
{kind=link}
- 「カイ二乗検定」「F検定」「t検定」のどれを使えばいいか毎回迷う
- 棄却域で「0.05を見るの?0.025?0.95?」とわけがわからなくなる
- 検定統計量の分子・分母に何を置くか混乱する
- 1つ1つの検定は理解したけど、複数の検定が連続する問題になると崩壊する
- 4つの典型シナリオを「問題文のキーワード」だけで見抜く方法
- 棄却域の上側・下側・両側を図で「見て」理解する全パターン
- 複数の検定が連続する問題の「ストーリーの読み方」
- 検定統計量の分子・分母を迷わず決めるルール
QC検定や統計学の試験で、こんな経験はないでしょうか。
「カイ二乗検定は理解した。F検定も理解した。t検定も理解した。……でも、問題を見ると、どれを使えばいいかわからない!」
これ、めちゃくちゃ「あるある」です。個別の検定手法を学ぶ記事は世の中にたくさんありますが、「複数の検定が1つの問題で連続して出てきたとき、どう対処するか」を教えてくれるものは少ないんですよね。
さらに厄介なのが「棄却域」の設定です。「0.05?0.025?0.95?……一体どれを見ればいいの?」と混乱する人が続出します。私も最初はそうでした。
この記事では、QC検定で頻出の「4つの検定シナリオが連続する問題」を題材に、以下の3つの「迷いポイント」を完全に解消します。
目次
🗺️ 全体像:4つのシナリオの「地図」を先に見る
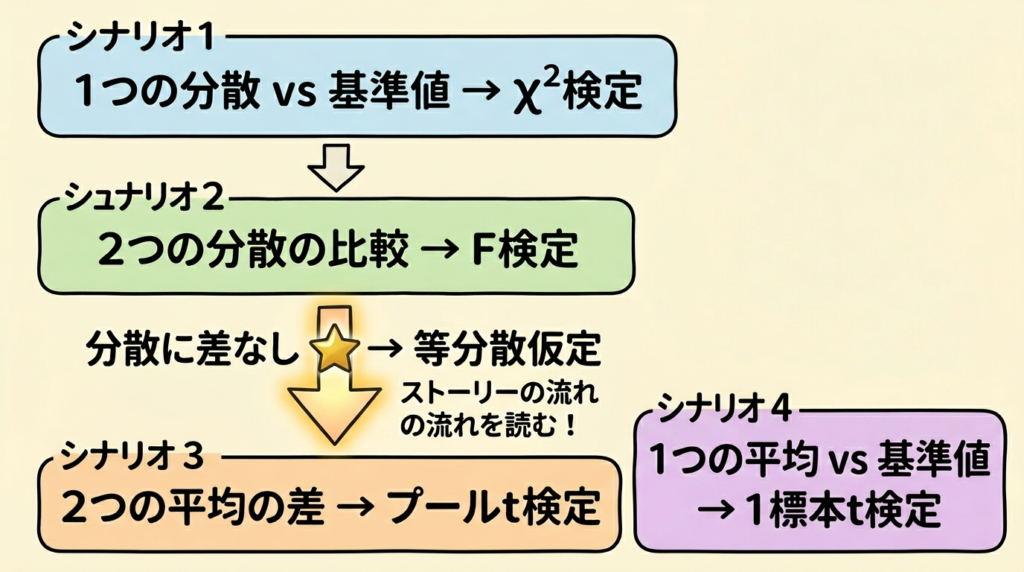
まず、この記事で扱う4つのシナリオの全体像を俯瞰しましょう。「今どこにいるか」がわかれば、迷子になりません。
| シナリオ | 何を検定する? | 使う検定 | 方向 |
|---|---|---|---|
| ① | 1つの母分散 vs 基準値 | χ²検定 | 片側(下側) |
| ② | 2つの母分散が等しいか | F検定 | 両側 |
