
{kind=link}
- t分布がどんな形をしているかイメージでわかる
- なぜデータが少ないと判定基準が厳しくなるのか理解できる
- 自由度とt分布の形の関係がスッキリわかる
- t分布が正規分布に近づいていく仕組みがわかる
前回、t検定の計算方法を学びましたね。
その中で、こんな疑問を持ちませんでしたか?
🤔 「なんでZ検定は1.96なのに、t検定は2.262とか違う値なの?」
🤔 「自由度が変わると、なんで判定基準が変わるの?」
🤔 「データが少ないと厳しくなるって、どういう意味?」
この疑問の答えは、t分布の「形」を見れば一発でわかります。
今回は、t分布と自由度の関係を、イメージで徹底的に理解していきましょう。
目次
t分布のイメージ|「自信がない分、広く構える」
まず、t分布がどんな形をしているか、イメージで掴みましょう。
正規分布とt分布を並べてみよう
正規分布とt分布、どちらも「釣鐘型(ベルカーブ)」の形をしています。
でも、よく見ると違いがあります。

t分布の特徴は、「裾野が広い」ことです。
これを別の言い方をすると、「極端な値が出やすい」ということになります。
たとえ話で理解しよう|「慎重なアーチャー」
t分布と正規分布の違いを、弓矢の的当てでたとえてみましょう。
🎯 「的当てゲーム」でたとえると…
👼 神様(正規分布・Z検定)
「的の位置を完璧に知っている」
→ 自信を持って的の中心を狙える
→ 矢は中心付近に集中する
👨🔬 人間(t分布・t検定)
「的の位置をだいたいしか知らない」
→ ちょっと不安なので、広めに狙う
→ 矢は中心からズレやすい(裾野が広い)
t分布の「裾野が広い」とは、「不確実さを反映している」ということなんです。
自由度とは?|「自信の度合い」を表す数字
t検定では、自由度という数字が登場しますね。
一標本t検定の場合、自由度 = n − 1(データ数 − 1)です。
この「自由度」は、t分布の「形」を決めるパラメータです。
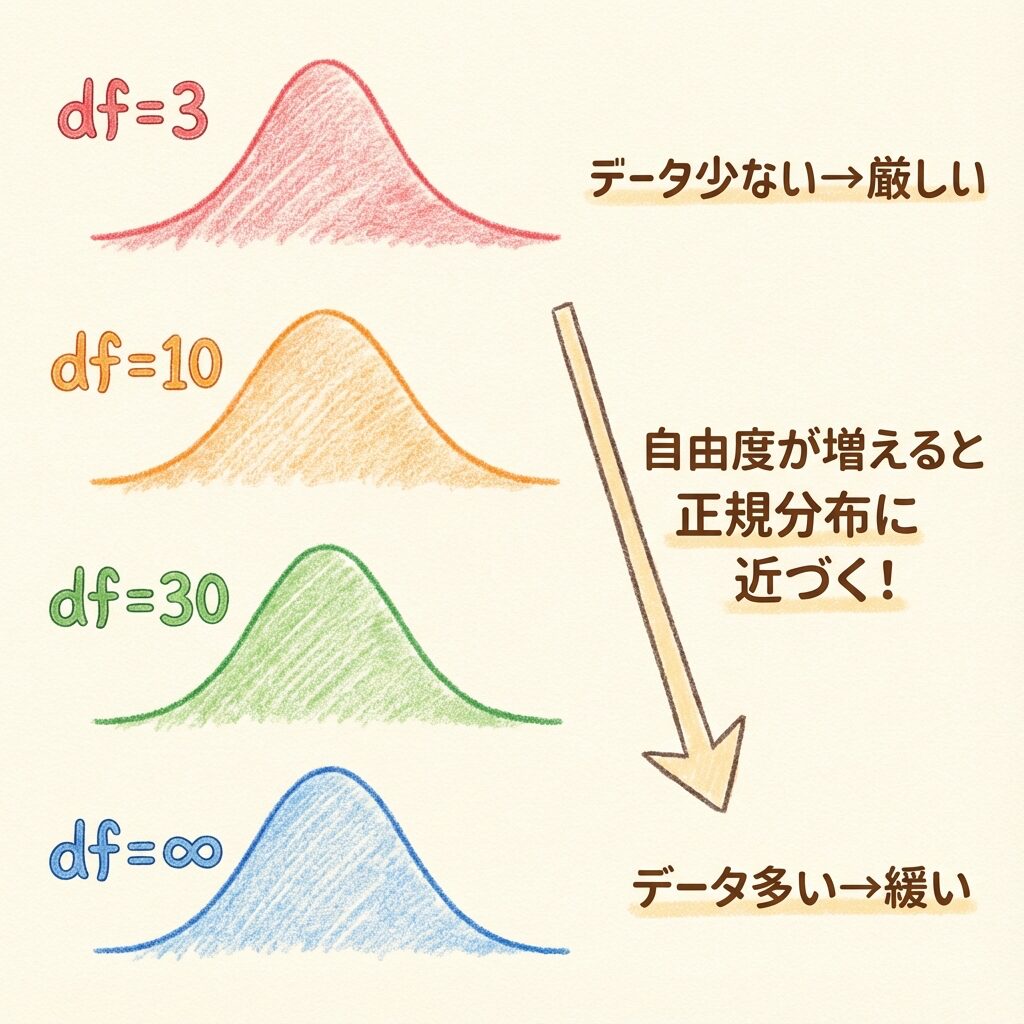
自由度が変わると、t分布の形はどう変わる?
ここが今日の最重要ポイントです。

📈 自由度が変わると、t分布の形はこう変わる!
自由度が小さい(データが少ない)
裾野がとても広い → 極端な値が出やすい → 判定基準がかなり厳しい
自由度が中くらい
裾野がやや広い → まだ正規分布より不確実 → 判定基準がやや厳しい
自由度が大きい(データが多い)
裾野が狭くなる → 正規分布に近づく → 判定基準が緩くなる
自由度が無限大
