{kind=link}
- 客先監査で「このデータ正規分布じゃないですよね?Cpkの値が信頼できないのでは?」と指摘された
- ヒストグラムが明らかに片寄っているのに、Cpkだけは1.33を超えていて違和感がある
- 真円度や面粗さの値(=0以下にならないデータ)を、Cpkで評価して良いか分からない
- 「正規性検定で棄却された」と部下に報告されたが、その後どう改善するか分からない
- なぜCpkが正規分布を前提にしているのか、その理由が分かる
- 正規分布じゃないデータをCpkで評価したときの「ズレ」が直感的に分かる
- 非正規データへの3つの対処法(Box-Cox変換/ノンパラ法/Pearson系分布)の使い分けが分かる
- 客先監査で「このデータでCpk使ってOK」と根拠を持って答えられるようになる
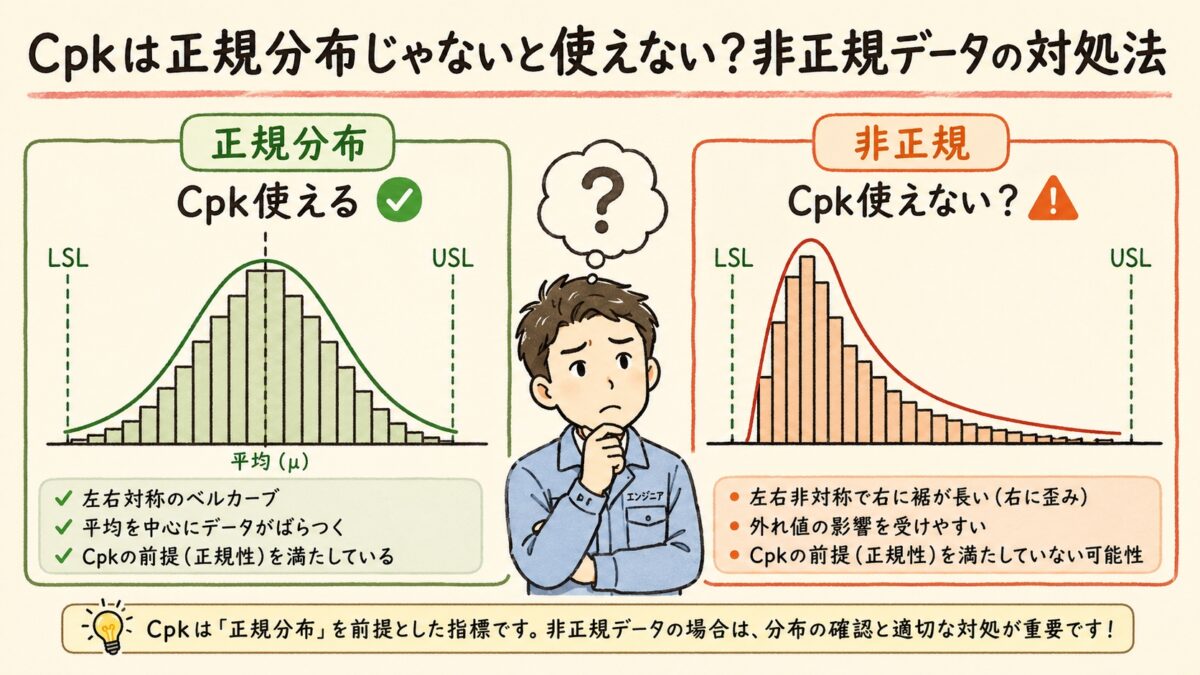
結論を先に言います。Cpkは正規分布を前提とした指標です。データが非正規だと、計算上のCpk値と実際の不良率(ppm)に大きなズレが生じます。ただし、対処法はあります。「データ変換」「ノンパラメトリック法」「Pearson系分布の利用」の3つを使い分ければ、非正規データでも工程能力を正しく評価できます。
この記事では、なぜ正規分布前提が崩れるとCpkが信頼できなくなるのかを絵で完全に理解し、実務で使える3つの対処法を一気に解説します。読み終わる頃には、客先監査で非正規データを見せられても「この方法でCpk相当値を出しているので問題ないです」と即答できるようになります。