| ③ | 2つの母平均の差(等分散仮定) | t検定(プール) | 片側(上側) |
| ④ | 1つの母平均 vs 基準値 | t検定(1標本) | 片側(上側) |
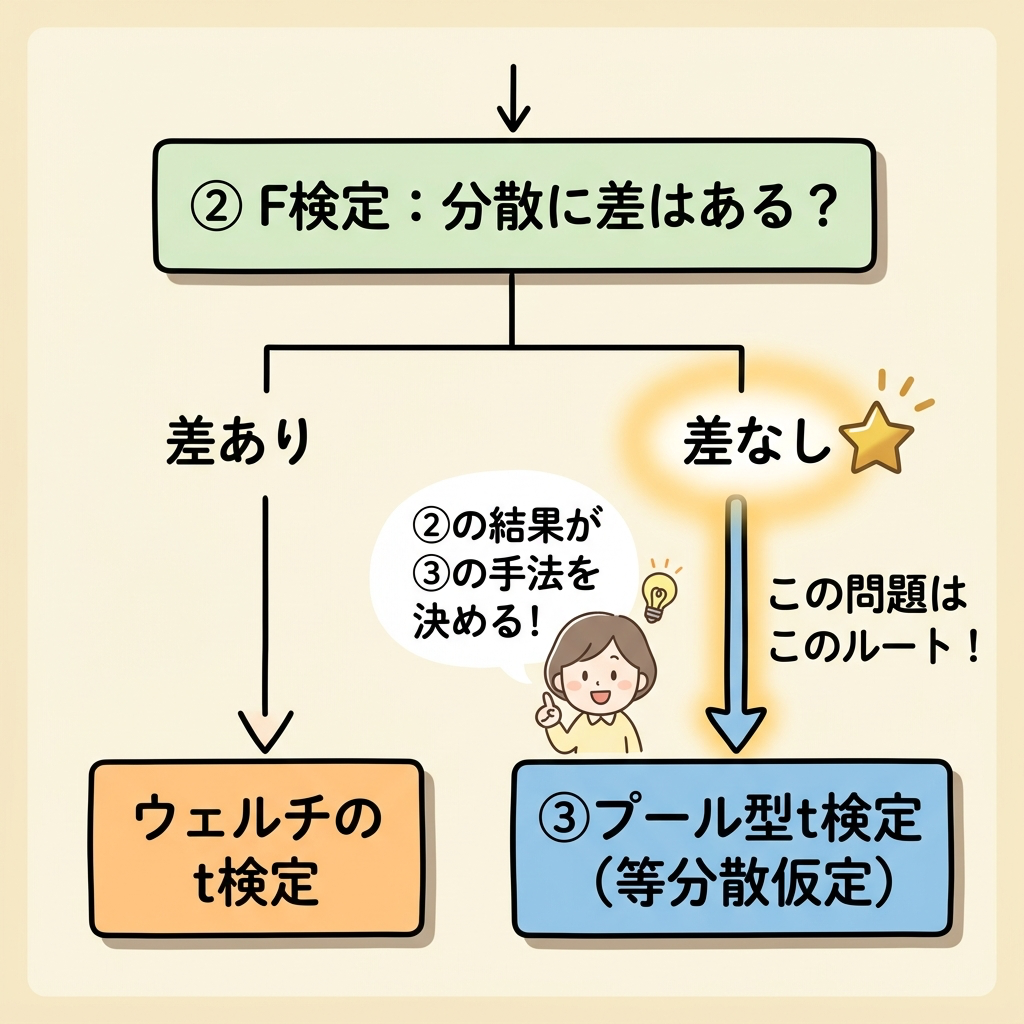
②で「分散に差がない」と判定された → だから③で「等分散を仮定した(プール型)t検定」を使える。このストーリーの流れを読み取ることが、この問題の最大の山場です。
🎯 棄却域で迷う「本当の理由」と解消法
シナリオ別の解説に入る前に、多くの人が棄却域で混乱する「本当の理由」を先に潰しておきます。
混乱の原因:「3つの異なること」を同時に判断しようとしている
棄却域を決めるとき、実は以下の3つを順番に判断するだけです。一度に考えようとするから混乱するんです。
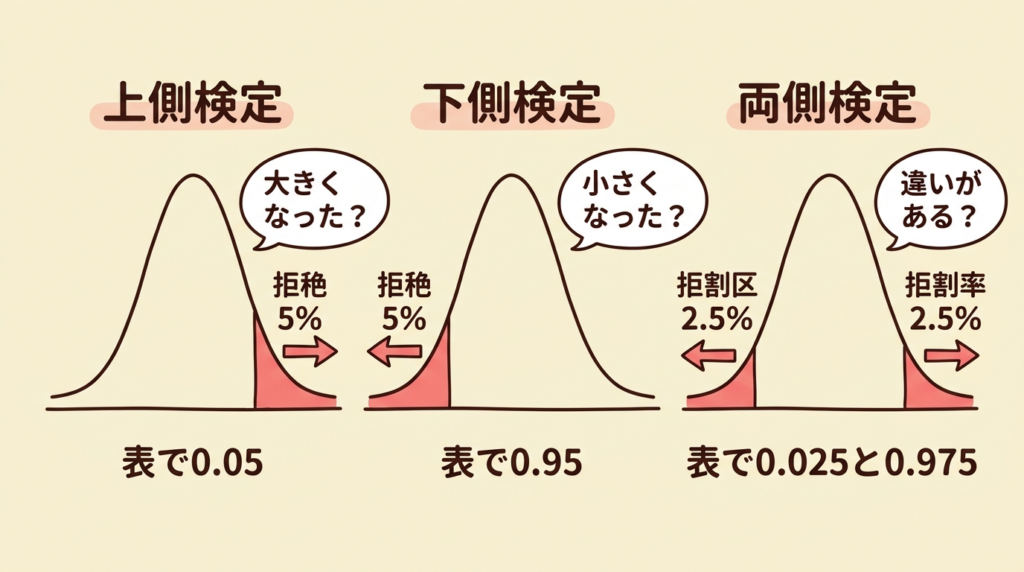
対立仮説の方向は?
「大きくなった?」→ 上側 「小さくなった?」→ 下側 「違いがある?」→ 両側
有意水準αをどう配分する?
片側 → α をそのまま片方に 両側 → α/2 を左右に分ける
分布表で引くべき確率は?
上側を見たい → そのまま0.05(or 0.025)を引く
下側を見たい → 1−α = 0.95(or 0.975)を引く
🔑 判断③が「最大の落とし穴」
「なぜ下側検定で 0.95 を引くの?」──ここが一番わかりにくいポイントです。
理由はシンプルです。χ²分布表やF分布表は「上側確率」で作られているからです。
上側5%点を知りたい場合
表で「0.05」の列を引く。
→ そのまま。直感通り。
下側5%点を知りたい場合
下側5% = 上側95%点。
→ 表で「0.95」の列を引く。
(上側に95%が残っている点 = 下から5%の点)
上側検定(α=5%)→ 表で 0.05 を引く
下側検定(α=5%)→ 表で 0.95 を引く
