはスパム!」と100通をスパムフォルダに入れました。中を確認すると、本当にスパムだったのは90通で、10通は大事な仕事のメールでした。
適合率 = 90 / 100 = 90%
適合率は「陽性と判定したものの信頼度」を測ります。誤報(FP)が多いと適合率が下がります。
③ 再現率(Recall)|「実際に陽性のもの」の中でどれだけ拾えたか
実際にがん患者が100人いたとします。検査で「がんの疑いあり」と判定されたのは80人でした。残り20人は「問題なし」と判定されて見逃されました。
再現率 = 80 / 100 = 80%
再現率は「取りこぼしの少なさ」を測ります。見逃し(FN)が多いと再現率が下がります。
適合率と再現率はトレードオフの関係
適合率と再現率は「あちらを立てればこちらが立たず」の関係にあります。
再現率を上げたい場合
「少しでも怪しければ陽性」と判定基準を緩くする
→ 見逃し(FN)は減るが、誤報(FP)が増える
→ 適合率が下がる
適合率を上げたい場合
「確実に陽性のものだけ」と判定基準を厳しくする
→ 誤報(FP)は減るが、見逃し(FN)が増える
→ 再現率が下がる
「がん検診など見逃しが許されない場面では、どの指標を重視すべきか?」→ 再現率(Recall)
「スパムフィルタなど誤報を減らしたい場面では?」→ 適合率(Precision)
「どのシーンでどの指標を使うか」の判断が問われます。
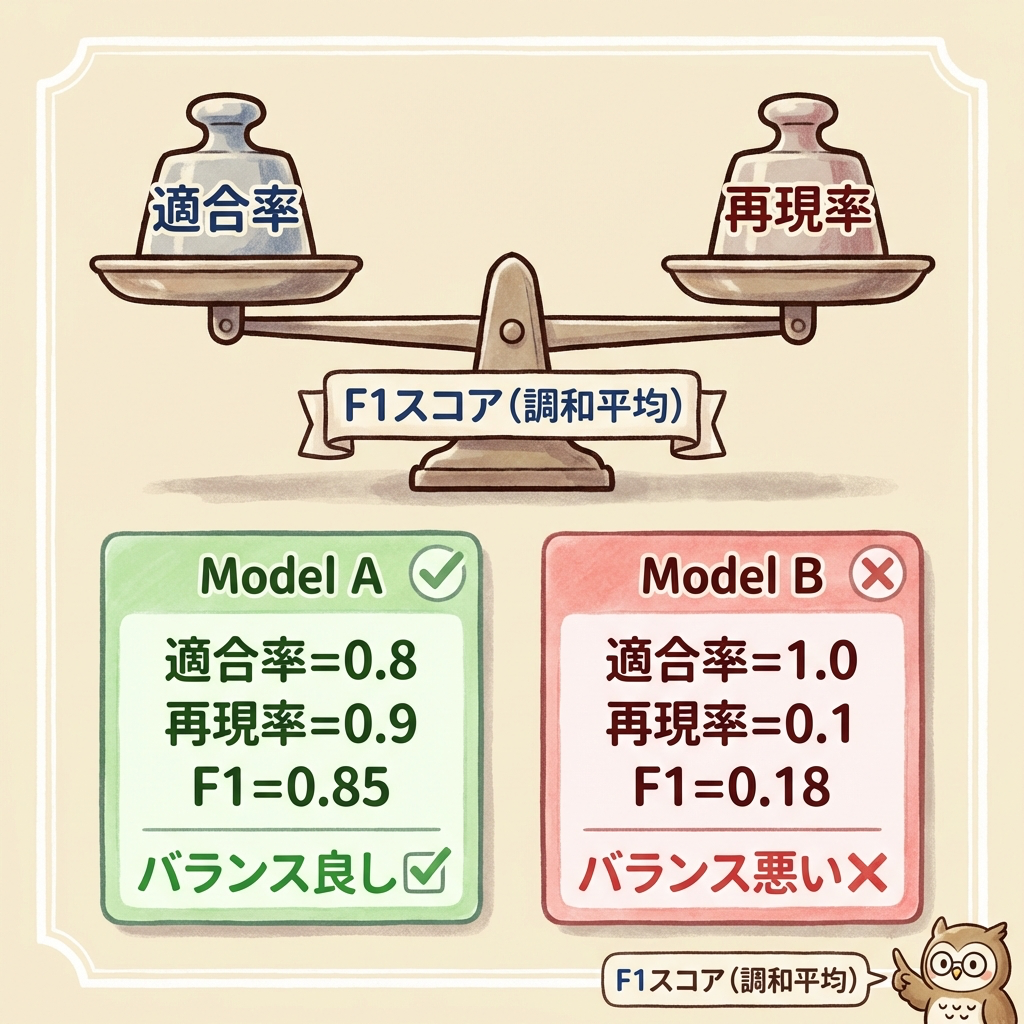
F値(F1スコア)|適合率と再現率の「バランス指標」
適合率と再現率はトレードオフの関係にあるため、「どちらか一方だけ見る」のは危険です。そこで両方のバランスを1つの数値で表す指標がF値(F1スコア)です。
※ 適合率と再現率の調和平均です(算術平均ではありません)
算術平均だと「適合率100%, 再現率0%」でも平均50%になりますが、これは明らかにダメなモデルです。調和平均は低い方の値に引きずられる性質があるため、「片方だけ高い」モデルに甘い評価を与えません。