なぜCpkは正規分布を前提にしているのか
Cpkの定義式を思い出してみましょう。
Cpk = min(Cpu, Cpl)
Cpu = (USL − μ) / 3σ / Cpl = (μ − LSL) / 3σ
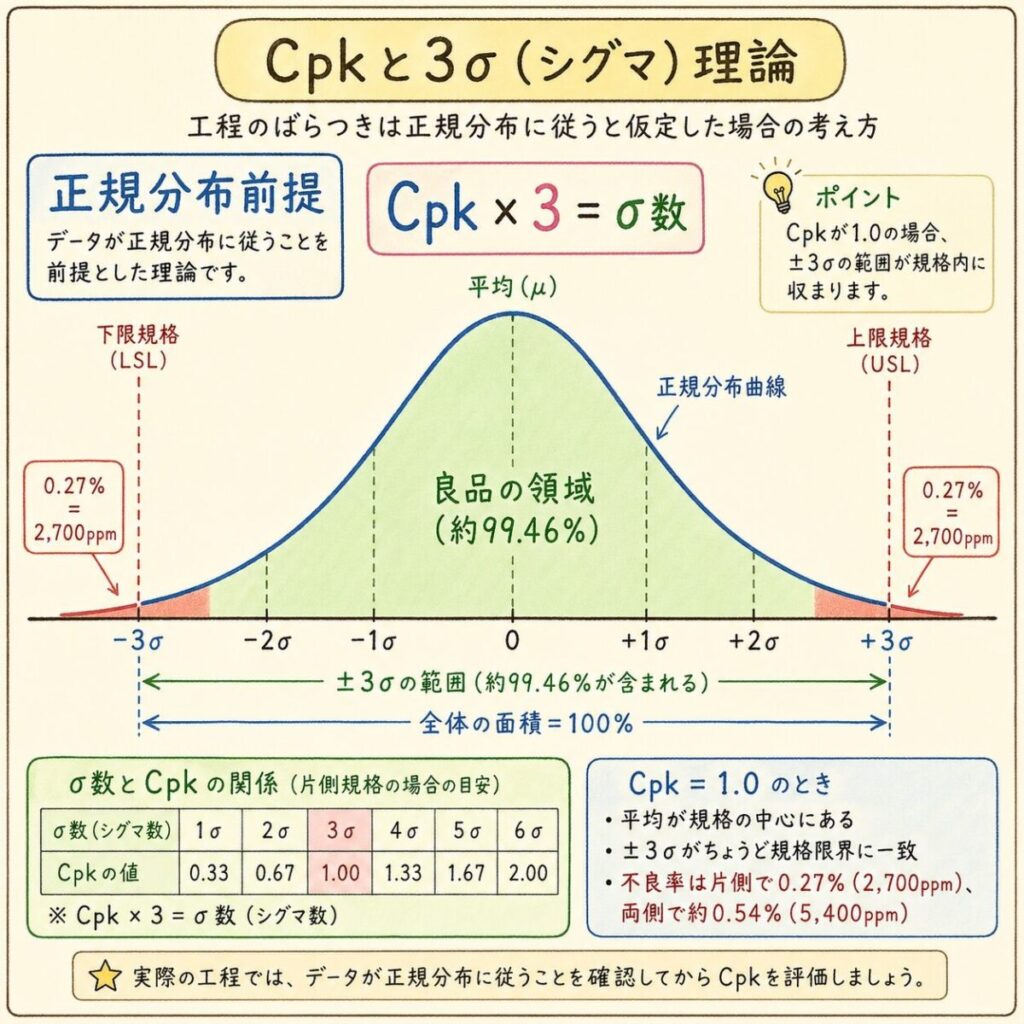
ここで「3σ」という値が出てきますが、これは正規分布で「中心から3σ離れた点までに、データの99.73%が収まる」という性質を使っています。つまり、Cpkは内部で「正規分布だよね」と仮定しているのです。
Cpk=1.33 → 約63ppm(10万個に6個の不良)
この63ppmという数字は、「正規分布で4σ以上外れる確率」から計算されています。データが正規分布でないと、この換算が成り立ちません。
【QC検定】工程能力指数とppm不良率の関係|Cpk1.33で不良は何ppmか? →
製造業で「非正規分布」になりやすい4パターン
製造現場でよく出会う「正規分布にならないデータ」は、だいたいこの4パターンです。自分の工程がどれに当てはまるか、考えながら読んでみてください。
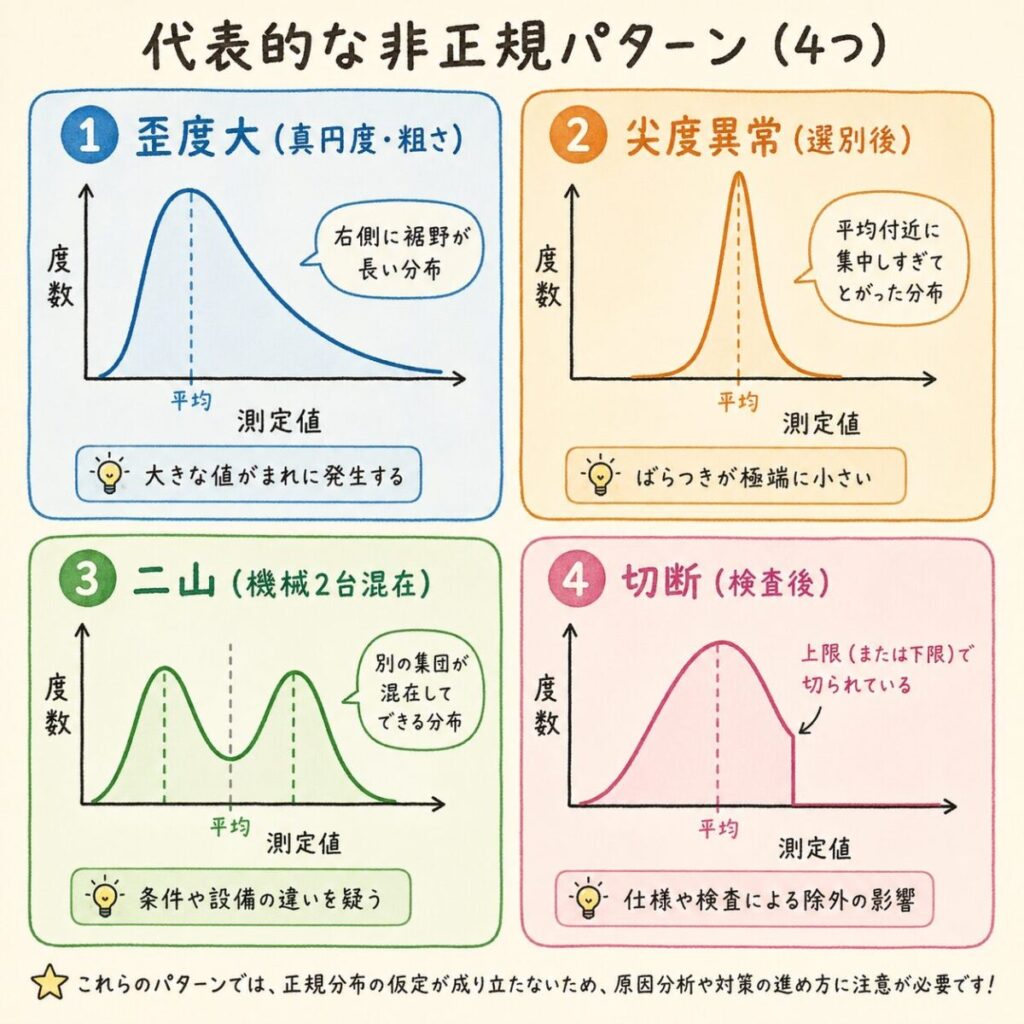
パターン1:片寄り(歪度大)
- 真円度・平面度・粗さ(0以下にならない)
- 不純物濃度・残留物
- 右側に長い裾を引く形
パターン2:尖度の異常
- データが妙に中央に集中
- 選別後のデータ
- 同一治具での加工
パターン3:二山分布
- 2台の機械の出力が混在