両側検定(α=5%)→ 表で 0.025(上側)と 0.975(下側)を引く
法則:下側を見たいときは「1 − α」に変換して表を引く。これだけ!
🏭 例題:健康食品メーカーの4つの検定シナリオ
ここからは、オリジナルの例題を使って4つのシナリオを実際に解いていきます。
あるメーカーでは、サプリメントの有効成分の含有量 x を管理している。品質改善のために、以下の4つの場面で統計的検定を行った。有意水準はすべて5%とする。
📊 シナリオ①:1つの母分散 vs 基準値(χ²検定・下側)
従来の製造工程では、含有量 x の母分散は σ₀² であった。工程を改善し、バラつきの低減を図った。改善後に nA 個のサンプルを測定し、偏差平方和 SA、不偏分散 VA を得た。改善後の母分散 σA² が σ₀² より小さくなったかを検定したい。
🔍 問題文から読み取る3つの判断
| 判断 | キーワード | 結論 |
|---|---|---|
| 何を検定? | 「母分散」が「基準値σ₀²」と比べて | χ²検定 |
| 方向は? | 「小さくなったか」 | 片側(下側) |
| 統計量は? | 偏差平方和 SA と基準値 σ₀² | χ₀² = SA / σ₀² |
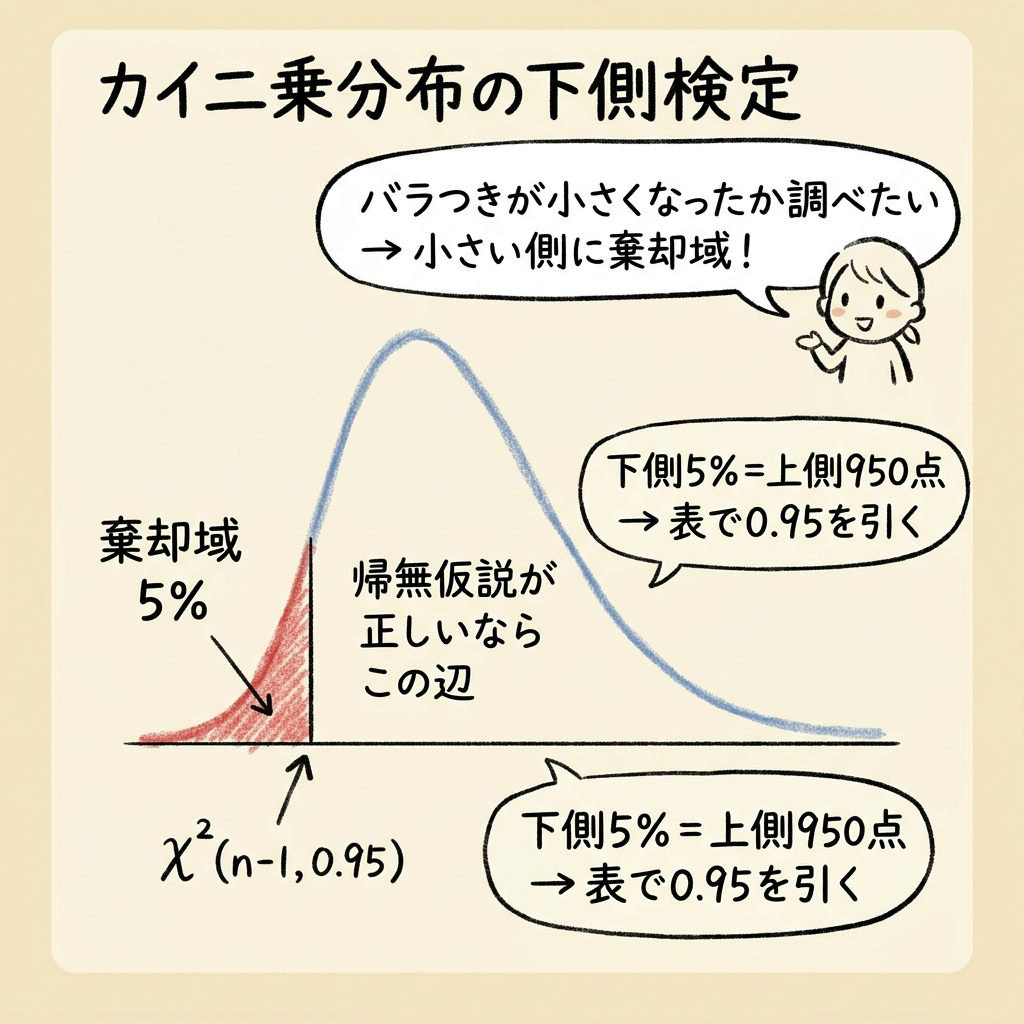
🎯 棄却域はなぜ「下側」なのか? ── 図で理解する
「バラつきが小さくなったか」を調べています。もし本当にバラつきが小さくなったなら、χ₀²の値は小さくなるはずですよね。
なぜなら、χ₀² = SA / σ₀² の分子(改善後のバラつきSA)が小さくなるからです。
【イメージ】χ²分布の下側検定
χ₀²がこの左側の赤い領域に入ったら →「偶然では説明できないほど小さい」→ 帰無仮説を棄却
検定統計量:χ₀² = SA / σ₀²
棄却域:χ₀² ≦ χ²(nA−1, 0.95)