F1スコアが高いということは、適合率も再現率も両方バランスよく高いことを意味します。
計算例で確認しよう
| モデル | 適合率 | 再現率 | 算術平均 | F1スコア | 評価 |
|---|---|---|---|---|---|
| A | 0.90 | 0.80 | 0.85 | 0.847 | バランス良い |
| B | 1.00 | 0.10 | 0.55 | 0.182 | 再現率が壊滅的 |
モデルBは適合率が完璧(1.00)ですが、再現率が0.10(10個中1個しか見つけられない)。算術平均だと0.55で「まあまあ」に見えますが、F1スコアは0.182と正しく「ダメなモデル」であることを示します。
ROC曲線とAUC|モデルの「総合力」を1つの数値で表す
精度、適合率、再現率、F値はいずれも「特定の閾値(しきい値)での性能」を表す指標です。しかし、閾値を変えれば結果も変わります。そこで、閾値をすべて動かしたときの総合性能を評価するのがROC曲線とAUCです。
ROC曲線とは?
ROC曲線(Receiver Operating Characteristic Curve)は、横軸に偽陽性率(FPR)、縦軸に真陽性率(TPR = 再現率)をとり、閾値を変化させたときの軌跡をプロットしたグラフです。
横軸:偽陽性率(FPR)= FP / (FP + TN) → 「本当は陰性なのに陽性と誤判定した割合」
縦軸:真陽性率(TPR)= TP / (TP + FN) → 「本当に陽性のものを正しく検出した割合」= 再現率
海で魚を釣るとき、網の目を細かくすると魚(陽性)はたくさん捕れますが、ゴミや海藻(陰性)も一緒に入ってきます。網の目を粗くするとゴミは減りますが、魚も逃げます。
ROC曲線は、「網の目の細かさ(=閾値)」を少しずつ変えながら、「魚の捕獲率(TPR)」と「ゴミの混入率(FPR)」のバランスをグラフにしたものです。
良い漁師(良いモデル)は、ゴミがほとんど入らないのに魚はしっかり捕れる。つまりROC曲線が左上に膨らみます。
AUC(Area Under the Curve)とは?