- 2人のオペレータの差
- ロット切り替えの混入
パターン4:切断分布
- 選別検査で除去された後
- 限界値での切り捨て
- 裾が急に切れる形
特に「真円度」「面粗さ」「平面度」など0以下にならない物理量は、ほぼ必ず非正規(右に裾を引く)になります。Cpkを使う前に、ヒストグラムで形を確認する癖をつけましょう。
【完全図解】歪度と尖度とは?|正規分布との「ズレ」を数値化する2つの指標 →
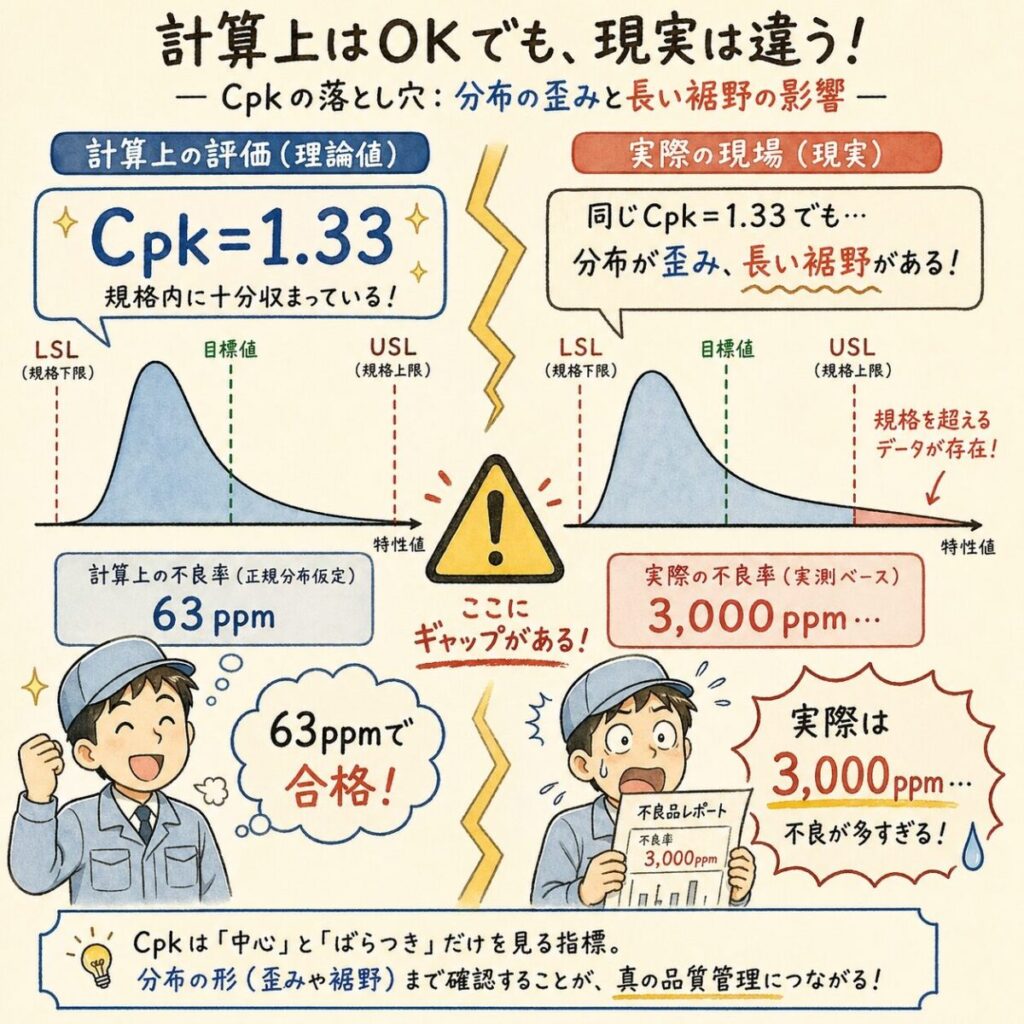
非正規データでCpkを使うと「嘘」が起きる
非正規データに無理やりCpkを当てはめると、計算上のCpkは1.33を超えているのに、実際は不良が頻発するといった現象が起きます。
右に裾を引く分布の例(真円度など)
| 項目 | 通常のCpk値 | 理論ppm(正規前提) | 実際のppm(非正規) |
|---|---|---|---|
| 弱い歪み | 1.33 | 63 ppm | 100〜500 ppm |
| 中程度の歪み | 1.33 | 63 ppm | 1,000〜3,000 ppm |
| 強い歪み | 1.33 | 63 ppm | 5,000〜10,000 ppm |
「Cpk=1.33で良好」と報告 → 実際は3000ppmの不良が出る → 客先クレーム → なぜ?を聞かれる → 答えられない、というパターン。歪んだ分布のCpkは過大評価になるので注意。
なぜズレるのか?正規分布とのギャップ