※下側5%点 = 上側95%点 → 表で「0.95」を引く
下側検定では、棄却域は「χ₀² ≦ ○○」です。上側検定の「χ₀² ≧ ○○」と不等号の向きが逆になります。「小さいことを確かめたいから、小さい側で棄却する」と覚えましょう。
📊 シナリオ②:2つの母分散が等しいか(F検定・両側)
製造条件を変更する前後で、含有量 x を測定した。変更前のサンプル(nB個)の不偏分散は VB、変更後のサンプル(nA個)の不偏分散は VA であった(VB < VA)。変更前後で母分散に違いがあるかを検定したい。
| 判断 | キーワード | 結論 |
|---|---|---|
| 何を検定? | 「2つの母分散」の比較 | F検定 |
| 方向は? | 「違いがあるか」(大小を問わない) | 両側検定 |
| 統計量は? | VB < VA → 大きい方を分子 | F₀ = VA / VB |
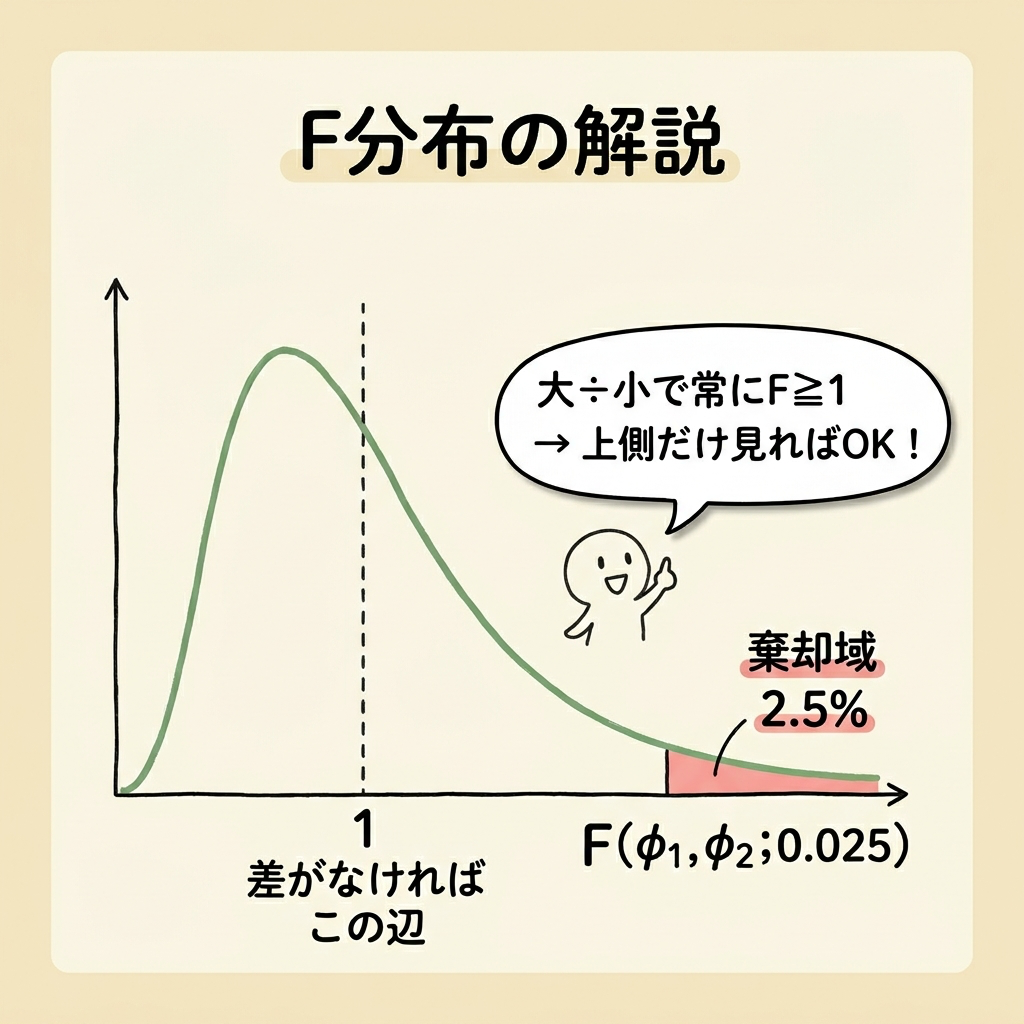
🎯 棄却域はなぜ「上側2.5%」なのか? ── 図で理解する
「違いがあるか」を調べるので両側検定です。有意水準5%を左右に分けて、各2.5%になります。
ただし、F検定では「大きい方 ÷ 小さい方」で常にF₀ ≧ 1 になるように計算するため、実質的に上側だけを見ればOKです。
【イメージ】F分布の両側検定(実質は上側のみ)
F₀が右端の赤い領域に入ったら → 「偶然では説明できないほど分散比が大きい」→ 帰無仮説を棄却
検定統計量:F₀ = VA / VB(大きい方÷小さい方)
棄却域:F₀ ≧ F(nA−1, nB−1; 0.025)
※両側5% → 片方2.5% → 表で「0.025」を引く
F検定では大きい分散を分子に置くことで、F₀が常に1以上になります。こうすると「上側だけ見ればいい」ので判定が楽になるんです。もし小さい方を分子にすると、F₀は1以下になり、下側のF分布表まで調べる必要が出てきます。