AUCは、ROC曲線の下側の面積です。面積が大きいほど、モデルの総合性能が高いことを意味します。
| AUCの値 | モデルの性能 | イメージ |
|---|---|---|
| 1.0 | 完璧な分類 | 陽性と陰性を100%正しく分離 |
| 0.9〜1.0 | 非常に高い | ほぼ完全に識別できている |
| 0.7〜0.9 | 良好〜まずまず | 実用レベル |
| 0.5 | ランダム(意味なし) | コインを投げるのと同じ=学習できていない |
| 0.5未満 | ランダム以下 | 予測が逆転している(ラベルを入れ替えるべき) |
「AUC = 0.5は何を意味するか?」→ ランダム予測と同等(モデルが何も学習していない)
「AUC = 1.0は何を意味するか?」→ 完璧な分類
「ROC曲線が左上に近いほどモデルの性能が良いのはなぜか?」→ FPR(誤報率)が低いのにTPR(検出率)が高いから

回帰の評価指標|MSE・RMSE・MAE・R²
ここまでは「分類」の評価指標を見てきました。次は「回帰」の評価指標です。回帰は数値を予測するタスクなので、「予測値と実際の値がどれくらいズレているか」で評価します。
| 指標 | 正式名称 | 意味 | 特徴 |
|---|---|---|---|
| MAE | Mean Absolute Error (平均絶対誤差) |
予測と実際のズレの絶対値の平均 | 外れ値の影響を受けにくい。単位が元データと同じで直感的 |
| MSE | Mean Squared Error (平均二乗誤差) |
予測と実際のズレの二乗の平均 | 大きなズレに厳しい(二乗で重みが増す)。数学的に扱いやすい |
| RMSE | Root Mean Squared Error (二乗平均平方根誤差) |
MSEの平方根 | MSEの単位を元に戻したもの。解釈しやすい |
| R² | 決定係数 | モデルがデータの変動をどれだけ説明できるかの割合 | 0〜1の値。1に近いほど当てはまりが良い。0は「平均値と同じ予測」 |
天気予報が「明日は最高気温25℃」と予測し、実際は27℃だったとします。
MAE:|25 - 27| = 2℃ズレていた
MSE:(25 - 27)² = 4(二乗なので単位が℃²になる)
RMSE:√4 = 2℃(MSEを℃に戻した)
MAEとRMSEは単位が元のデータと同じ(℃)なので、直感的に「2℃ズレていた」と理解できます。


{kind=link}
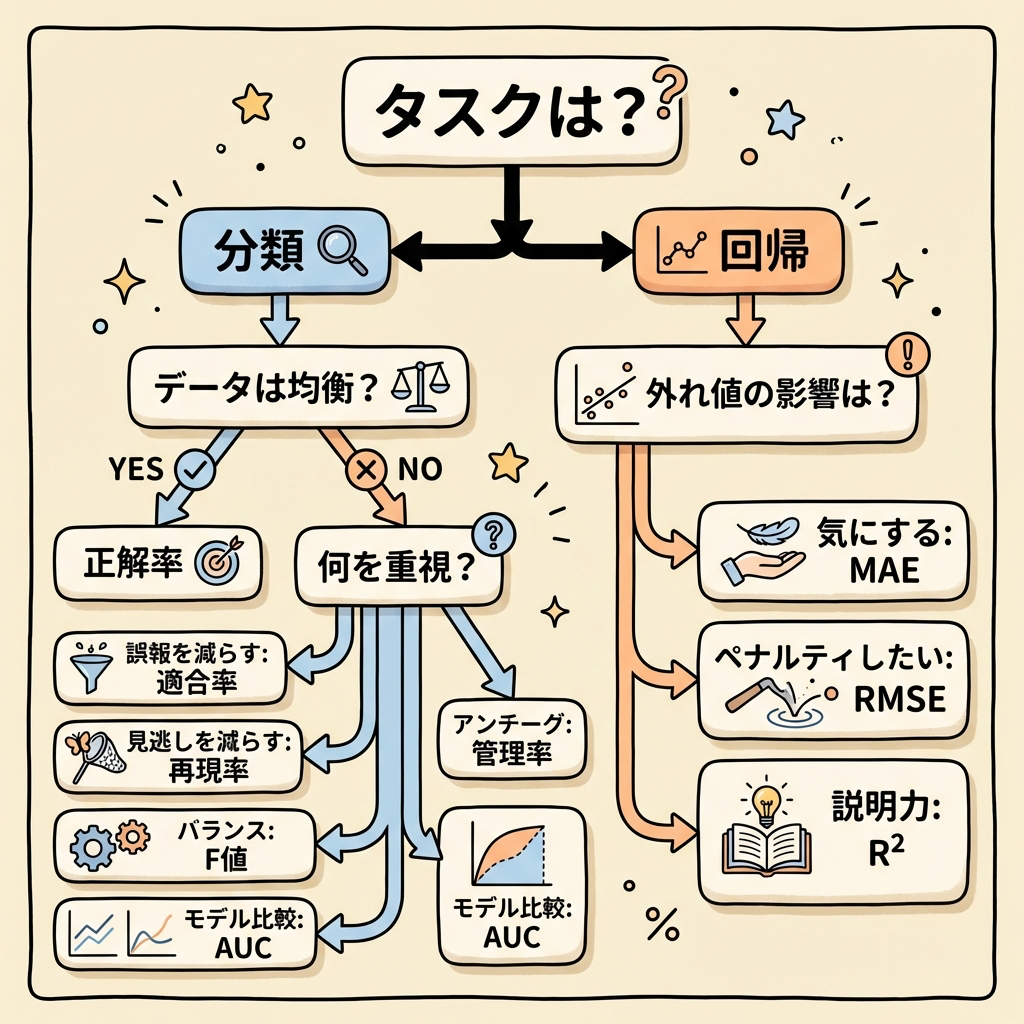
評価指標の全体まとめ|分類と回帰の使い分けマップ
ここまで学んだ評価指標を1枚の表にまとめます。DS検定では「このシーンではどの指標を使うべきか?」が問われるので、使い分けの判断基準を押さえておきましょう。
分類タスクの評価指標マップ
| 指標 | 使うべきシーン | 注意点 |
|---|---|---|