非正規データでズレが起きる理由はシンプルです。Cpkの計算は「3σ離れた点に規格がある」と考えますが、実際の分布は規格側に裾を長く引いているので、その裾の部分の不良発生確率を見落とすのです。
対処の前に|正規性の確認方法
非正規だと判断する前に、本当に非正規なのかを確認する手順があります。
ヒストグラムを描く
まずは目で見る。これが基本中の基本。釣鐘型に見えるか、片寄っているか、二山か、を確認。
正規確率プロットで確認
縦軸に累積確率、横軸にデータをプロットすると、正規分布なら直線に並ぶ。曲がっていたら非正規。
歪度・尖度の値を計算
歪度の絶対値が0.5未満、尖度が-1〜+1ならほぼ正規とみなしてOK。それを超えると要対処。
正規性検定(シャピロ・ウィルク検定など)
p値が0.05未満なら「正規分布ではない」と判定。ただしサンプル数が大きいと過敏に反応するので、ヒストグラム併用が必須。
正規性検定だけに頼ると、サンプル数が500個以上あるとほぼすべて「非正規」と判定されてしまいます。「ヒストグラム+確率プロット+検定」の3点セットで総合判断するのが実務の鉄則。
第6回:【完全図解】ヒストグラムとは?|データの「形」が一目でわかる最強のグラフ →

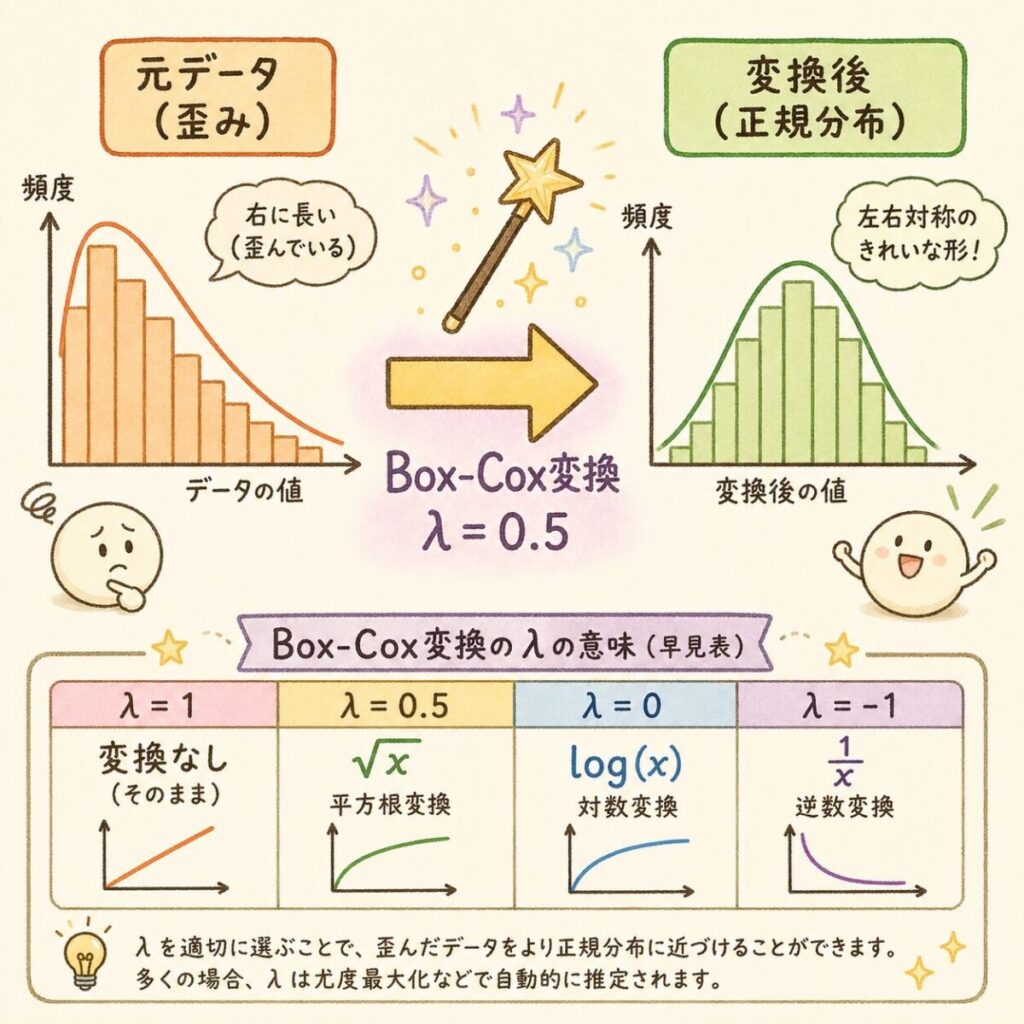
対処法1|データを変換して正規分布に近づける(Box-Cox変換)
最もよく使われる手法がBox-Cox変換です。データに数式を当てて、正規分布に近い形に変形してからCpkを計算します。
y = (x^λ − 1) / λ(λ ≠ 0)