📊 シナリオ③:2つの母平均の差(等分散仮定・t検定・片側上側)
シナリオ②の結果、変更前後で母分散に有意差はなかった。そこで、母分散は同等(等分散)と考え、条件変更後に含有量 x が増えているかを検定したい。
「②で分散に差がなかった → だから等分散を仮定 → だからプール型t検定を使う」。この流れを問題文から読み取れるかどうかが合否を分けます。もし②で「差があった」なら、③ではウェルチのt検定を使うことになります。
| 判断 | キーワード | 結論 |
|---|---|---|
| 何を検定? | 「2つの母平均」の差 | t検定(2標本) |
| 等分散? | ②で「差なし」→ 等分散を仮定 | プール型 |
| 方向は? | 「増えているか」 | 片側(上側) |
📐 プール型t検定の検定統計量
「プール」とは「2つのデータのバラつきを混ぜ合わせる」という意味です。等分散を仮定しているので、2つの偏差平方和を合算して共通の分散を作ります。
🎯 棄却域はなぜ「上側5%」なのか? ── 図で理解する
「増えているか」を調べるので、t₀が大きな正の値になったときに棄却します。t分布は左右対称なので、上側検定はシンプルです。
【イメージ】t分布の上側検定
t₀が右端の赤い領域に入ったら → 「偶然では説明できないほど平均差が大きい」→ 帰無仮説を棄却
検定統計量:t₀ =(x̄A − x̄B)/ √{プールした分散 × (1/nA + 1/nB)}
棄却域:t₀ ≧ t(nA+nB−2, 0.05)
※片側上側5% → 表で「0.05」をそのまま引く
📊 シナリオ④:1つの母平均 vs 基準値(t検定・片側上側)
含有量 x の母平均 μ が基準値 μ₀ より大きいことを確認したい。確認実験を nA 回行い、平均値 x̄A、不偏分散 VA を得た。母平均 μ が μ₀ より大きくなったかを検定したい。