| 正解率 | クラスが均等なデータ(犬50%:猫50%) | 不均衡データでは使えない |
| 適合率 | 誤報を減らしたいとき (スパムフィルタ、レコメンド) |
見逃しが増える可能性あり |
| 再現率 | 見逃しを減らしたいとき (がん検診、不正検知) |
誤報が増える可能性あり |
| F1スコア | 適合率と再現率のバランスを見たいとき | 不均衡データの総合評価に最適 |
| AUC | 閾値に依存しないモデル全体の性能を比較 | 閾値を決める前の「モデル選定」に使う |
回帰タスクの評価指標マップ
| 指標 | 使うべきシーン | 注意点 |
|---|---|---|
| MAE | 外れ値に強く、安定した評価がほしいとき | 大きなズレも小さなズレも同等に扱う |
| MSE / RMSE | 大きなズレを厳しくペナルティしたいとき | 外れ値の影響を受けやすい |
| R² | モデルの説明力を0〜1で比較したいとき | 特徴量を増やすだけで上がる(過大評価の危険性) |
DS検定で問われる機械学習の出題パターンまとめ
最後に、この記事の内容がDS検定でどのように出題されるかを整理します。以下のパターンを押さえておけば、機械学習パートの基礎は万全です。
| 出題パターン | 押さえるべきポイント |
|---|---|
| 「○○は教師あり?教師なし?」 | 正解ラベルがあるか・ないかで判断。クラスタリングは教師なし |
| 「○○は回帰?分類?」 | 出力が数値なら回帰、カテゴリなら分類。ロジスティック回帰は分類 |
| 「過学習の原因・対策は?」 | 原因:モデルが複雑すぎる、データが少ない。対策:正則化、早期終了、交差検証 |
| 「L1正則化とL2正則化の違いは?」 | L1はスパース化(重みをゼロに)、L2は全体を小さく。L1 = Lasso、L2 = Ridge |
| 「適合率 / 再現率 / F値の計算」 | 混同行列からTP,FP,TN,FNを読み取って計算。F値は調和平均 |
| 「見逃しを減らしたい場合の指標は?」 | 再現率(Recall)。がん検診、不正検知など |
| 「AUC = 0.5の意味は?」 | ランダム予測と同等。モデルが何も学習していない |
| 「交差検証の目的は?」 | 汎化性能の安定した評価。データの分割偏りを排除する |
機械学習の基礎は、「なぜその手法が必要なのか」というストーリーを理解することが大切です。「教師あり学習の限界 → 教師なし学習」「正解率の限界 → 適合率/再現率」「適合率/再現率のトレードオフ → F値」「特定の閾値の限界 → AUC」。このように、前の概念の「困りごと」が次の概念を生んでいるという流れで覚えると、丸暗記に頼らず理解が定着します。
📚 次に読むべき記事
DS検定の全体像を把握し、効率的な学習計画を立てよう
機械学習と並ぶ頻出分野「統計学」をまとめて攻略する
機械学習の根幹「回帰分析」を基礎から体系的に学ぶ