y = ln(x)(λ = 0)
x:元データ / λ:変換係数(自動最適化される)
λの値を変えるだけで、対数変換、平方根変換、逆数変換など、いろんな変換が一つの式で表現できる優れものです。
| λの値 | 変換 | 適用例 |
|---|---|---|
| λ = 1 | 変換なし | 既に正規 |
| λ = 0.5 | 平方根変換 | 少し右に裾を引く |
| λ = 0 | 対数変換 | 真円度・濃度などで頻出 |
| λ = -0.5 | 逆平方根 | 強い右の歪み |
| λ = -1 | 逆数変換 | 非常に強い歪み |
Box-Cox変換の手順
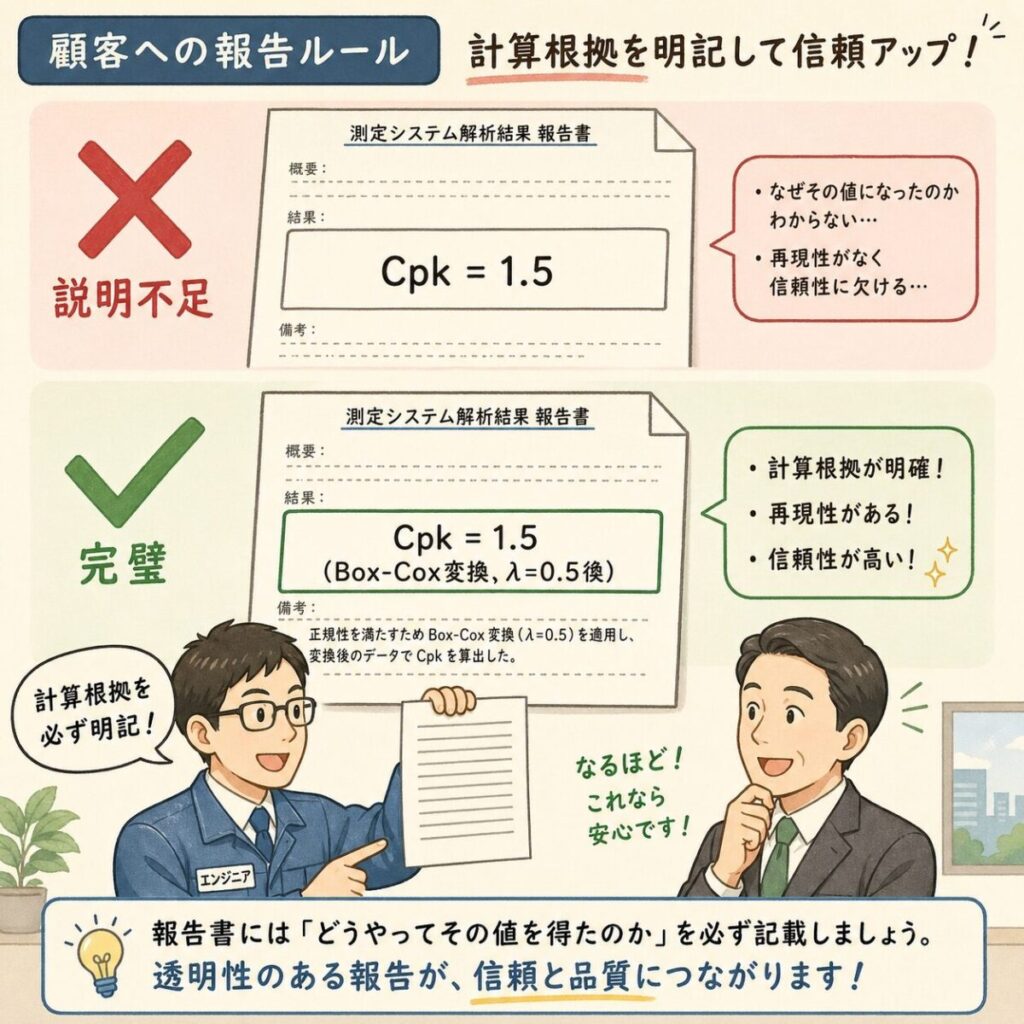
変換後のCpk値は、客先に「Box-Cox変換(λ=0.5)後の値です」と明記する必要があります。説明なしで「Cpk=1.5」とだけ報告すると誤解の元。また、データに負の値があると使えません(その場合はYeo-Johnson変換を使う)。
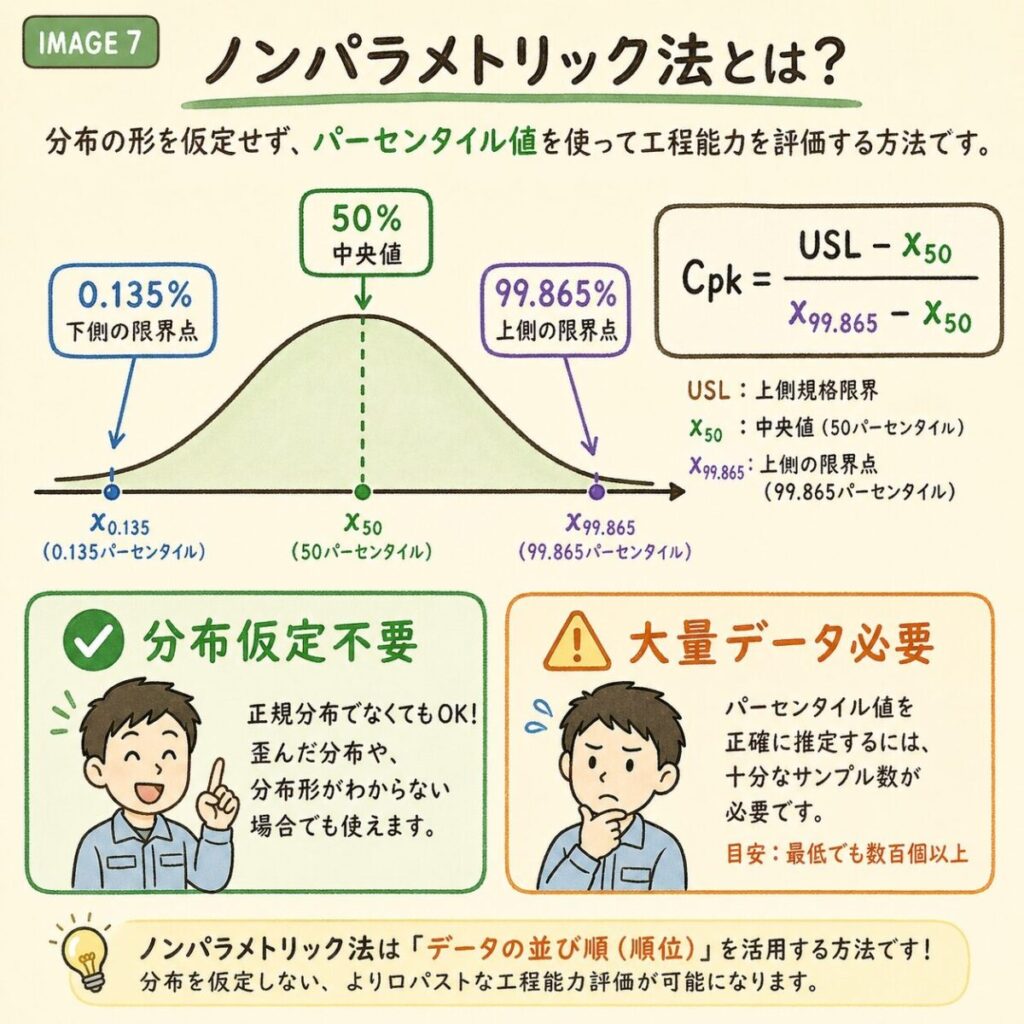
対処法2|分布を仮定しないノンパラメトリック法
データを変換せず、分布の形を仮定しないで実データの分位点(パーセンタイル)から直接計算する方法です。「クォンタイル法」「ISO 21747法」とも呼ばれます。
Cpk = min((USL − x_50) / (x_99.865 − x_50), (x_50 − LSL) / (x_50 − x_0.135))