| 判断 | キーワード | 結論 |
|---|---|---|
| 何を検定? | 「1つの母平均」vs 基準値μ₀ | t検定(1標本) |
| 方向は? | 「大きくなったか」 | 片側(上側) |
| 統計量は? | x̄A、μ₀、VA、nA | t₀ = (x̄A−μ₀)/√(VA/nA) |
検定統計量:t₀ = (x̄A − μ₀) / √(VA / nA)
棄却域:t₀ ≧ t(nA−1, 0.05)
※片側上側5% → 表で「0.05」をそのまま引く。自由度は nA−1。
③は「2つのグループの平均の差」→ 自由度 = nA+nB−2
④は「1つのグループの平均 vs 基準値」→ 自由度 = nA−1
検定統計量の分母の形も違います。③はプールした分散、④は1つの不偏分散VAです。
🧠 最終兵器:棄却域の「完全早見表」
ここまで4つのシナリオを見てきました。最後に、棄却域の設定パターンを1枚の表にまとめます。試験直前にこの表を見返すだけで、棄却域の迷いは消えるはずです。
棄却域の完全早見表(α = 5%)
| 対立仮説 | 意味 | 棄却域の位置 | 表で引く確率 | 不等号 |
|---|---|---|---|---|
| >(大きい?) | 上側検定 | 右端 | 0.05 | 統計量 ≧ 臨界値 |
| <(小さい?) | 下側検定 | 左端 | 0.95 | 統計量 ≦ 臨界値 |
| ≠(違う?) | 両側検定 | 左端+右端 | 0.025 と 0.975 | 両方の端を超える |
「調べたい方向に棄却域を置く」
大きくなったか → 大きい側(右)に棄却域
小さくなったか → 小さい側(左)に棄却域
違うか → 両方に棄却域
そして、下側を見たいときだけ「1−α」に変換して表を引く。これだけです。
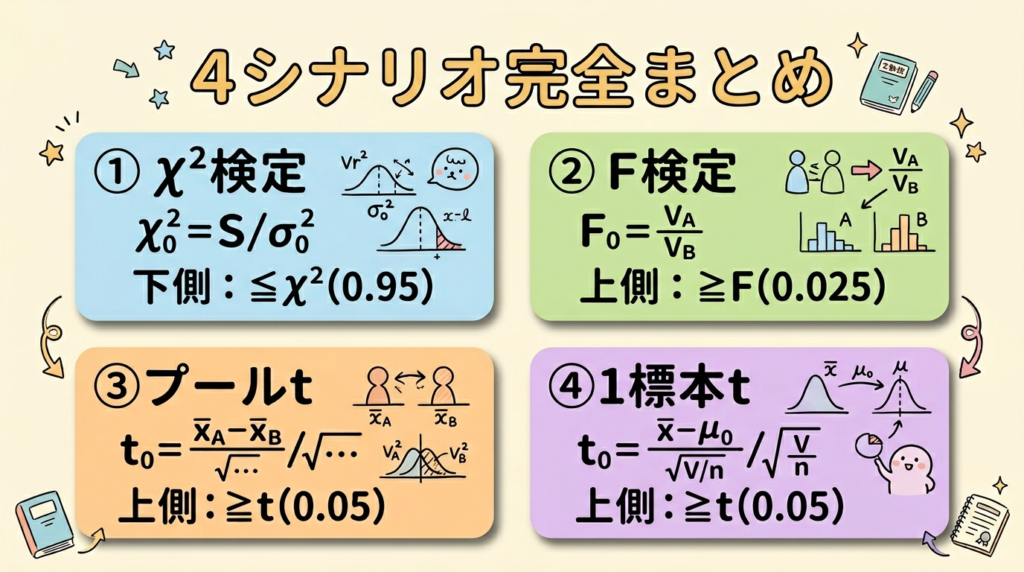