正規分布と一致! → 判定基準は1.96(Z検定と同じ)
自由度が大きくなる → t分布は正規分布に近づく
つまり、データ数が増えれば増えるほど、
t検定はZ検定に近づいていくのです。
たとえ話で理解しよう|「経験を積んだ職人」
👨🍳 「寿司職人」でたとえると…
🔰 新人職人(自由度が小さい=データが少ない)
「まだ3回しか握ってない…」
→ 自分の腕に自信がない
→ お客さんも「この人大丈夫?」と厳しい目で見る
👨🍳 ベテラン職人(自由度が大きい=データが多い)
「10000回握ってきた」
→ 自分の腕に自信がある
→ お客さんも「この人なら安心」と信頼する
経験(データ)が少ないうちは、「たまたまうまくいった」可能性を疑われる。
だから、より厳しい基準で判定される必要があるのです。
臨界値の変化を数字で確認しよう
「裾野が広い」「判定基準が厳しい」という話を、実際の数字で確認しましょう。
有意水準α = 5%(両側検定)のときの臨界値を見てください。
| 自由度 (df = n-1) |
データ数 (n) |
臨界値 (α=5%, 両側) |
判定の厳しさ |
|---|---|---|---|
| 3 | 4 | 3.182 | 🔴 かなり厳しい |
| 5 | 6 | 2.571 | 🟠 厳しい |
| 9 | 10 | 2.262 | 🟡 やや厳しい |
| 19 | 20 | 2.093 | 🟢 普通 |
| 29 | 30 | 2.045 | 🟢 ほぼ正規分布 |
| ∞ | ∞ | 1.960 | 🔵 正規分布と一致 |
- 自由度3(データ4個)では、臨界値が3.182(かなり厳しい!)
- 自由度が増えると、臨界値はだんだん小さくなる
- 自由度∞では、臨界値が1.960(Z検定と同じ!)
- 一般的に、自由度30以上なら正規分布とほぼ同じとみなせる
図でイメージしよう|「ゴールラインの位置」
臨界値の違いを、「ゴールラインの位置」でたとえてみましょう。
🏃 「有意差を出す」=「ゴールラインを超える」
0 ─────────────────────── │ 3.182 (df=3)
0 ───────────────────── │ 2.571 (df=5)
0 ─────────────────── │ 2.262 (df=9)
0 ───────────────── │ 1.960 (df=∞)
データが少ないと、ゴールラインが遠くにある(超えるのが大変)
データが多いと、ゴールラインが近くにある(超えやすい)
なぜ「厳しく」する必要があるのか?