x_50:中央値(メジアン) / x_99.865:99.865%点 / x_0.135:0.135%点
ややこしい式に見えますが、考え方はシンプルです。正規分布での「中心〜+3σ」を「中央値〜99.865%点」に置き換えただけです。正規分布なら一致するし、非正規でも実データから直接計算できるのが利点です。
ノンパラメトリック法のメリット・デメリット
メリット
- 分布の仮定不要
- 変換と違って「実数値」のまま
- 客先に説明しやすい
- 外れ値に強い
デメリット
- サンプル数が大量必要(最低500個)
- 裾の精度が低い
- 0.135%点の推定が難しい
- 計算ツールが限られる
ノンパラメトリック法はサンプル数が大量にある量産品に向いています。試作段階の少サンプルでは精度が出ないので、Box-Cox変換のほうが実用的。「量産はノンパラ、試作は変換」と覚えておくと使い分けやすい。
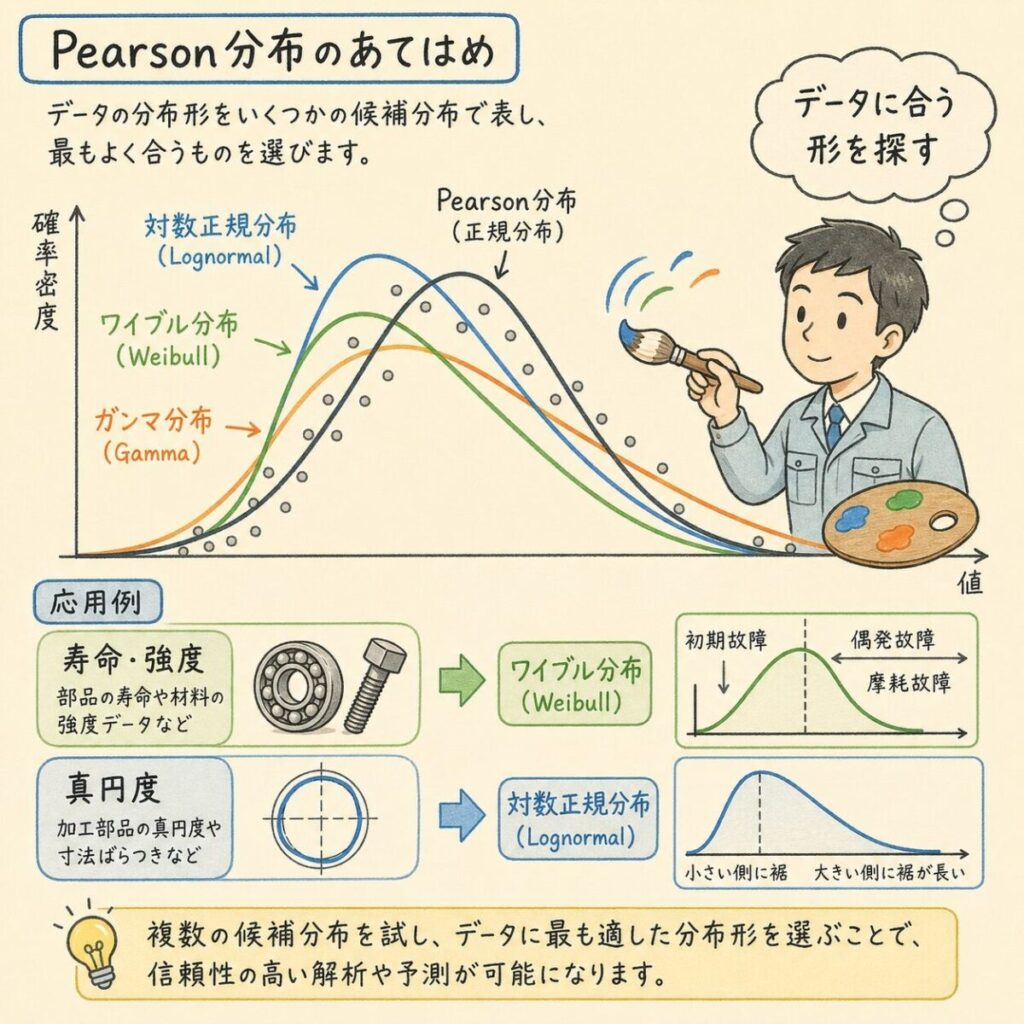
対処法3|Pearson系分布をフィッティング
データに合った非正規分布(ワイブル分布、対数正規分布、ガンマ分布など)を当てはめて、その分布のパラメータからCpkを計算する方法です。やや高度ですが、信頼性工学などで使われます。
| 分布 | 適用例 | 特徴 |
|---|---|---|
| 対数正規分布 | 真円度・濃度・反応時間 | 右に裾を引く形を素直に表現 |
| ワイブル分布 | 寿命・破壊強度 | 信頼性工学で頻出 |
| ガンマ分布 | 待ち時間・摩耗量 | 非負データで右に裾 |