4シナリオの答え一覧
| # | 検定 | 検定統計量 | 棄却域 |
|---|---|---|---|
| ① | χ²検定 | χ₀² = SA/σ₀² | χ₀² ≦ χ²(nA−1, 0.95) |
| ② | F検定 | F₀ = VA/VB | F₀ ≧ F(nA−1, nB−1; 0.025) |
| ③ | t検定(プール) | t₀ = (x̄A−x̄B)/√{…} | t₀ ≧ t(nA+nB−2, 0.05) |
| ④ | t検定(1標本) | t₀ = (x̄A−μ₀)/√(VA/nA) | t₀ ≧ t(nA−1, 0.05) |
📝 まとめ
- 「どの検定?」は問題文のキーワードで決まる:分散→χ²かF、平均→t
- 「棄却域の方向」は対立仮説で決まる:大きい→上側、小さい→下側、違う→両側
- 下側を見たいときだけ「1−α」に変換して表を引く(0.95 や 0.975)
- ②→③のストーリーを読む:F検定で分散に差なし→等分散仮定のプール型t検定
- 検定統計量の分子・分母は「何を何で割るか」のパターンで覚える
この記事で扱った4シナリオは、QC検定で繰り返し出題される「黄金パターン」です。個別の検定を1つずつ理解するだけでなく、「複数の検定がストーリーとしてつながっている」という視点を持つことで、初見の問題にも対応できるようになります。
もし「そもそもどの検定を使うべきか、もっと体系的に整理したい」という方は、検定の選び方フローチャートの記事が全体像の把握に役立ちます。
📚 次に読むべき記事
この記事で扱った4パターンの「上位互換」。すべての検定手法を1枚のフローチャートに整理しています。
シナリオ①の棄却域が「0.95」になる理由をさらに深堀り。χ²分布の非対称性を図解しています。
検定・推定の全体像を体系的に学びたい方はこちら。28記事の最適な読み順をガイドします。