「データが少ないから厳しくする」というのは、感覚的には理解できますよね。
でも、なぜ統計学的にそうなるのか、もう少し深掘りしてみましょう。
理由①:標本標準偏差の「ブレ」が大きい
t検定では、母分散の代わりに標本標準偏差(s)を使います。
でも、この「s」はサンプルから計算した推定値です。
データが少ない場合
📊❓
サンプルが少ない
→ sの計算が不安定
→ 「たまたま」の影響を受けやすい
データが多い場合
📊✅
サンプルが多い
→ sの計算が安定
→ 真の値に近づく
データが少ないと、標本標準偏差sが真の値からズレやすいんです。
そのズレを考慮して、判定基準を厳しくしておく必要があるのです。
詳しくは不偏分散の記事で解説しています。

理由②:「たまたま」のリスクを抑える
データが少ないと、「たまたま」極端な結果が出やすいんです。
🎰 「コイン投げ」でたとえると…
コインを4回投げた場合
「4回中4回とも表が出た!」 → 表の確率100%?
いやいや、たまたまでしょ…と疑う余地がある
コインを100回投げた場合
「100回中52回表が出た」 → 表の確率約50%
これなら信頼できそうと思える
データが少ない状態で「有意差あり!」と判定すると、第1種の過誤(あわてんぼうのミス)のリスクが高まります。
そのリスクを抑えるために、判定基準を厳しくするのです。
実務での目安|「自由度30」がひとつの境界線
統計学の世界では、こんな目安があります。
📏 実務での目安
- 自由度 ≤ 30(データ31個以下):t分布を使う
- 自由度 > 30(データ32個以上):正規分布で近似してもOK
※ 厳密には、常にt分布を使う方が正確です。
Excelなどの統計ソフトは自動的にt分布で計算してくれます。
まとめ|t分布は「不確実さの反映」
📝 この記事のまとめ
- t分布は正規分布より裾野が広い(極端な値が出やすい形)
- 自由度が小さいほど裾野が広く、判定基準が厳しくなる
- 自由度が大きくなると、t分布は正規分布に近づく
- 自由度∞で正規分布と一致(臨界値1.96)
- これは「データが少ない=不確実」を数学的に反映している
🎓 覚え方のコツ
自由度が小さい = 自信がない = 厳しく判定
新人は厳しく評価される、ベテランは信頼されるのと同じ!
次に読むべき記事
t分布と自由度の関係を理解したら、次は「2つのグループを比較するt検定」を学びましょう。
「A組とB組の平均に差はあるか?」のような、2標本の比較ができるようになります。
💪 ここまで読んでくださった方へ
「なぜ自由度で判定基準が変わるのか?」
この疑問が、イメージで理解できましたね!
データが少ない=不確実=厳しく判定
この感覚を身につけておくと、
t検定の結果を正しく解釈できるようになります!
📚 関連記事
- 第17回:t分布とは?|「データが少ないのに正規分布を使うな!」と神様が怒る理由を完全図解
- 【完全図解】自由度とは?|「なぜn-1で割るのか」を中学生でも分かるように解説
- 【計算例あり】t検定(一標本)|「規格通りか?」を検証する実務の基本
- 【基礎】Z検定とは?|真の分散を知っている「神様の検定」を理解する
- 第16回:【完全解説】正規分布とは?|統計の王様を初心者向けに徹底図解
- 【統計学】不偏分散はなぜ n-1 で割る?直感で分かる「バラつき過小評価」の正体
- 【統計学】第1種の過誤(生産者危険)と第2種の過誤(消費者危険)|あわてんぼうとぼんやり者、どっちが罪深い?
- 【統計学】P値と有意水準(α)|「5%の奇跡」が起きたら、それは偶然じゃないと疑う
- 【完全版】検定・推定の学習ロードマップ|初心者が「どの検定を使うか」迷わなくなる全28記事の読み順ガイド