| 指数分布 | 故障間隔 | 単純だが裾が長い |
分布をフィッティングすると、その分布で「規格を超える確率」を計算できます。これをCpkに換算すれば、実態に近い工程能力指数が得られます。
- 真円度・粗さ・濃度など → 対数正規分布を試す
- 寿命・強度データ → ワイブル分布を試す
- 分布の見当がつかない → Box-Cox変換に戻る
【図解】ワイブル分布とは?|形状パラメータmで故障パターンを見抜く →
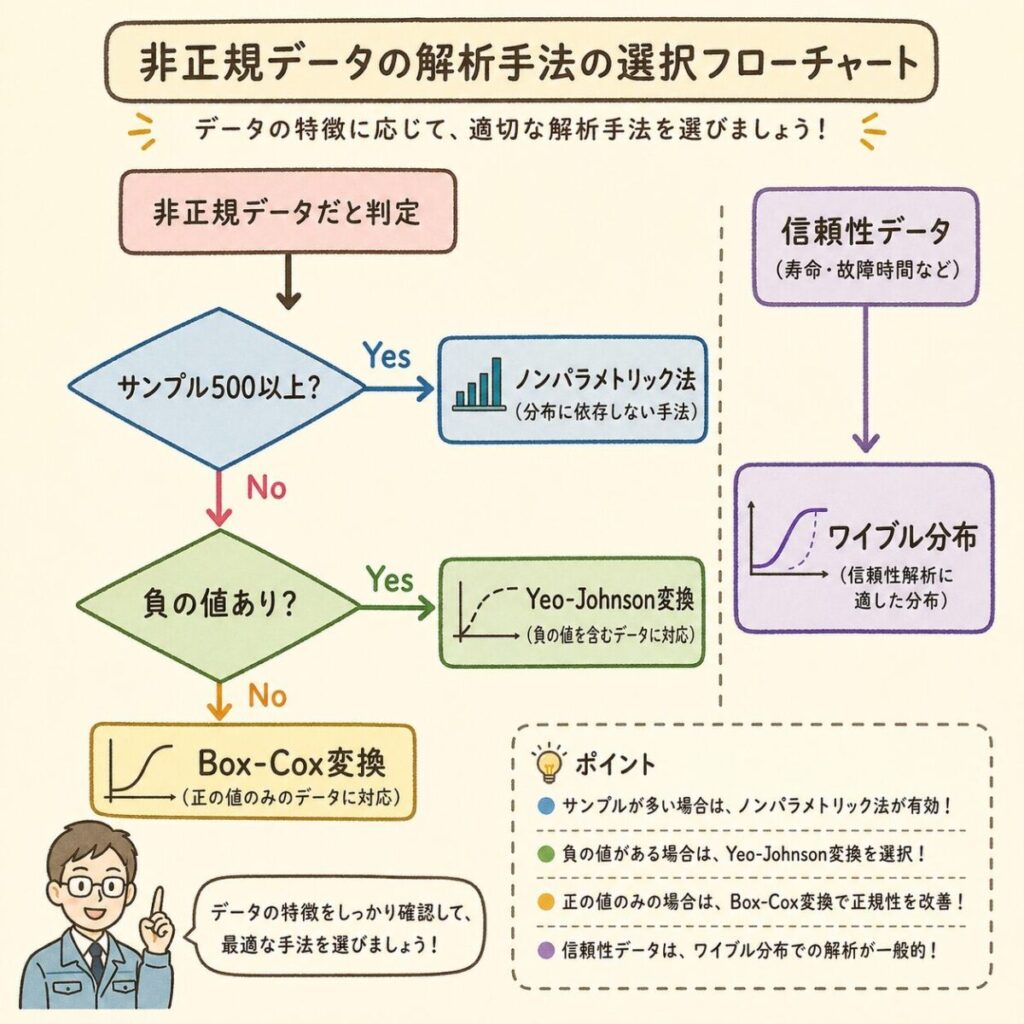
3つの対処法の使い分けフローチャート
最後に、3つの対処法のどれを使うかを判断するフローチャートをまとめました。
サンプル数は500個以上ありますか?
YES → ノンパラメトリック法も検討可
NO → 変換 or 分布フィッティング
データは負の値を取りますか?
YES → Box-Cox不可、Yeo-Johnson変換 or ノンパラ法
NO → Box-Cox変換が第一候補
データの種類は分かっていますか?
寿命・強度 → ワイブル分布
濃度・真円度 → 対数正規分布
不明 → Box-Cox変換
客先は何を要求していますか?
通常はBox-Cox変換でOK。客先指定があればその方法で。
自動車(IATF16949)はAIAG SPCマニュアル準拠が一般的。
どの方法を使っても、計算根拠を必ず明記すること。「Cpk = 1.5」とだけ書くのではなく、「Box-Cox変換(λ=0.5)後のCpk = 1.5」のように、変換手法・パラメータをセットで記載するのが実務の鉄則です。
まとめ|「正規分布だから使える」を客先に説明できる人になる
- Cpkは正規分布前提。3σ理論を使って不良率(ppm)に換算している
- 非正規データに無理やりCpkを使うと、計算値と実際の不良率がズレる(過大評価が多い)
- 非正規パターン4つ:歪度大/尖度異常/二山/切断
- 判定は「ヒストグラム+確率プロット+検定」3点セットで総合判断
- 対処法1:Box-Cox変換(万能・最も普及)
- 対処法2:ノンパラメトリック法(量産で大量データ向け)
- 対処法3:Pearson系分布フィッティング(信頼性工学・専門的)
- 共通ルール:変換手法・パラメータを必ず明記すること
工程能力指数Cpkを「正規分布じゃないけど使えますか?」と聞かれたとき、「使えます。Box-Cox変換でλ=0.5にして計算しています」と即答できれば、客先や上司から信頼されるエンジニアの仲間入りです。
📚 次に読むべき記事
本記事の前提となるCpk-ppm換算をマスターする。
Cpkの定義式と計算手順をしっかり押さえる。
非正規分布の判定で必ず使う2つの指標を完全マスター。
CpkとPpkの違いを理解して、客先資料で混同しないために。
Cpk値ごとの改善アクションをまとめた実務ガイド。
非正規判定の第一歩。ヒストグラムの読み方をしっかり学ぶ。
寿命・強度データの非正規対応で必ず使うワイブル分布。
そもそも「正規分布」とは何か?基礎から学び直したい方へ。
Cpk値が低い場合の改善実務手順をマスター。